
-
1. Démarrage rapide
-
2. Les bases de Git
-
3. Les branches avec Git
-
4. Git sur le serveur
- 4.1 Protocoles
- 4.2 Installation de Git sur un serveur
- 4.3 Génération des clés publiques SSH
- 4.4 Mise en place du serveur
- 4.5 Démon (Daemon) Git
- 4.6 HTTP intelligent
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Git hébergé
- 4.10 Résumé
-
5. Git distribué
-
6. GitHub
-
7. Utilitaires Git
- 7.1 Sélection des versions
- 7.2 Indexation interactive
- 7.3 Remisage et nettoyage
- 7.4 Signer votre travail
- 7.5 Recherche
- 7.6 Réécrire l’historique
- 7.7 Reset démystifié
- 7.8 Fusion avancée
- 7.9 Rerere
- 7.10 Déboguer avec Git
- 7.11 Sous-modules
- 7.12 Empaquetage (bundling)
- 7.13 Replace
- 7.14 Stockage des identifiants
- 7.15 Résumé
-
8. Personnalisation de Git
- 8.1 Configuration de Git
- 8.2 Attributs Git
- 8.3 Crochets Git
- 8.4 Exemple de politique gérée par Git
- 8.5 Résumé
-
9. Git et les autres systèmes
- 9.1 Git comme client
- 9.2 Migration vers Git
- 9.3 Résumé
-
10. Les tripes de Git
- 10.1 Plomberie et porcelaine
- 10.2 Les objets de Git
- 10.3 Références Git
- 10.4 Fichiers groupés
- 10.5 La refspec
- 10.6 Les protocoles de transfert
- 10.7 Maintenance et récupération de données
- 10.8 Les variables d’environnement
- 10.9 Résumé
-
A1. Annexe A: Git dans d’autres environnements
- A1.1 Interfaces graphiques
- A1.2 Git dans Visual Studio
- A1.3 Git dans Visual Studio Code
- A1.4 Git dans IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git dans Sublime Text
- A1.6 Git dans Bash
- A1.7 Git dans Zsh
- A1.8 Git dans PowerShell
- A1.9 Résumé
-
A2. Annexe B: Embarquer Git dans vos applications
- A2.1 Git en ligne de commande
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Commandes Git
- A3.1 Installation et configuration
- A3.2 Obtention et création des projets
- A3.3 Capture d’instantané basique
- A3.4 Création de branches et fusion
- A3.5 Partage et mise à jour de projets
- A3.6 Inspection et comparaison
- A3.7 Débogage
- A3.8 Patchs
- A3.9 Courriel
- A3.10 Systèmes externes
- A3.11 Administration
- A3.12 Commandes de plomberie
7.7 Utilitaires Git - Reset démystifié
Reset démystifié
Avant d’aborder des outils plus spécialisés, parlons un instant de reset et checkout.
Ces commandes sont deux des plus grandes sources de confusion à leur premier contact.
Elles permettent de faire tant de choses et il semble impossible de les comprendre et les employer correctement.
Pour ceci, nous vous recommandons une simple métaphore.
Les trois arbres
Le moyen le plus simple de penser à reset et checkout consiste à représenter Git comme un gestionnaire de contenu de trois arborescences différentes.
Par « arborescence », il faut comprendre « collection de fichiers », pas spécifiquement structure de données.
Il existe quelques cas pour lesquels l’index ne se comporte pas exactement comme une arborescence, mais pour ce qui nous concerne, c’est plus simple de l’imaginer de cette manière pour le moment.
Git, comme système, gère et manipule trois arbres au cours de son opération normale :
| Arbre | Rôle |
|---|---|
HEAD |
instantané de la dernière validation, prochain parent |
Index |
instantané proposé de la prochaine validation |
Répertoire de travail |
bac à sable |
HEAD
HEAD est un pointeur sur la référence de la branche actuelle, qui est à son tour un pointeur sur le dernier commit réalisé sur cette branche. Ceci signifie que HEAD sera le parent du prochain commit à créer. C’est généralement plus simple de penser HEAD comme l’instantané de votre dernière validation.
En fait, c’est assez simple de visualiser ce à quoi cet instantané ressemble. Voici un exemple de liste du répertoire et des sommes de contrôle SHA-1 pour chaque fichier de l’instantané HEAD :
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
initial commit
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... libLes commandes cat-file et ls-tree sont des commandes de « plomberie » qui sont utilisées pour des activités de bas niveau et ne sont pas réellement utilisées pour le travail quotidien, mais elles nous permettent de voir ce qui se passe ici.
L’index
L’index est votre prochain commit proposé.
Nous avons aussi fait référence à ce concept comme la « zone de préparation » de Git du fait que c’est ce que Git examine lorsque vous lancez git commit.
Git remplit cet index avec une liste de tous les contenus des fichiers qui ont été extraits dans votre copie de travail et ce qu’ils contenaient quand ils ont été originellement extraits.
Vous pouvez alors remplacer certains de ces fichiers par de nouvelles versions de ces mêmes fichiers, puis git commit convertit cela en arborescence du nouveau commit.
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rbEncore une fois, nous utilisons ici ls-files qui est plus une commande de coulisses qui vous montre l’état actuel de votre index.
L’index n’est pas techniquement parlant une structure arborescente ‑ c’est en fait un manifeste aplati ‑ mais pour nos besoins, c’est suffisamment proche.
Le répertoire de travail
Finalement, vous avez votre répertoire de travail.
Les deux autres arbres stockent leur contenu de manière efficace mais peu pratique dans le répertoire .git.
Le répertoire de travail les dépaquette comme fichiers réels, ce qui rend tout de même plus facile leur modification.
Il faut penser à la copie de travail comme un bac à sable où vous pouvez essayer vos modifications avant de les transférer dans votre index puis le valider dans votre historique.
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 filesLe flux de travail
L’objet principal de Git est d’enregistrer des instantanés de votre projet comme des états successifs évolutifs en manipulant ces trois arbres.
