
-
1. Inicio - Sobre el Control de Versiones
-
2. Fundamentos de Git
-
3. Ramificaciones en Git
-
4. Git en el Servidor
- 4.1 Los Protocolos
- 4.2 Configurando Git en un servidor
- 4.3 Generando tu clave pública SSH
- 4.4 Configurando el servidor
- 4.5 El demonio Git
- 4.6 HTTP Inteligente
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Git en un alojamiento externo
- 4.10 Resumen
-
5. Git en entornos distribuidos
-
6. GitHub
-
7. Herramientas de Git
- 7.1 Revisión por selección
- 7.2 Organización interactiva
- 7.3 Guardado rápido y Limpieza
- 7.4 Firmando tu trabajo
- 7.5 Buscando
- 7.6 Reescribiendo la Historia
- 7.7 Reiniciar Desmitificado
- 7.8 Fusión Avanzada
- 7.9 Rerere
- 7.10 Haciendo debug con Git
- 7.11 Submódulos
- 7.12 Agrupaciones
- 7.13 Replace
- 7.14 Almacenamiento de credenciales
- 7.15 Resumen
-
8. Personalización de Git
-
9. Git y Otros Sistemas
- 9.1 Git como Cliente
- 9.2 Migración a Git
- 9.3 Resumen
-
10. Los entresijos internos de Git
-
A1. Apéndice A: Git en otros entornos
- A1.1 Interfaces gráficas
- A1.2 Git en Visual Studio
- A1.3 Git en Eclipse
- A1.4 Git con Bash
- A1.5 Git en Zsh
- A1.6 Git en Powershell
- A1.7 Resumen
-
A2. Apéndice B: Integrando Git en tus Aplicaciones
- A2.1 Git mediante Línea de Comandos
- A2.2 Libgit2
- A2.3 JGit
-
A3. Apéndice C: Comandos de Git
- A3.1 Configuración
- A3.2 Obtener y Crear Proyectos
- A3.3 Seguimiento Básico
- A3.4 Ramificar y Fusionar
- A3.5 Compartir y Actualizar Proyectos
- A3.6 Inspección y Comparación
- A3.7 Depuración
- A3.8 Parcheo
- A3.9 Correo Electrónico
- A3.10 Sistemas Externos
- A3.11 Administración
- A3.12 Comandos de Fontanería
7.7 Herramientas de Git - Reiniciar Desmitificado
Reiniciar Desmitificado
Antes de pasar a herramientas más especializadas, hablemos de reset y checkout.
Estos comandos son dos de las partes más confusas de Git cuando los encuentras por primera vez. Hacen tantas cosas, que parece imposible comprenderlas realmente y emplearlas adecuadamente.
Para esto, recomendamos una metáfora simple.
Los Tres Árboles
Una manera más fácil de pensar sobre reset y checkout es a través del marco mental de Git como administrador de contenido de tres árboles diferentes.
Por “árbol”, aquí realmente queremos decir “colección de archivos”, no específicamente la estructura de datos.
(Hay algunos casos donde el índice no funciona exactamente como un árbol, pero para nuestros propósitos es más fácil pensarlo de esta manera por ahora).
Git como sistema maneja y manipula tres árboles en su operación normal:
| Árbol | Rol |
|---|---|
HEAD |
Última instantánea del commit, próximo padre |
Índice |
Siguiente instantánea del commit propuesta |
Directorio de Trabajo |
Caja de Arena |
El HEAD
HEAD es el puntero a la referencia de bifurcación actual, que es, a su vez, un puntero al último commit realizado en esa rama. Eso significa que HEAD será el padre del próximo commit que se cree. En general, es más simple pensar en HEAD como la instantánea de tu último commit.
De hecho, es bastante fácil ver cómo es el aspecto de esa instantánea. Aquí hay un ejemplo de cómo obtener la lista del directorio real y las sumas de comprobación SHA-1 para cada archivo en la instantánea de HEAD:
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
commit inicial
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... libLos comandos cat-file y ls-tree son comandos de “fontanería” que se usan para cosas de nivel inferior y que no se usan realmente en el trabajo diario, pero nos ayudan a ver qué está sucediendo aquí.
El Índice
El índice es tu siguiente commit propuesto. También nos hemos estado refiriendo a este concepto como el “Área de Preparación” de Git ya que esto es lo que Git ve cuando ejecutas git commit.
Git rellena este índice con una lista de todos los contenidos del archivo que fueron revisados por última vez en tu directorio de trabajo y cómo se veían cuando fueron revisados originalmente.
A continuación, reemplaza algunos de esos archivos con nuevas versiones de ellos, y git commit los convierte en el árbol para un nuevo commit.
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rbNuevamente, aquí estamos usando ls-files, que es más un comando entre bastidores que te muestra a qué se parece actualmente el índice.
El índice no es técnicamente una estructura de árbol – en realidad se implementa como un manifiesto aplanado – pero para nuestros propósitos, está lo suficientemente cerca.
El Directorio de Trabajo
Finalmente, tienes tu directorio de trabajo.
Los otros dos árboles almacenan su contenido de manera eficiente pero inconveniente, dentro de la carpeta .git.
El Directorio de trabajo los descomprime en archivos reales, lo que hace que sea mucho más fácil para ti editarlos.
Piensa en el Directorio de Trabajo como una caja de arena, donde puedes probar los cambios antes de enviarlos a tu área de ensayo (índice) y luego al historial.
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 filesEl Flujo de Trabajo
El objetivo principal de Git es registrar instantáneas de tu proyecto en estados sucesivamente mejores, mediante la manipulación de estos tres árboles.
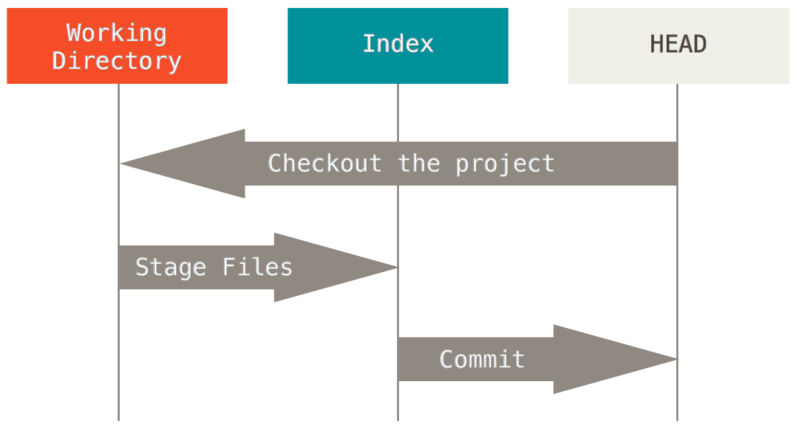
Visualicemos este proceso: digamos que ingresa en un nuevo directorio con un solo archivo.
