
-
1. Начало
- 1.1 За Version Control системите
- 1.2 Кратка история на Git
- 1.3 Какво е Git
- 1.4 Конзолата на Git
- 1.5 Инсталиране на Git
- 1.6 Първоначална настройка на Git
- 1.7 Помощна информация в Git
- 1.8 Обобщение
-
2. Основи на Git
-
3. Клонове в Git
-
4. GitHub
-
5. Git инструменти
- 5.1 Избор на къмити
- 5.2 Интерактивно индексиране
- 5.3 Stashing и Cleaning
- 5.4 Подписване на вашата работа
- 5.5 Търсене
- 5.6 Манипулация на историята
- 5.7 Мистерията на командата Reset
- 5.8 Сливане за напреднали
- 5.9 Rerere
- 5.10 Дебъгване с Git
- 5.11 Подмодули
- 5.12 Пакети в Git (Bundling)
- 5.13 Заместване
- 5.14 Credential Storage система
- 5.15 Обобщение
-
6. Настройване на Git
- 6.1 Git конфигурации
- 6.2 Git атрибути
- 6.3 Git Hooks
- 6.4 Примерна Git-Enforced политика
- 6.5 Обобщение
-
7. Git и други системи
- 7.1 Git като клиент
- 7.2 Миграция към Git
- 7.3 Обобщение
-
8. Git на ниско ниво
- 8.1 Plumbing и Porcelain команди
- 8.2 Git обекти
- 8.3 Git референции
- 8.4 Packfiles
- 8.5 Refspec спецификации
- 8.6 Транспортни протоколи
- 8.7 Поддръжка и възстановяване на данни
- 8.8 Environment променливи
- 8.9 Обобщение
-
9. Приложение A: Git в други среди
-
10. Приложение B: Вграждане на Git в приложения
- 10.1 Git от команден ред
- 10.2 Libgit2
- 10.3 JGit
- 10.4 go-git
- 10.5 Dulwich
-
A1. Приложение C: Git команди
- A1.1 Настройки и конфигурация
- A1.2 Издърпване и създаване на проекти
- A1.3 Snapshotting
- A1.4 Клонове и сливане
- A1.5 Споделяне и обновяване на проекти
- A1.6 Инспекция и сравнение
- A1.7 Дебъгване
- A1.8 Patching
- A1.9 Email команди
- A1.10 Външни системи
- A1.11 Административни команди
- A1.12 Plumbing команди
8.2 Git на ниско ниво - Git обекти
Git обекти
Git е content-addressable файлова система. Супер. Какво означава това? Това означава, че по същество Git е просто склад за данни от типа key-value (ключ-стойност). Което от своя страна значи, че можете да вмъкнете произволен тип съдържание в Git хранилище и ще получите за него уникален идентификатор, който можете по-късно да използвате, за да извлечете съдържанието обратно.
За демонстрация, нека погледнем plumbing командата git hash-object, която приема някакви данни, съхранява ги в директорията .git/objects (базата данни с обекти) и ви връща уникалния ключ, сочещ към този информационен обект.
Първо, инициализираме ново Git хранилище и проверяваме, че в директорията objects няма нищо:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit създава тази директория objects заедно с поддиректориите ѝ pack и info, но освен тях няма никакви нормални файлове.
Нека сега изпълним git hash-object за да създадем и запишем в базата данни нов data обект ръчно:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4В най-простата си форма, git hash-object ще вземе данните, които сте ѝ подали и само ще върне уникалния ключ. който ще бъде използван за съхранението им в базата данни.
Флагът -w казва на командата не само да върне ключа, но и да запише обекта в базата.
Последно, --stdin инструктира git hash-object да вземе съдържанието, което ще обработва от stdin, в противен случай командата ще очаква като аргумент име на файла със съответното съдържание.
Изходът на екрана е 40-символен стринг. Това е SHA-1 хешът — чексума на съдържанието, което съхранявате плюс един хедър, за който ще научим по-късно. Сега може да видим как Git е съхранил данните ни:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4В директорията ни objects вече съществува файл за новото ни съдържание.
Първоначално Git запазва данните ни по този начин — като единичен файл за частичка съдържание, с наименование SHA-1 чексумата на съдържанието и хедъра.
Поддиректорията (d6) се именува с първите два символа от SHA-1 чексумата, а името на файла се формира от останалите 38 символа.
Веднъж записали съдържание в базата данни, можете да го изследвате с командата git cat-file.
Тази команда е като швейцарско ножче за инспектиране на Git обекти.
Параметърът -p инструктира командата първо да определи вида на съдържанието и след това да го покаже по съответния начин:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentСега можете да записвате и извличате обратно текстово съдържание в Git. Може да правите това и със съдържанието на файлове. Например, можете да направите прост контрол на версиите за файл. Първо създаваме нов файл и записваме съдържанието му в базата данни:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30След това, записваме нови данни във файла и го записаме отново:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aСега базата с обекти съдържа и двете версии на този нов файл (първоначалното текстово съдържание също е тук):
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Сега можете спокойно да изтриете локалното копие на файла test.txt, а след това да използвате Git за да извлечете коя да е от версиите му от базата данни:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1ако искате втората версия:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Но запомнянето на SHA-1 ключа за всяка версия на файла едва ли е практично и освен това вие не пазите името на файла, а само съдържанието му.
Този тип обект се нарича blob.