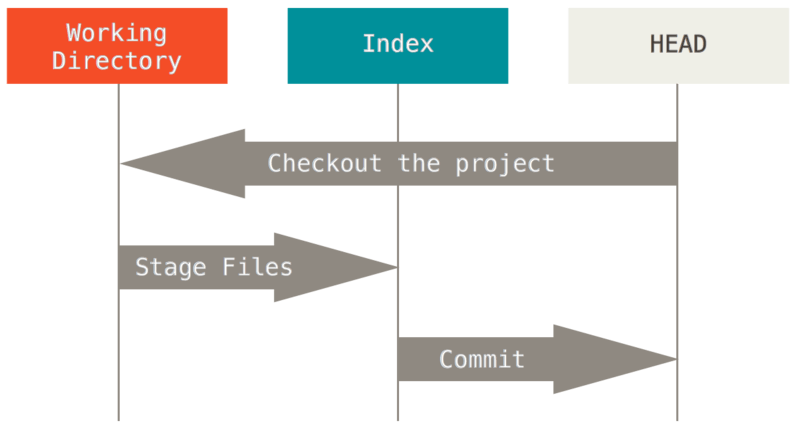
Visualisons ce processus : supposons que vous allez dans un nouveau répertoire contenant un fichier unique.
Nous appellerons ceci v1 du fichier et nous le marquerons en bleu.
Maintenant, nous allons lancer git init, ce qui va créer le dépôt Git avec une référence HEAD qui pointe sur une branche à naître (master n’existe pas encore).
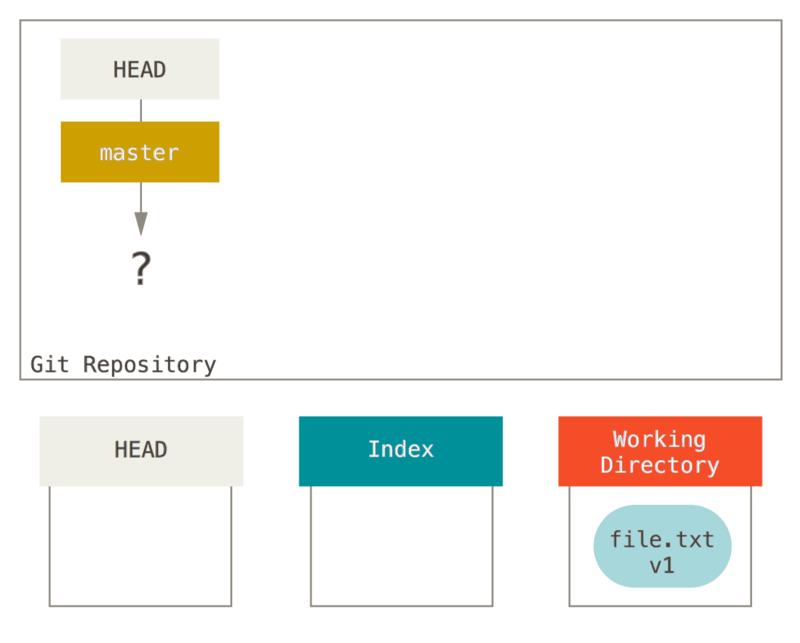
À ce point, seul le répertoire de travail contient quelque chose.
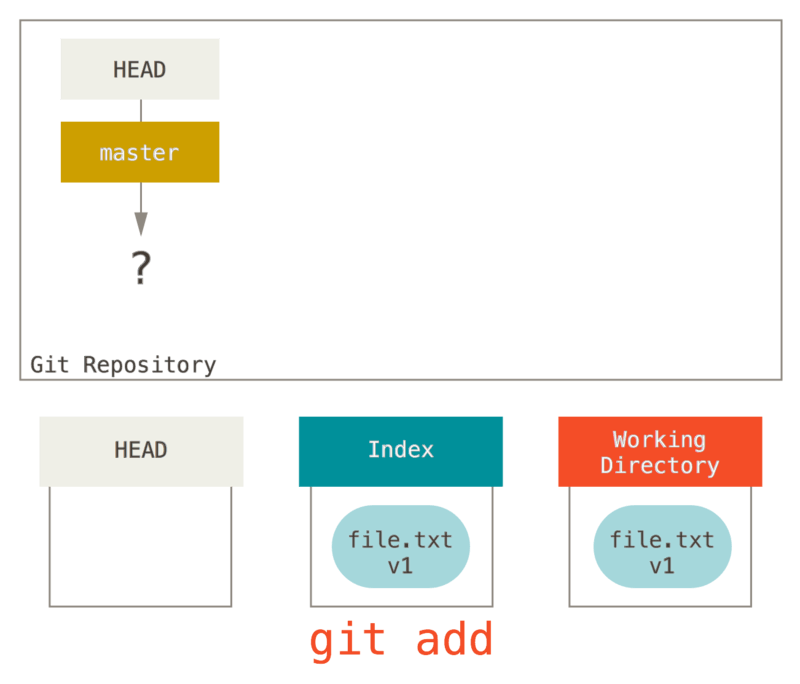
Maintenant, nous souhaitons valider ce fichier, donc nous utilisons git add qui prend le contenu du répertoire de travail et le copie dans l’index.
Ensuite, nous lançons git commit, ce qui prend le contenu de l’index et le sauve comme un instantané permanent, crée un objet commit qui pointe sur cet instantané et met à jour master pour pointer sur ce commit.
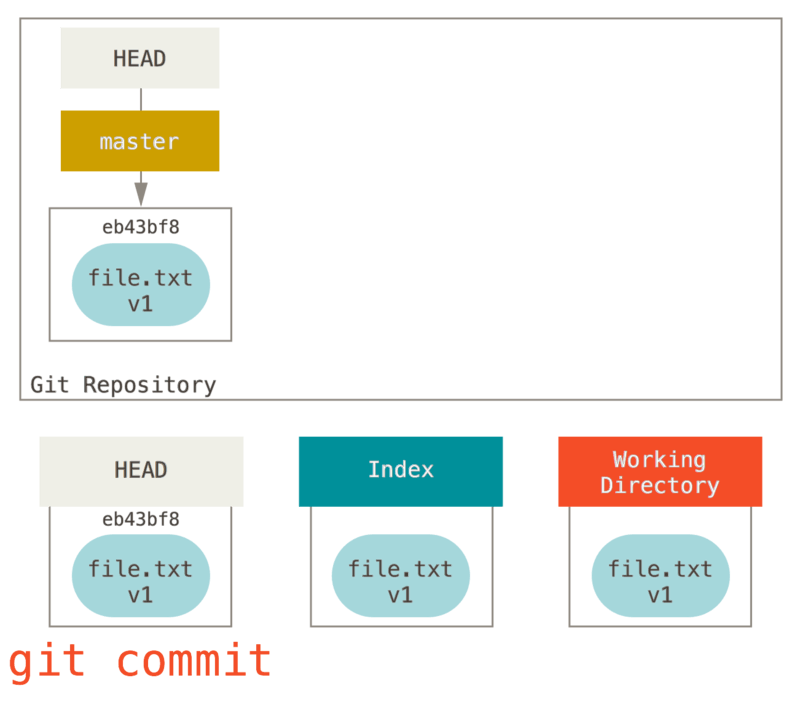
Si nous lançons git status, nous ne verrons aucune modification parce que les trois arborescences sont identiques.