Llamaremos a esto v1 del archivo, y lo indicaremos en azul.
Ahora ejecutamos git init, que creará un repositorio Git con una referencia HEAD que apunta a una rama no nacida (master aún no existe).
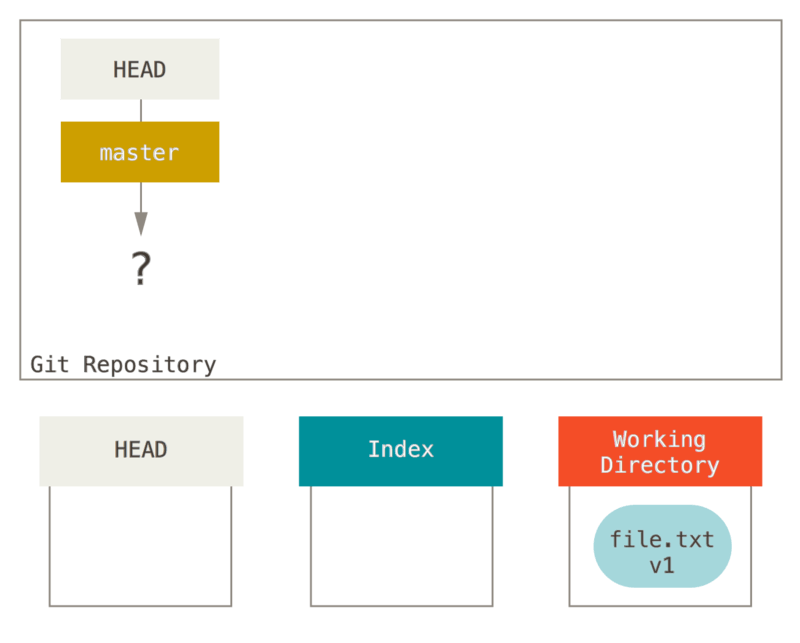
En este punto, solo el árbol del Directorio de Trabajo tiene cualquier contenido.
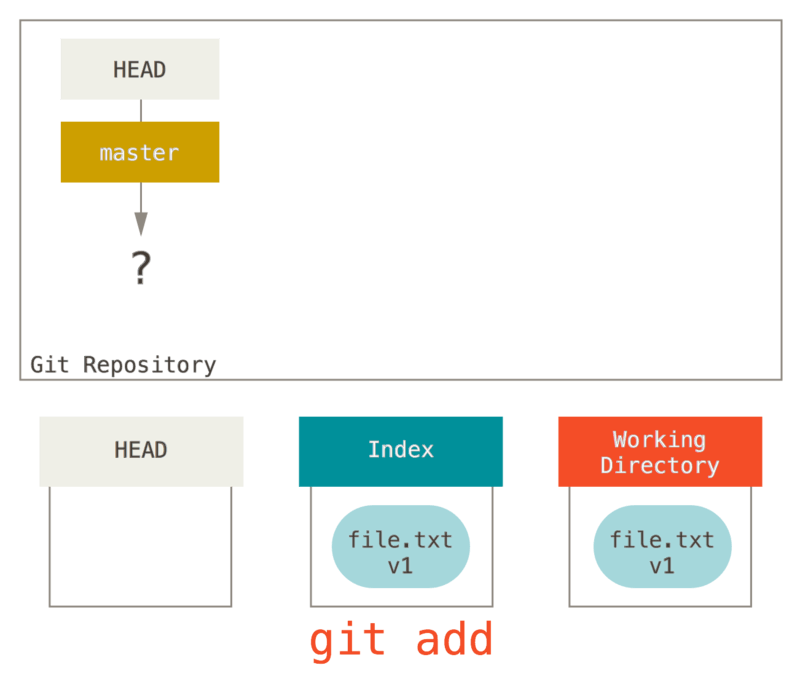
Ahora queremos hacer “commit” a este archivo, por lo que usamos git add para tomar contenido en el directorio de trabajo y copiarlo en el índice.
Luego ejecutamos git commit, que toma los contenidos del índice y los guarda como una instantánea permanente, crea un objeto de “commit” que apunta a esa instantánea y actualiza master para apuntar a ese “commit”.
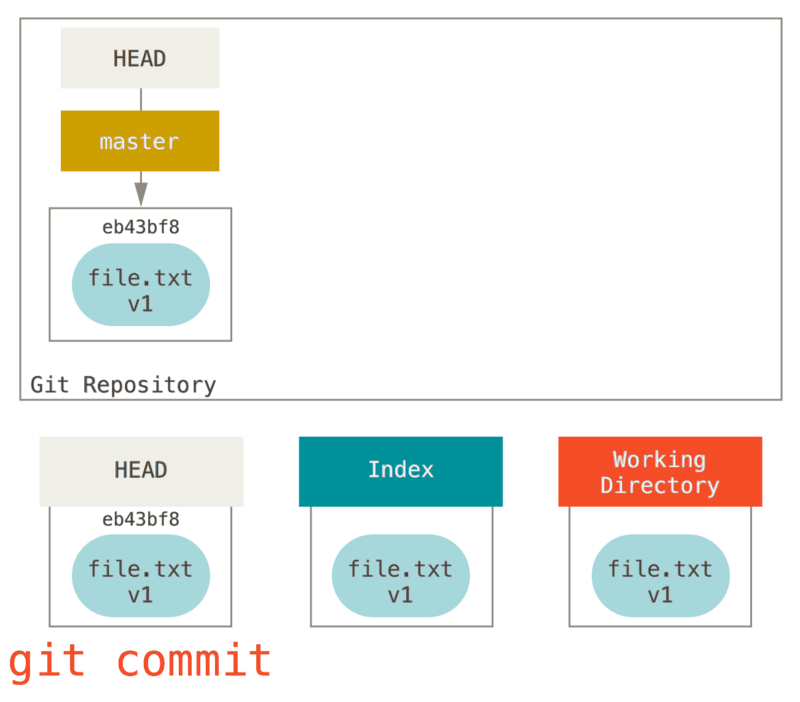
Si ejecutamos git status, no veremos ningún cambio, porque los tres árboles son iguales.
Ahora queremos hacer un cambio en ese archivo y hacerle un nuevo “commit”. Pasaremos por el mismo proceso; primero, cambiamos el archivo en nuestro directorio de trabajo. Llamemos a esto v2 del archivo, y lo indicamos en rojo.
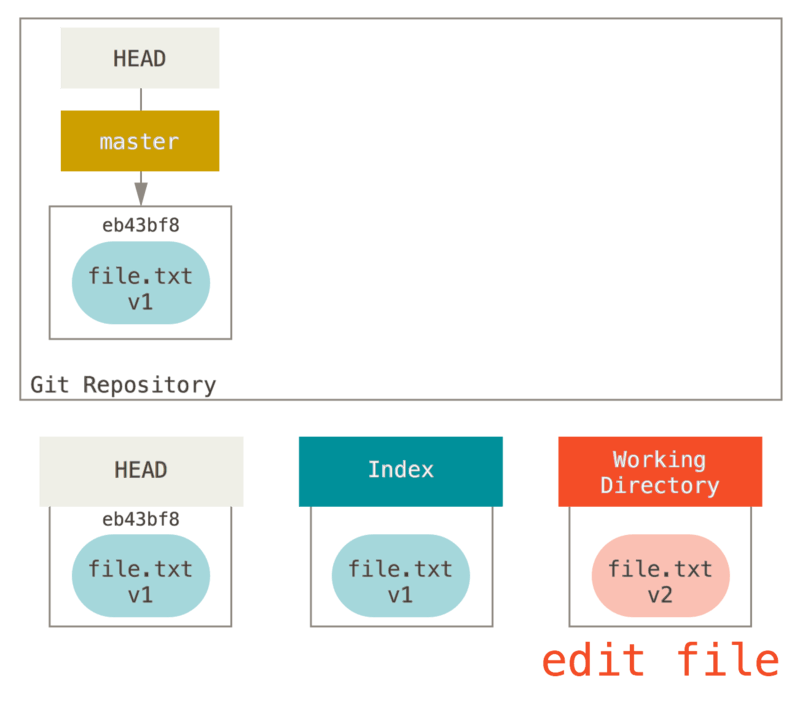
Si ejecutamos git status ahora, veremos el archivo en rojo como “Changes not staged for commit” porque esa entrada difiere entre el índice y el directorio de trabajo.
A continuación, ejecutamos git add para ubicarlo en nuestro índice.
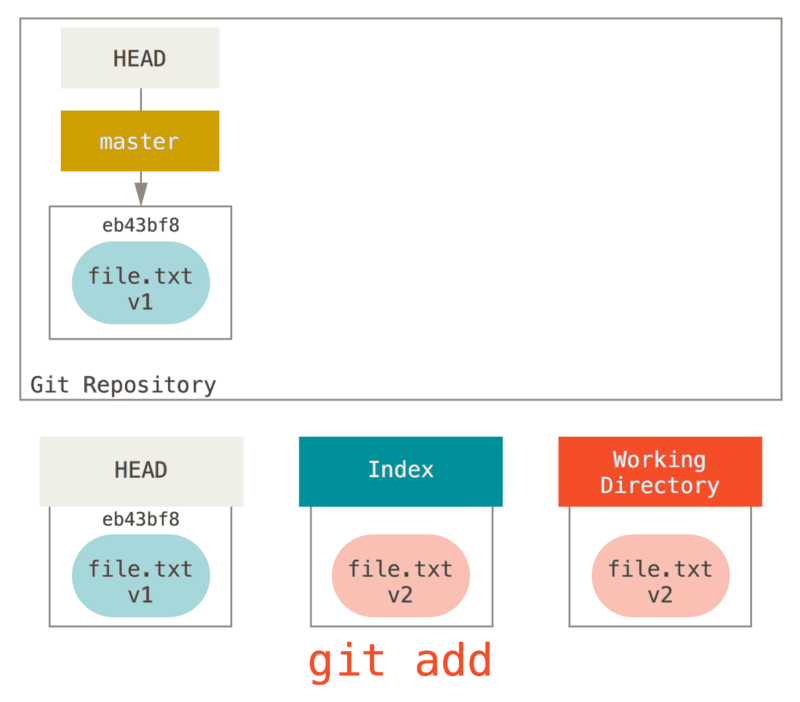
En este punto si ejecutamos git status veremos el archivo en verde
debajo de “Changes to be committed” porque el Índice y el HEAD difieren – es decir, nuestro siguiente “commit” propuesto ahora es diferente de nuestro último “commit”.
Finalmente, ejecutamos git commit para finalizar el “commit”.
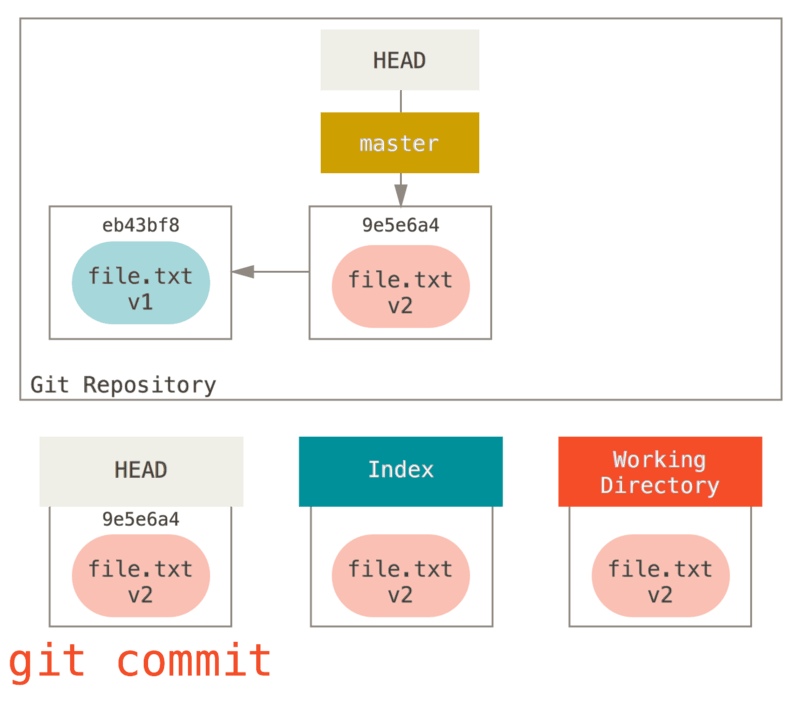
Ahora git status no nos dará salida, porque los tres árboles son iguales nuevamente.