Maintenant, nous voulons faire des modifications sur ce fichier et le valider. Nous suivons le même processus ; en premier nous changeons le fichier dans notre copie de travail. Appelons cette version du fichier v2 et marquons-le en rouge.
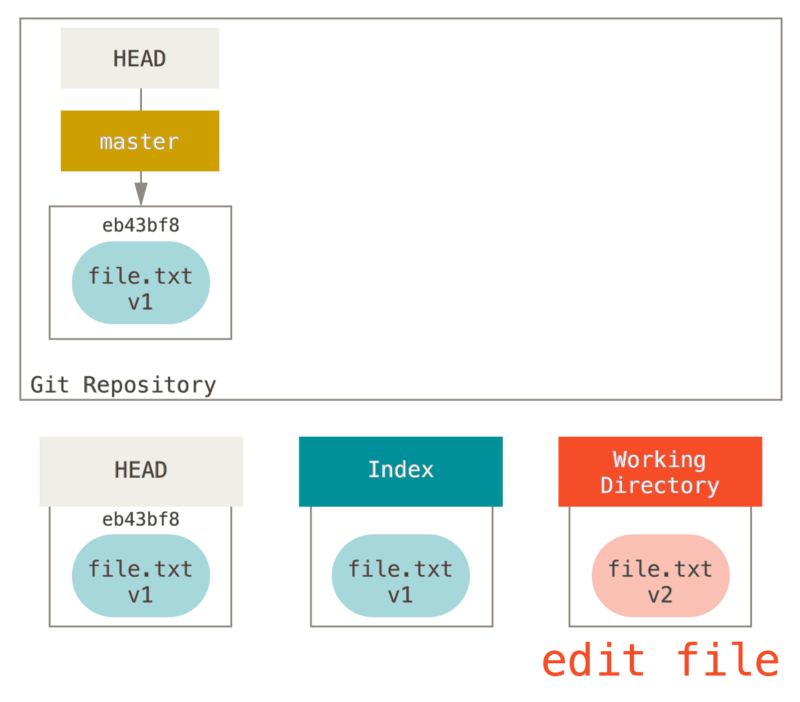
Si nous lançons git status maintenant, nous verrons le fichier en rouge comme « Modifications qui ne seront pas validées » car cette entrée est différente entre l’index et le répertoire de travail.
Ensuite, nous lançons git add dessus pour le monter dans notre index.
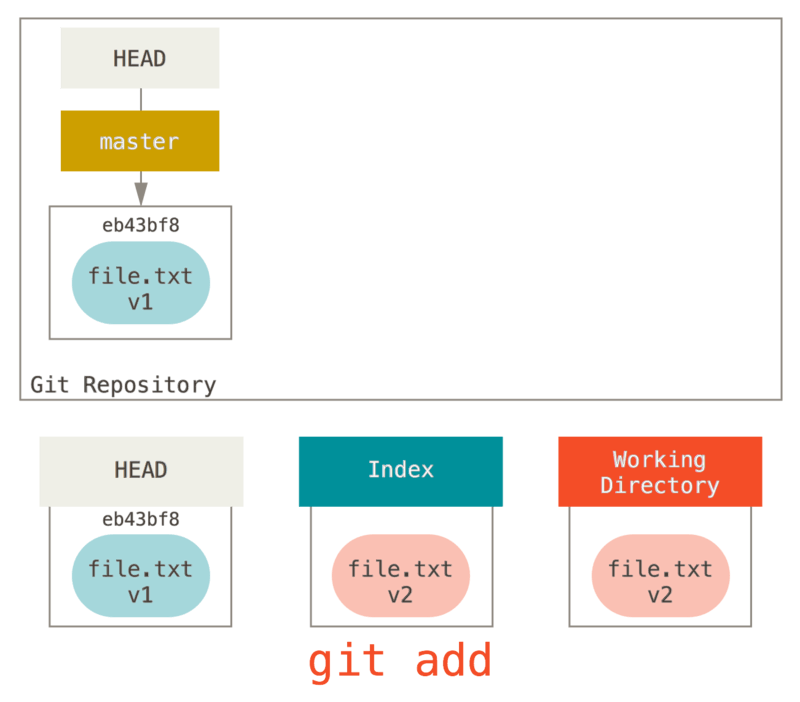
À ce point, si nous lançons git status, nous verrons le fichier en vert sous « Modifications qui seront validées » parce que l’index et HEAD diffèrent, c’est-à-dire que notre prochain commit proposé est différent de notre dernier commit.
Finalement, nous lançons git commit pour finaliser la validation.
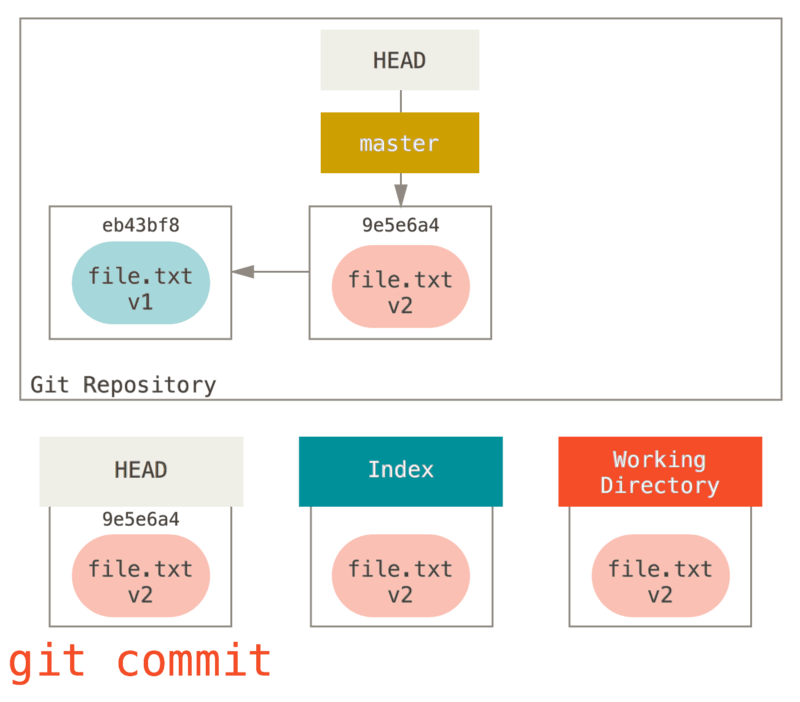
Maintenant, git status n’indique plus rien, car les trois arborescences sont à nouveau identiques.
Les basculements de branches ou les clonages déroulent le même processus. Quand vous extrayez une branche, cela change HEAD pour pointer sur la nouvelle référence de branche, alimente votre index avec l’instantané de ce commit, puis copie le contenu de l’index dans votre répertoire de travail.
Le rôle de reset
La commande reset est plus compréhensible dans ce contexte.
Pour l’objectif des exemples à suivre, supposons que nous avons modifié file.txt à nouveau et validé une troisième fois.
Donc maintenant, notre historique ressemble à ceci :
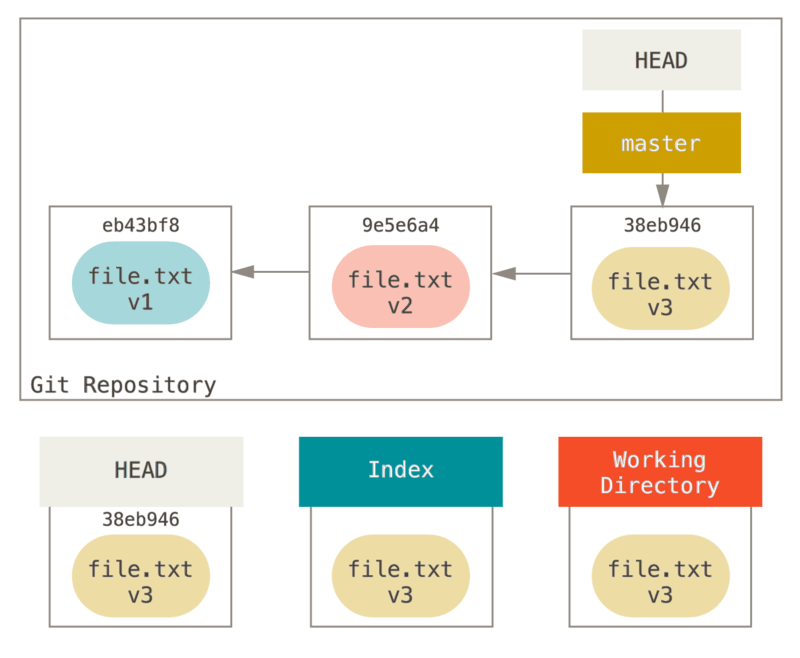
Détaillons maintenant ce que reset fait lorsque vous l’appelez.
Il manipule directement les trois arborescences d’une manière simple et prédictible.
Il réalise jusqu’à trois opérations basiques.
Étape 1: déplacer HEAD
La première chose que reset va faire consiste à déplacer ce qui est pointé par HEAD.
Ce n’est pas la même chose que changer HEAD lui-même (ce que fait checkout).
reset déplace la branche que HEAD pointe.
Ceci signifie que si HEAD est pointé sur la branche master (par exemple, si vous êtes sur la branche master), lancer git reset 9e5e6a4 va commencer par faire pointer master sur 9e5e6a4.
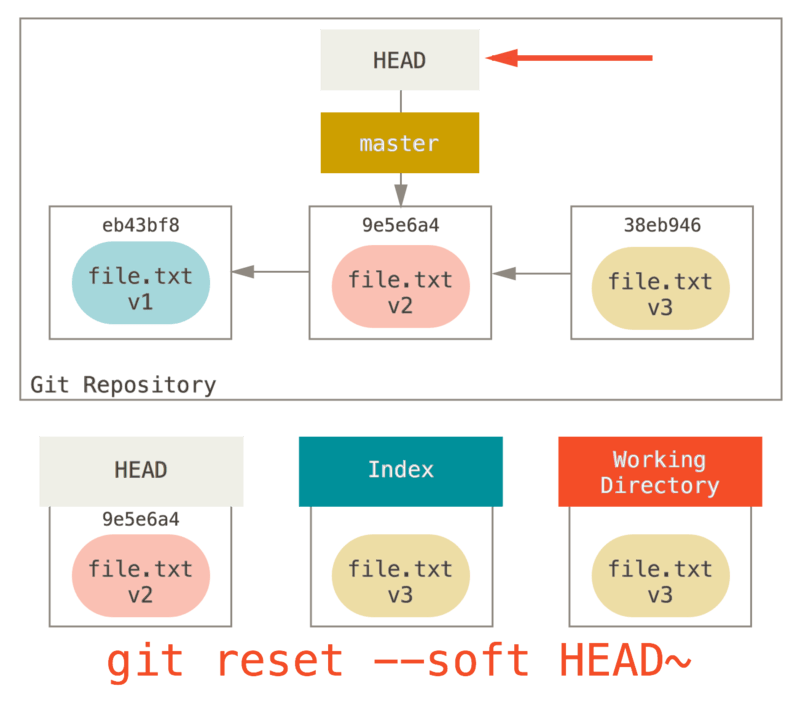
Quelle que soit la forme du reset que vous invoquez pour un commit, ce sera toujours la première chose qu’il tentera de faire.
Avec reset --soft, il n’ira pas plus loin.
Maintenant, arrêtez-vous une seconde et regardez le diagramme ci-dessus pour comprendre ce qu’il s’est passé : en essence, il a défait ce que la dernière commande git commit a créé.
Quand vous lancez git commit, Git crée un nouvel objet commit et déplace la branche pointée par HEAD dessus.
Quand vous faites un reset sur HEAD~ (le parent de HEAD), vous replacez la branche où elle était, sans changer ni l’index ni la copie de travail.
Vous pourriez maintenant mettre à jour l’index et relancer git commit pour accomplir ce que git commit --amend aurait fait (voir Modifier la dernière validation).
Étape 2 : Mise à jour de l’index (--mixed)
Notez que si vous lancez git status maintenant, vous verrez en vert la différence entre l’index et le nouveau HEAD.