El cambio de ramas o la clonación pasa por un proceso similar. Cuando verifica una rama, eso cambia HEAD para que apunte a la nueva “ref” de la rama, rellena su Índice con la instantánea de esa confirmación, luego copia los contenidos del Índice en tu Directorio de Trabajo.
El Papel del Reinicio
El comando reset tiene más sentido cuando se ve en este contexto.
A los fines de estos ejemplos, digamos que hemos modificado file.txt de nuevo y le hemos hecho “commit” por tercera vez. Entonces ahora nuestra historia se ve así:
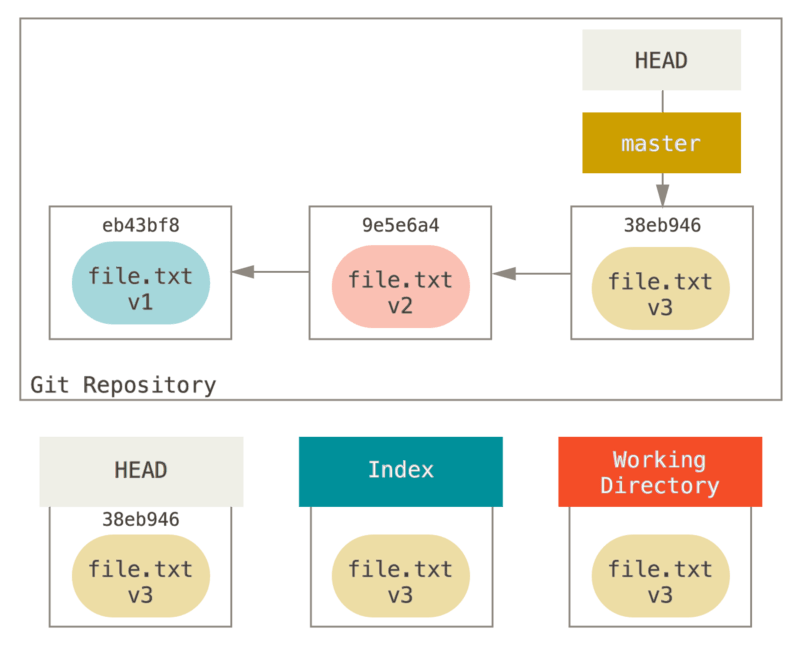
Hablemos ahora sobre lo que reset hace exactamente cuando es llamado. Manipula directamente estos tres árboles de una manera simple y predecible.
Hace hasta tres operaciones básicas.
Paso 1: mover HEAD
Lo primero que reset hará es mover a lo que HEAD apunta.
Esto no es lo mismo que cambiar HEAD en sí mismo (que es lo que hace checkout), reset mueve la rama a la que HEAD apunta.
Esto significa que si HEAD está configurado en la rama master (es decir, estás actualmente en la rama master), ejecutar git reset 9e5e64a comenzará haciendo que master apunte a 9e5e64a.
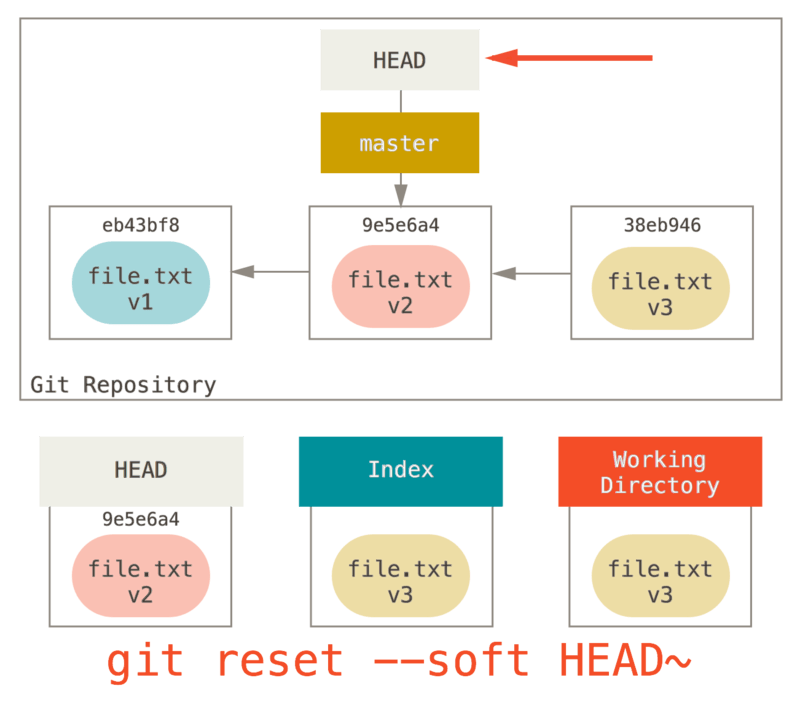
No importa qué forma de reset invoques con un ``commit, esto es lo primero que siempre intentará hacer.
Con reset --soft, simplemente se detendrá allí.
Ahora tómate un segundo para mirar ese diagrama y darte cuenta de lo que sucedió: esencialmente deshizo el último comando git commit.
Cuando ejecutas git commit, Git crea una nueva confirmación y mueve la rama a la que apunta HEAD.
Cuando haces reset de vuelta a HEAD~ (el padre de HEAD), está volviendo a colocar la rama donde estaba, sin cambiar el Índice o el Directorio de Trabajo.
Ahora puedes actualizar el Índice y ejecutar git commit nuevamente para lograr lo que git commit --amend hubiera hecho (ver Cambiando la última confirmación).
Paso 2: Actualizando el índice (--mixed)
Ten en cuenta que si ejecutas git status ahora, verás en verde la diferencia entre el Índice y lo que el nuevo HEAD es.
Lo siguiente que reset hará es actualizar el Índice con los contenidos de cualquier instantánea que HEAD señale ahora.
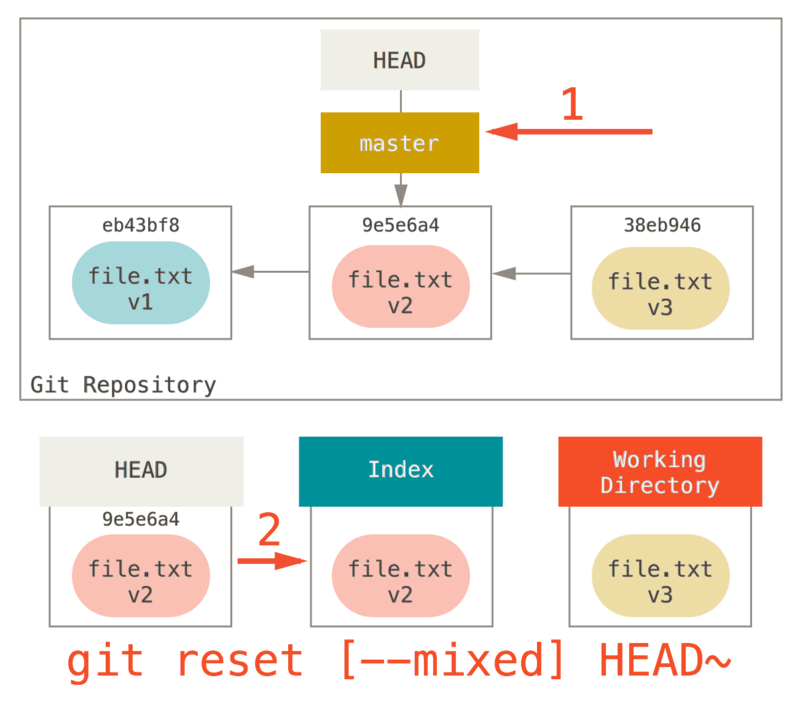
Si especificas la opción --mixed, reset se detendrá en este punto.
Este también es el comportamiento por defecto, por lo que si no especificas ninguna opción (sólo git reset HEAD~, en este caso), aquí es donde el comando se detendrá.
Ahora tómate otro segundo para mirar ese diagrama y darte cuenta de lo que sucedió: deshizo tu último commit y también hizo unstaged de todo.
Retrocedió a antes de ejecutar todos los comandos git add y git commit.
Paso 3: Actualizar el Directorio de Trabajo (--hard)
Lo tercero que reset hará es hacer que el Directorio de Trabajo se parezca al Índice.
Si usas la opción --hard, continuará en esta etapa.
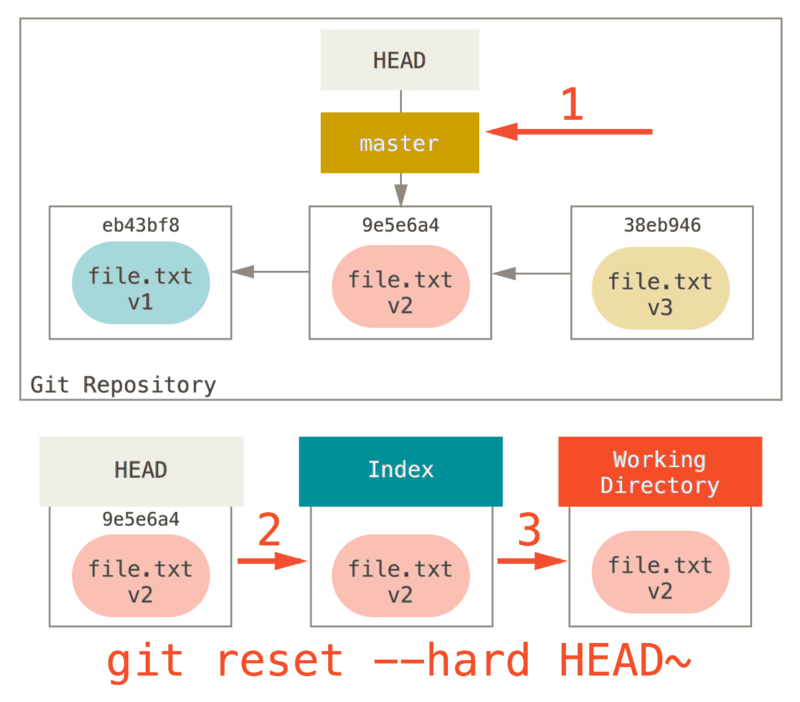
Entonces, pensemos en lo que acaba de pasar.
Deshizo tu último commit, los comandos git add y git commit, y todo el trabajo que realizaste en tu Directorio de Trabajo.
Es importante tener en cuenta que este indicador (--hard) es la única manera de hacer que el comando reset sea peligroso, y uno de los pocos casos en que Git realmente destruirá los datos.
Cualquier otra invocación de reset puede deshacerse fácilmente, pero la opción --hard no puede, ya que sobrescribe forzosamente los archivos en el Directorio de Trabajo.
En este caso particular, todavía tenemos la versión v3 de nuestro archivo en un “commit” en nuestro DB de Git, y podríamos recuperarla mirando nuestro reflog, pero si no le hubiéramos hecho “commit”, Git hubiese sobrescrito el archivo y sería irrecuperable.
Resumen
El comando reset sobrescribe estos tres árboles en un orden específico, deteniéndose cuando se le dice:
-
Mueva los puntos HEAD de la rama a (deténgase aquí si
--soft) -
Haga que el Índice se vea como HEAD (deténgase aquí a menos que
--hard) -
Haga que el Directorio de Trabajo se vea como el Índice
Reiniciar Con una Ruta
Eso cubre el comportamiento de reset en su forma básica, pero también puedes proporcionarle una ruta para actuar.
Si especificas una ruta, reset omitirá el paso 1 y limitará el resto de sus acciones a un archivo o conjunto específico de archivos.
Esto realmente tiene sentido – HEAD es solo un puntero, y no se puede apuntar a sólo una parte de un “commit” y otra parte de otro.
Pero el Índice y el Directorio de Trabajo pueden actualizarse parcialmente, por lo que el reinicio continúa con los pasos 2 y 3.
Entonces, supongamos que ejecutamos git reset file.txt.