La chose suivante que reset réalise est de mettre à jour l’index avec le contenu de l’instantané pointé par HEAD.
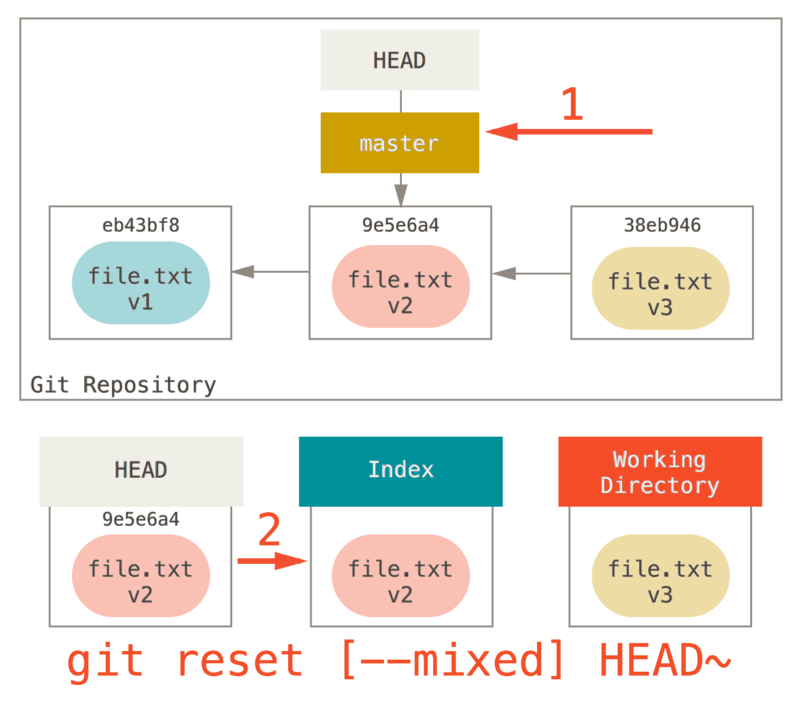
Si vous spécifiez l’option --mixed, reset s’arrêtera à cette étape.
C’est aussi le comportement par défaut, donc si vous ne spécifiez aucune option (juste git reset HEAD~ dans notre cas), c’est ici que la commande s’arrêtera.
Maintenant arrêtez-vous encore une seconde et regardez le diagramme ci-dessus pour comprendre ce qui s’est passé : il a toujours défait la dernière validation, mais il a aussi tout désindéxé.
Vous êtes revenu à l’état précédant vos commandes git add et git commit.
Étape 3: Mise à jour de la copie de travail (--hard)
La troisième chose que reset va faire est de faire correspondre la copie de travail avec l’index.
Si vous utilisez l’option --hard, il continuera avec cette étape.
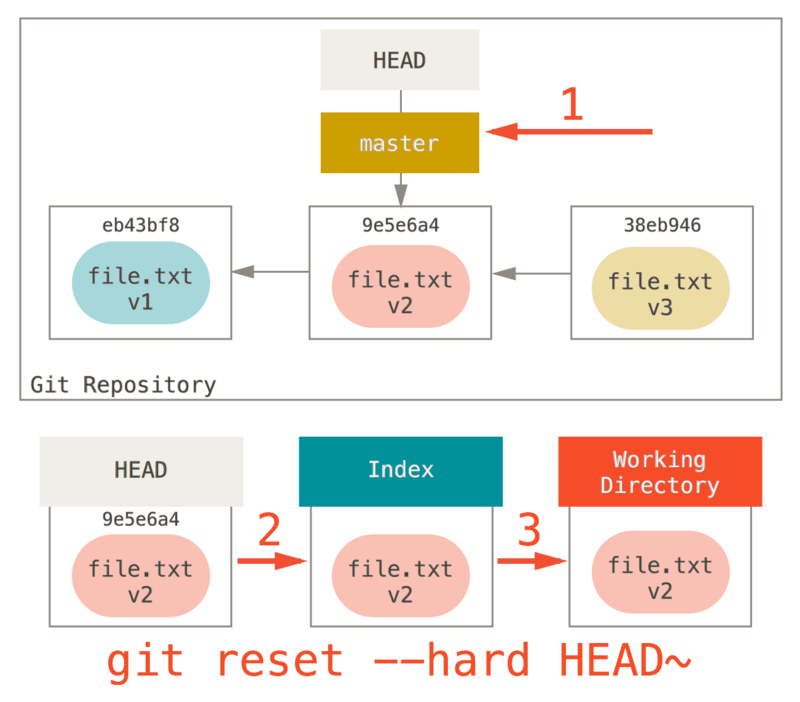
Donc réfléchissons à ce qui vient d’arriver.
Vous avez défait la dernière validation, les commandes git add et git commit ainsi que tout le travail que vous avez réalisé dans le répertoire de travail.
Il est important de noter que cette option (--hard) est le seul moyen de rendre la commande reset dangereuse et est un des très rares cas où Git va réellement détruire de la donnée.
Toute autre invocation de reset peut être défaite, mais l’option --hard ne le permet pas, car elle force l’écrasement des fichiers dans le répertoire de travail.
Dans ce cas particulier, nous avons toujours la version v3 du fichier dans un commit dans notre base de donnée Git, et nous pourrions la récupérer en parcourant notre reflog, mais si nous ne l’avions pas validé, Git aurait tout de même écrasé les fichiers et rien n’aurait pu être récupéré.
Récapitulatif
La commande reset remplace ces trois arbres dans un ordre spécifique, s’arrêtant lorsque vous lui indiquez :
-
Déplace la branche pointée par HEAD (s’arrête ici si
--soft) -
Fait ressembler l’index à HEAD (s’arrête ici à moins que
--hard) -
Fait ressembler le répertoire de travail à l’index.
Reset avec un chemin
Tout cela couvre le comportement de reset dans sa forme de base, mais vous pouvez aussi lui fournir un chemin sur lequel agir.
Si vous spécifiez un chemin, reset sautera la première étape et limitera la suite de ses actions à un fichier spécifique ou à un ensemble de fichiers.
Cela fait sens ; en fait, HEAD n’est rien de plus qu’un pointeur et vous ne pouvez pas pointer sur une partie d’un commit et une partie d’un autre.
Mais l’index et le répertoire de travail peuvent être partiellement mis à jour, donc reset continue avec les étapes 2 et 3.
Donc, supposons que vous lancez git reset file.txt.