Este formulario (ya que no especificó un commit SHA-1 o una rama, y no especificó --soft o --hard) es una abreviatura de git reset --mixed HEAD file.txt, la cual hará:
-
Mueva los puntos HEAD de la rama a (omitido)
-
Haga que el Índice se vea como HEAD (deténgase aquí)
Por lo tanto, básicamente solo copia archivo.txt de HEAD al Índice.
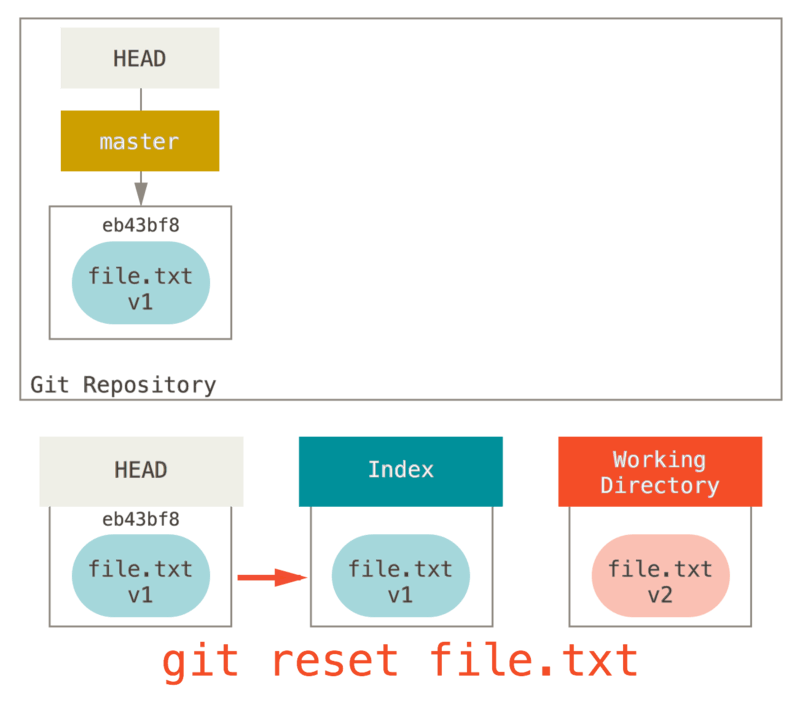
Esto tiene el efecto práctico de hacer unstaging al archivo.
Si miramos el diagrama para ese comando y pensamos en lo que hace git add, son exactamente opuestos.
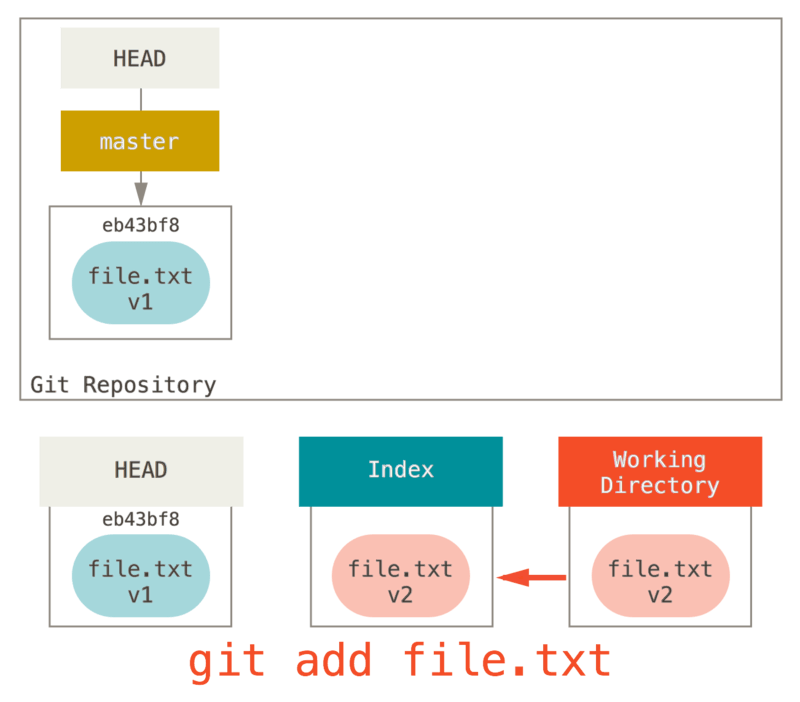
Esta es la razón por la cual el resultado del comando git status sugiere que ejecute esto para descentralizar un archivo.
(Consulte Deshacer un Archivo Preparado para más sobre esto).
Igualmente podríamos no permitir que Git suponga que queríamos “extraer los datos de HEAD” especificando un “commit” específico para extraer esa versión del archivo.
Simplemente ejecutaríamos algo como git reset eb43bf file.txt.
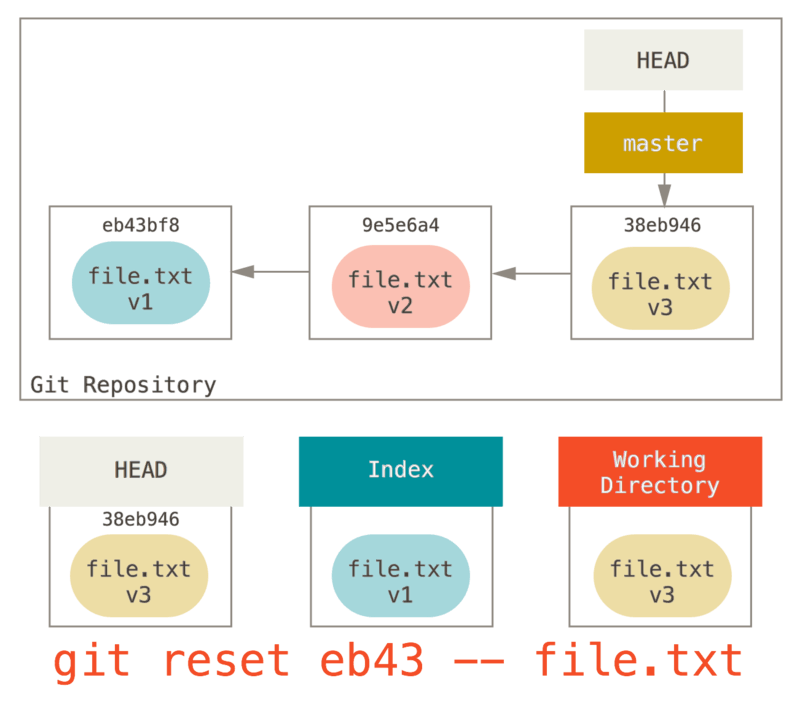
Esto efectivamente hace lo mismo que si hubiéramos revertido el contenido del archivo a v1 en el Directorio de Trabajo, ejecutado git add en él, y luego lo revertimos a v3 nuevamente (sin tener que ir a través de todos esos pasos)
Si ejecutamos git commit ahora, registrará un cambio que revierte ese archivo de vuelta a v1, aunque nunca más lo volvimos a tener en nuestro Directorio de Trabajo.