Cette forme (puisque vous n’avez pas spécifié un SHA-1 de commit ni de branche, et que vous n’avez pas non plus spécifié --soft ou --hard) est un raccourci pour git reset --mixed HEAD file.txt, qui va :
-
déplacer la branche pointée par HEAD (sauté)
-
faire ressembler l’index à HEAD (s’arrête ici)
Donc, en substance, il ne fait que copier file.txt de HEAD vers index.
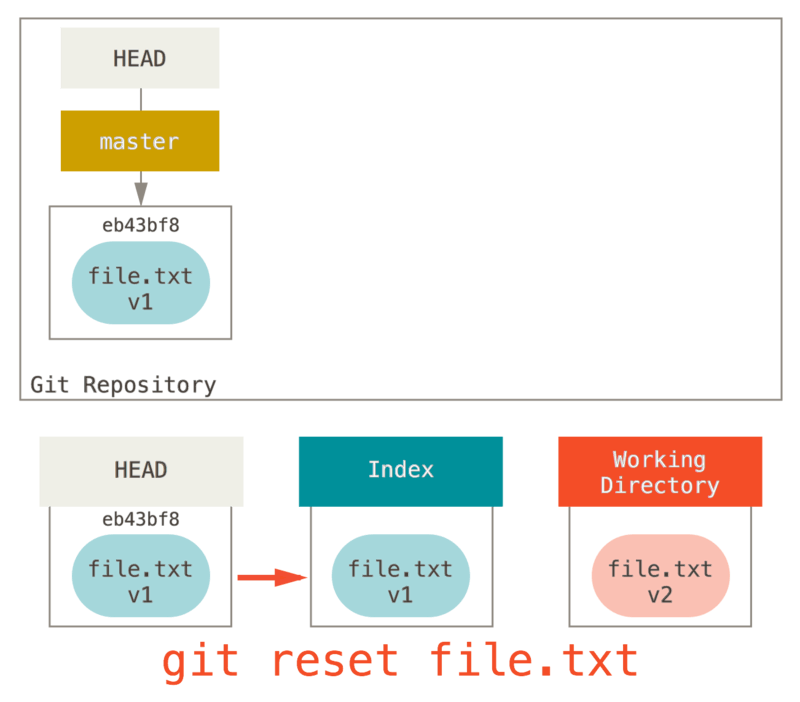
Ceci a l’effet pratique de désindexer le fichier.
Si on regarde cette commande dans le diagramme et qu’on pense à ce que git add fait, ce sont des opposés exacts.
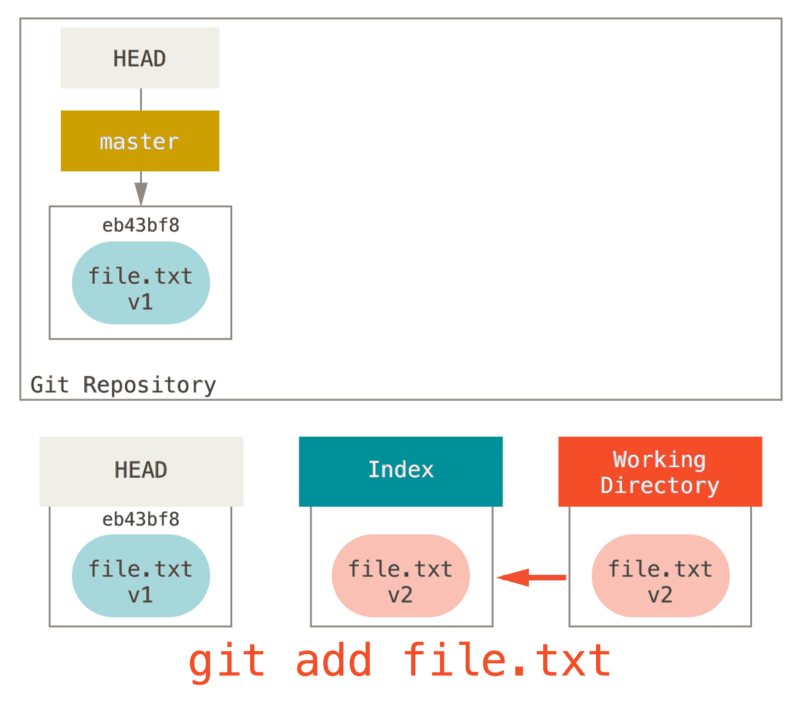
C’est pourquoi le résultat de la commande git status suggère que vous lanciez cette commande pour désindexer le fichier (voir Désindexer un fichier déjà indexé pour plus de détail).
Nous pourrions tout aussi bien ne pas laisser Git considérer que nous voulions dire « tirer les données depuis HEAD » en spécifiant un commit spécifique d’où tirer ce fichier.
Nous lancerions juste quelque chose comme git reset eb43bf file.txt.
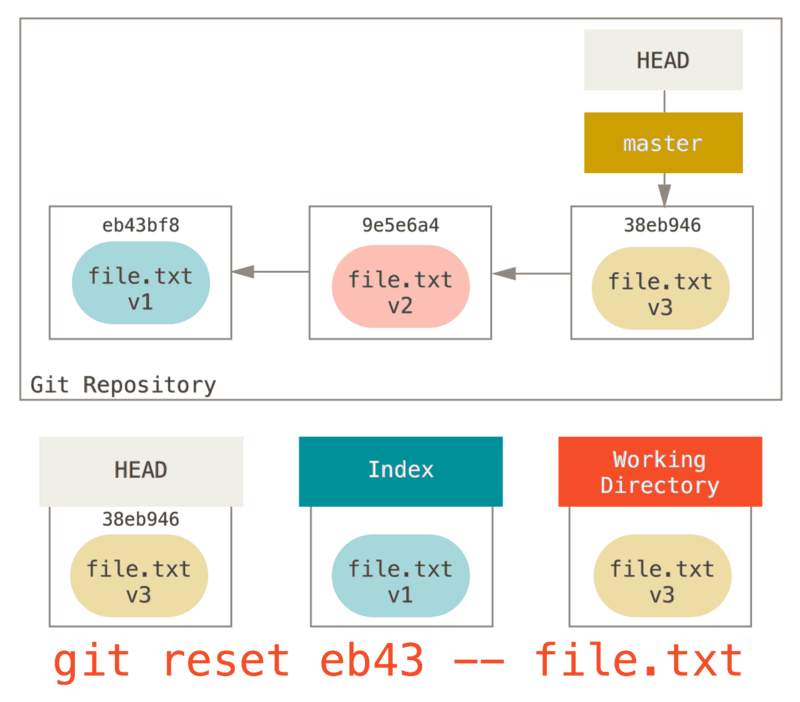
Ceci fait effectivement la même chose que si nous remettions le contenu du fichier à la v1 dans le répertoire de travail, lancions git add dessus, puis le ramenions à nouveau à la v3 (sans forcément passer par toutes ces étapes).
Si nous lançons git commit maintenant, il enregistrera la modification qui remet le fichier à la version v1, même si nous ne l’avons jamais eu à nouveau dans notre répertoire de travail.
Il est intéressant de noter que comme git add, la commande reset accepte une option --patch pour désindexer le contenu section par section.
Vous pouvez donc sélectivement désindexer ou ramener du contenu.
Écraser les commits
Voyons comment faire quelque chose d’intéressant avec ce tout nouveau pouvoir - écrasons des commits.
Supposons que vous avez une série de commits contenant des messages tels que « oups », « en chantier » ou « ajout d’un fichier manquant ».
Vous pouvez utiliser reset pour les écraser tous rapidement et facilement en une seule validation qui vous donne l’air vraiment intelligent (Écraser un commit explique un autre moyen de faire pareil, mais dans cet exemple, c’est plus simple de faire un reset).
Disons que vous avez un projet où le premier commit contient un fichier, le second commit a ajouté un nouveau fichier et a modifié le premier, et le troisième a remodifié le premier fichier. Le second commit était encore en chantier et vous souhaitez le faire disparaître.
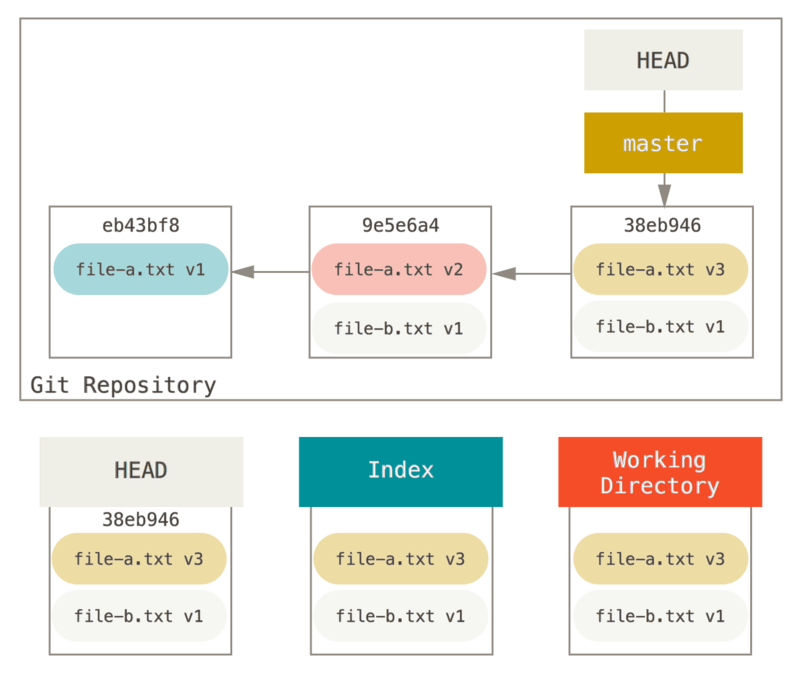
Vous pouvez lancer git reset --soft HEAD~2 pour ramener la branche de HEAD sur l’ancien commit (le premier commit que vous souhaitez garder) :
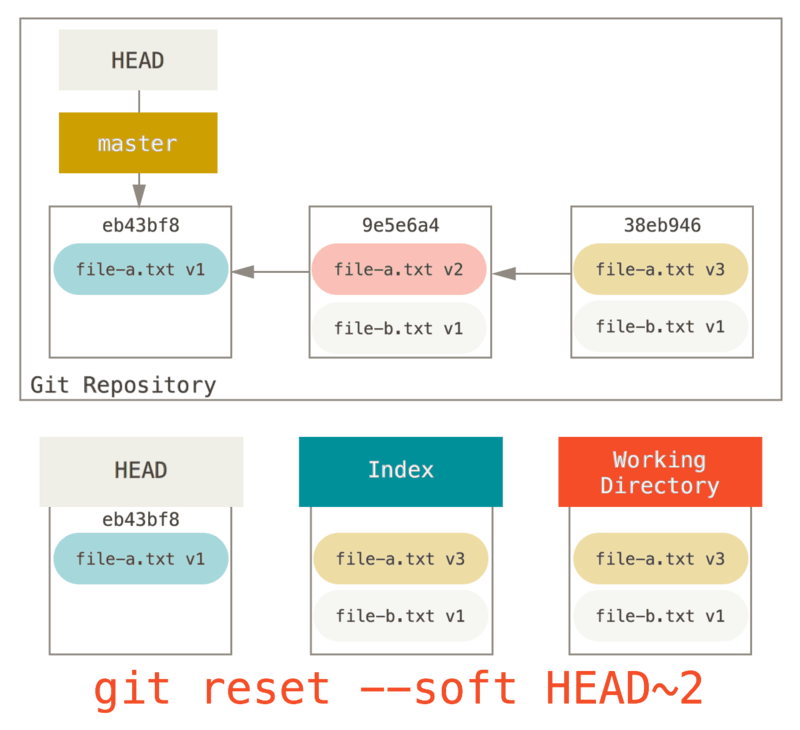
Ensuite, relancez simplement git commit :
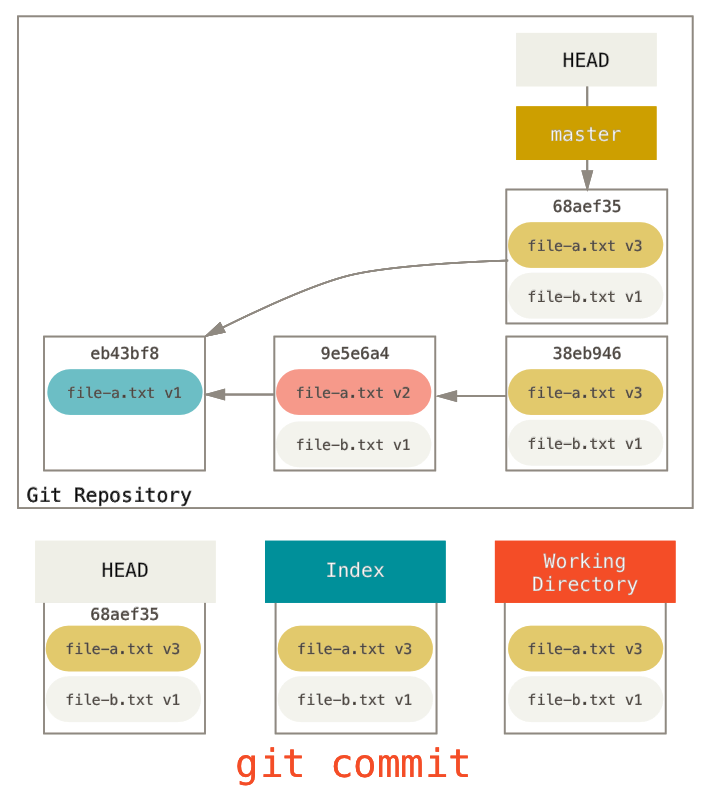
Maintenant vous pouvez voir que votre historique accessible, l’historique que vous pousseriez, ressemble à présent à un premier commit avec le fichier file-a.txt v1, puis un second qui modifie à la fois file-a.txt à la version 3 et ajoute file-b.txt.