También es interesante observar que, como git add, el comando reset aceptará una opción --patch para hacer unstage del contenido en una base hunk-by-hunk.
Por lo tanto, puede hacer unstage o revertir el contenido de forma selectiva.
Aplastando
Veamos cómo hacer algo interesante con este poder recién descubierto – aplastando “commits”.
Supongamos que tienes una serie de confirmaciones con mensajes como “oops.”, “WIP” y “se olvidó de este archivo”.
Puedes usar reset para aplastarlos rápida y fácilmente en una sola confirmación que lo hace ver realmente inteligente.
(Aplastando muestra otra forma de hacerlo, pero en este ejemplo es más simple usar reset.)
Supongamos que tiene un proyecto en el que el primer “commit” tiene un archivo, el segundo “commit” agregó un nuevo archivo y cambió el primero, y el tercer “commit” cambió el primer archivo otra vez. El segundo “commit” fue un trabajo en progreso y quieres aplastarlo.
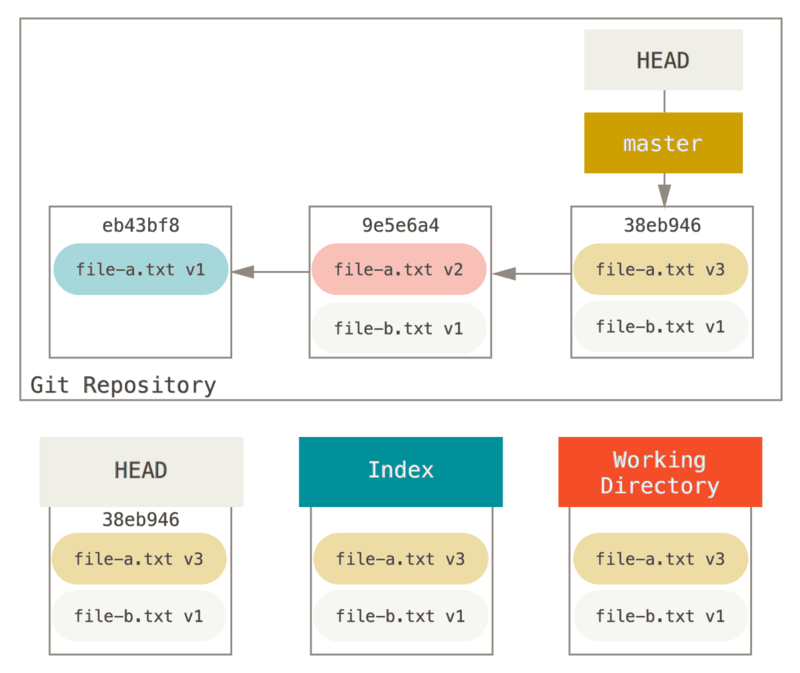
Puedes ejecutar git reset --soft HEAD~2 para mover la rama HEAD a un “commit” anterior (el primer “commit” que deseas mantener):
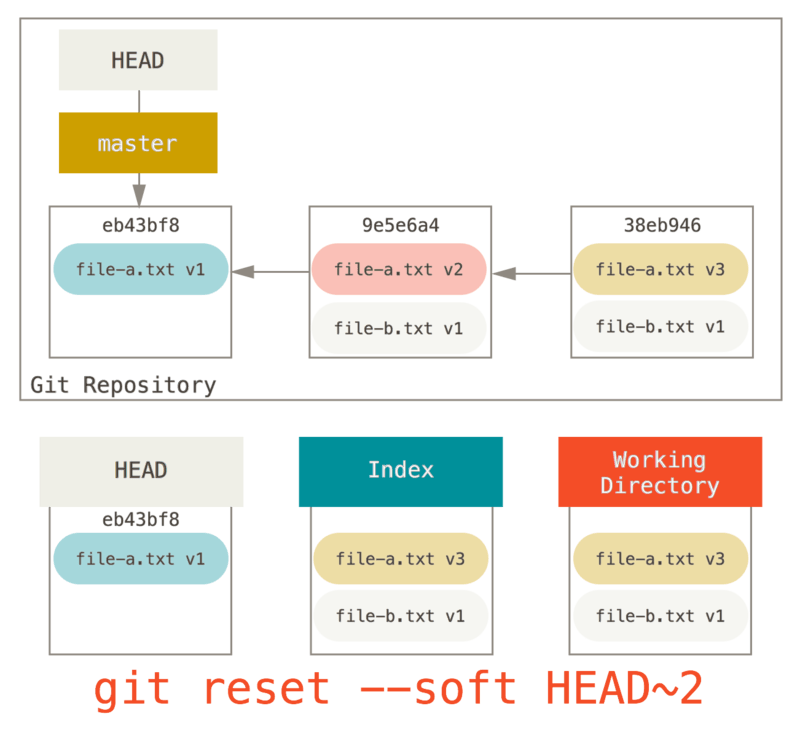
Y luego simplemente ejecuta git commit nuevamente:
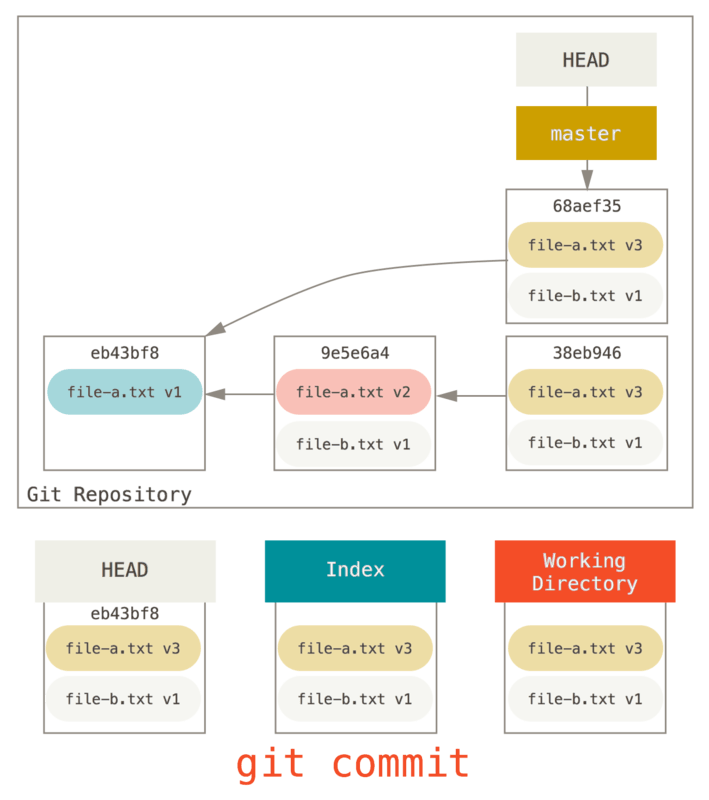
Ahora puedes ver que el historial alcanzable, la historia que empujarías, ahora parece que tuvo un “commit” con archivo-a.txt v1, luego un segundo que ambos modificaron archivo-a.txt a v3 y agregaron archivo-b.txt. El “commit” con la versión v2 del archivo ya no está en el historial.