Le commit avec la version v2 du fichier ne fait plus partie de l’historique.
Et checkout
Finalement, vous pourriez vous demander quelle différence il y a entre checkout et reset.
Comme reset, checkout manipule les trois arborescences et se comporte généralement différemment selon que vous indiquez un chemin vers un fichier ou non.
Sans chemin
Lancer git checkout [branche] est assez similaire à lancer git reset --hard [branche] en ce qu’il met à jour les trois arborescences pour qu’elles ressemblent à [branche], mais avec deux différences majeures.
Premièrement, à la différence de reset --hard, checkout préserve le répertoire de travail ; il s’assure de ne pas casser des fichiers qui ont changé.
En fait, il est même un peu plus intelligent que ça – il essaie de faire une fusion simple dans le répertoire de travail, de façon que tous les fichiers non modifiés soient mis à jour.
reset --hard, par contre, va simplement tout remplacer unilatéralement sans rien vérifier.
La seconde différence majeure concerne sa manière de mettre à jour HEAD.
Là où reset va déplacer la branche pointée par HEAD, checkout va déplacer HEAD lui-même pour qu’il pointe sur une autre branche.
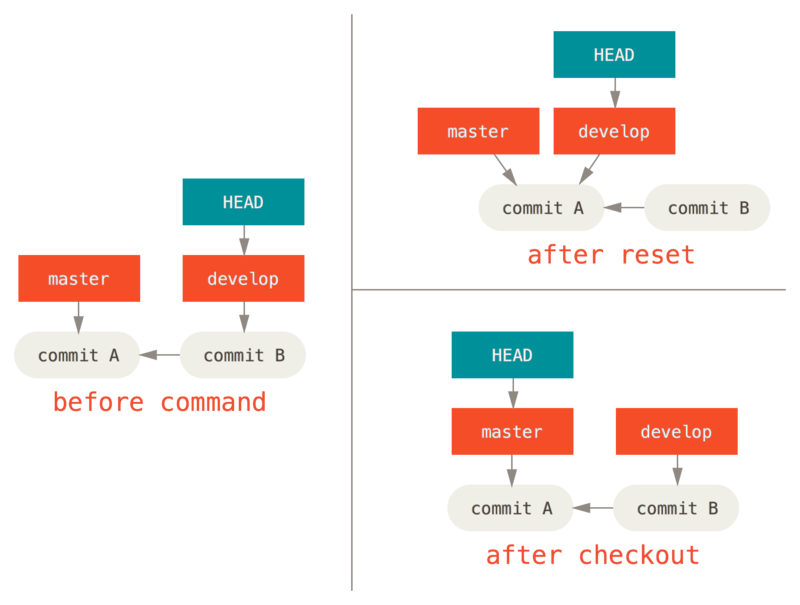
Par exemple, supposons que nous avons des branches master et develop qui pointent sur des commits différents et que nous sommes actuellement sur develop (donc HEAD pointe dessus).
Si nous lançons git reset master, develop lui-même pointera sur le même commit que master.
Si nous lançons plutôt git checkout master, develop ne va pas bouger, seul HEAD va changer.
HEAD pointera alors sur master.
Donc, dans les deux cas, nous déplaçons HEAD pour pointer sur le commit A, mais la manière diffère beaucoup.
reset va déplacer la branche pointée par HEAD, alors que checkout va déplacer HEAD lui-même.
Avec des chemins
L’autre façon de lancer checkout est avec un chemin de fichier, ce qui, comme reset, ne déplace pas HEAD.
Cela correspond juste à git reset [branche] fichier car cela met à jour l’index avec ce fichier à ce commit, mais en remplaçant le fichier dans le répertoire de travail.
Ce serait exactement comme git reset --hard [branche] fichier (si reset le permettait) – cela ne préserve pas le répertoire de travail et ne déplace pas non plus HEAD.
De même que git reset et git add, checkout accepte une option --patch permettant de réinitialiser sélectivement le contenu d’un fichier section par section.
Résumé
J’espère qu’à présent vous comprenez mieux et vous sentez plus à l’aise avec la commande reset, même si vous pouvez vous sentir encore un peu confus sur ce qui la différencie exactement de checkout et avoir du mal à vous souvenir de toutes les règles de ses différentes invocations.
Voici un aide-mémoire sur ce que chaque commande affecte dans chaque arborescence. La colonne « HEAD » contient « RÉF » si cette commande déplace la référence (branche) pointée par HEAD, et « HEAD » si elle déplace HEAD lui-même. Faites particulièrement attention à la colonne « préserve RT ? » (préserve le répertoire de travail) – si elle indique NON, réfléchissez à deux fois avant de lancer la commande.
| HEAD | Index | Rép. Travail | préserve RT ? | |
|---|---|---|---|---|
Niveau commit |
||||
|
RÉF |
NON |
NON |
OUI |
|
RÉF |
OUI |
NON |
OUI |
|
RÉF |
OUI |
OUI |
NON |
|
HEAD |
OUI |
OUI |
OUI |
Niveau Fichier |
||||
|
NON |
OUI |
NON |
OUI |
|
NON |
OUI |
OUI |
NON |