Echale Un vistazo
Finalmente, puedes preguntarte cuál es la diferencia entre checkout y reset.
Al igual que reset, checkout manipula los tres árboles, y es un poco diferente dependiendo de si se le da al comando una ruta de archivo o no.
Sin Rutas
Ejecutar git checkout [branch] es bastante similar a ejecutar git reset --hard [branch] porque actualiza los tres árboles para que se vea como [branch], pero hay dos diferencias importantes.
Primero, a diferencia de reset --hard, checkout está en el directorio-de-trabajo seguro; Verificará para asegurarse de que no está volando los archivos que tienen cambios en ellos.
En realidad, es un poco más inteligente que eso – intenta hacer una fusión trivial en el Directorio de Trabajo, por lo que todos los archivos que no hayan cambiado serán actualizados.
reset --hard, por otro lado, simplemente reemplazará todo en general sin verificar.
La segunda diferencia importante es cómo actualiza HEAD.
Donde reset moverá la rama a la que HEAD apunta, checkout moverá HEAD para señalar otra rama.
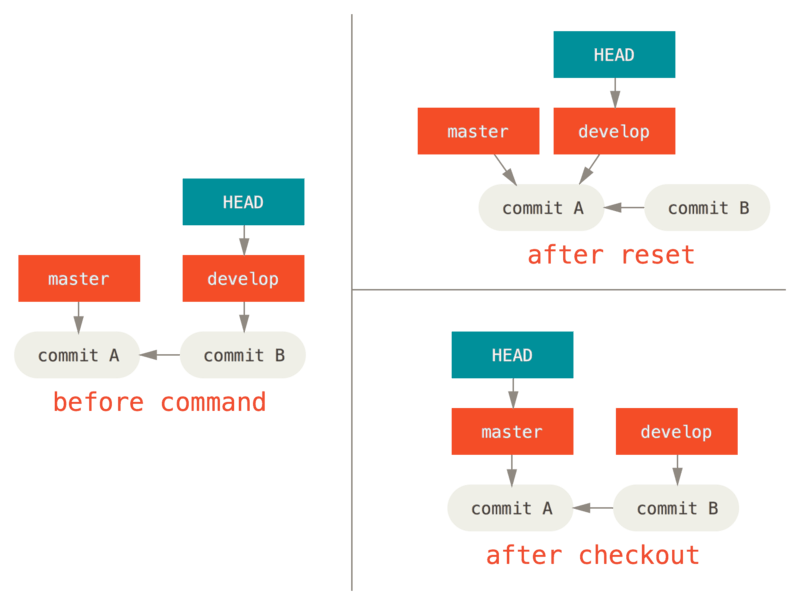
Por ejemplo, digamos que tenemos las ramas master y develop que apuntan a diferentes commits, y actualmente estamos en develop (así que HEAD la señala).
Si ejecutamos git reset master, develop ahora apuntará al mismo “commit” que master.
Si en cambio ejecutamos git checkout master, develop no se mueve, HEAD sí lo hace.
HEAD ahora apuntará a master.
Entonces, en ambos casos estamos moviendo HEAD para apuntar al “commit” A, pero el cómo lo hacemos es muy diferente.
reset moverá los puntos HEAD de la rama A, checkout mueve el mismo HEAD.
Con Rutas
La otra forma de ejecutar checkout es con una ruta de archivo, que como reset, no mueva HEAD.
Es como git reset [branch] file en que actualiza el índice con ese archivo en ese “commit”, pero también sobrescribe el archivo en el Directorio de Trabajo.
Sería exactamente como git reset --hard [branch] file (si reset permitiera ejecutar eso) - no está directorio-de-trabajo seguro, y no mueve a HEAD.
Además, al igual que git reset y git add, checkout aceptará una opción --patch para permitir revertir selectivamente el contenido del archivo sobre una base hunk-by-hunk.
Resumen
Esperamos que ahora entiendas y te sientas más cómodo con el comando reset, pero probablemente todavía estés un poco confundido acerca de cómo exactamente difiere de checkout y posiblemente no puedas recordar todas las reglas de las diferentes invocaciones.
Aquí hay una hoja de trucos para cuáles comandos afectan a cuáles árboles. La columna “HEAD” dice “REF” si ese comando mueve la referencia (rama) a la que HEAD apunta, y “HEAD” si se mueve al propio HEAD. Presta especial atención a la columna WD Safe: si dice NO , tómate un segundo para pensar antes de ejecutar ese comando.
| HEAD | Index | Workdir | WD Safe? | |
|---|---|---|---|---|
Nivel de Commit |
||||
|
REF |
NO |
NO |
SI |
|
REF |
SI |
NO |
SI |
|
REF |
SI |
SI |
NO |
|
HEAD |
SI |
SI |
SI |
Nivel de Archivo |
||||
|
NO |
SI |
NO |
SI |
|
NO |
SI |
SI |
NO |