Можете да кажете на Git да ви извлече типа на всеки обект по дадена SHA-1 стойност с git cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobTree обекти
Следващият тип обект в Git е tree, който решава проблема със записа на името на файла и също така позволява да запазвате група файлове заедно. Git пази съдържанието по маниер подобен на UNIX файлова система, но една идея по-опростено. Цялото съдържание се съхранява под формата на tree и blob обекти, като дърветата играят ролята на съответните UNIX директории и blob-обектите съответстват малко или много на inodes или файлово съдържание. Единичен tree обект съдържа един или повече tree елемента, всеки от които съдържа SHA-1 указател към blob или поддърво със съответните име на файл, режим и тип. Например, най-новото дърво в проект може да изглежда по такъв начин:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libСинтаксисът master^{tree} указва tree обекта, към който сочи последния къмит в master клона.
Забелязваме, че lib поддиректорията не е blob, а указател към друго дърво:
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rb|
Забележка
|
В зависимост от шела, който използвате, може да срещнете грешки при използване на синтаксиса В CMD под Windows, символът Ако имате ZSH, тогава символът |
Концептуално, данните които Git запазва изглеждат така:
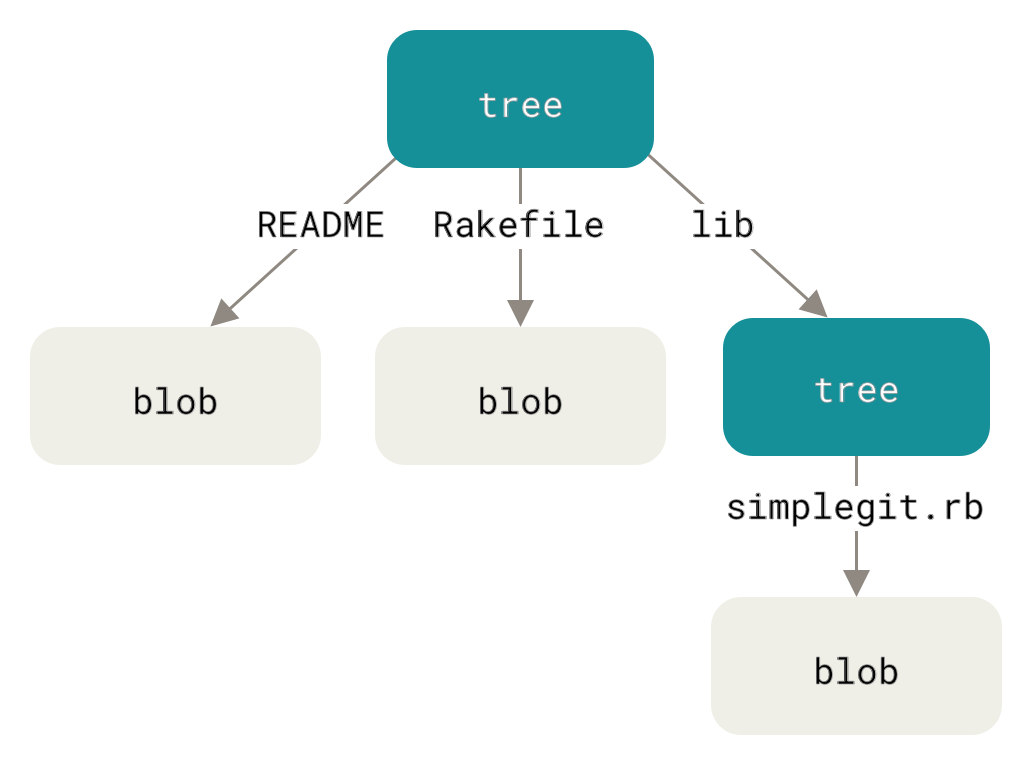
Можете сравнително лесно да създадете собствено дърво.
Git нормално създава дърво вземайки статуса на индексната област и записвайки серия от tree обекти от нея.
Така, за да създадете tree обект, първо трябва да инициализирате индекса с някакви файлове.
За да създадете индекс с един елемент — първата версия на файла test.txt, може да използвате plumbing командата git update-index.
Използвайки я, добавяте изкуствено най-ранната версия на файла към нова индексна област.
Трябва да подадете аргумента --add, защото файлът все още не съществува в индекса (и дори самият индекс още не съществува) и също --cacheinfo, защото файлът, който добавяте не е в работната директория, а е в базата данни.
След това подавате режима, SHA-1 стойността и името на файла:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtВ този случай указваме режим 100644, което ще рече, че това е обикновен файл.
Другите опции са 100755 за изпълним файл и 120000, който указва символна връзка (symlink).
Режимът се взема съобразно стандартните UNIX правила, но е много по-малко гъвкав — това са единствените три режима, които са валидни за файлове (blobs) в Git (въпреки че други режими се използват за директории и подмодули).
Сега може да използвате git write-tree за да запишете индексната област в tree обект.
Не се изисква флаг -w — изпълнението на тази команда автоматично създава tree обект съобразно статуса на индекса, ако такова дърво вече не съществува:
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtМоже да проверите, че това е tree обект със същата git cat-file команда от по-рано:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeСега ще създадем ново дърво с втората версия на test.txt файла и също така още един нов файл:
$ echo 'new file' > new.txt
$ git update-index --cacheinfo 100644 \
1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txt
$ git update-index --add new.txtСега индексът ни има новата версия на test.txt, както и новия файл new.txt.
Записваме това дърво в tree обект и поглеждаме как изглежда:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtЗабелязваме, че сега това дърво съдържа и двата файла, и че SHA-1 стойността на test.txt вече е “version 2” от по-рано (1f7a7a).
Само за идеята, ще добавим първото дърво като поддиректория в това.
Може да прочитаме дървета от индекса с командата git read-tree.
В този случай, може да прочетем дърво от индекса като поддърво с параметъра --prefix към командата:
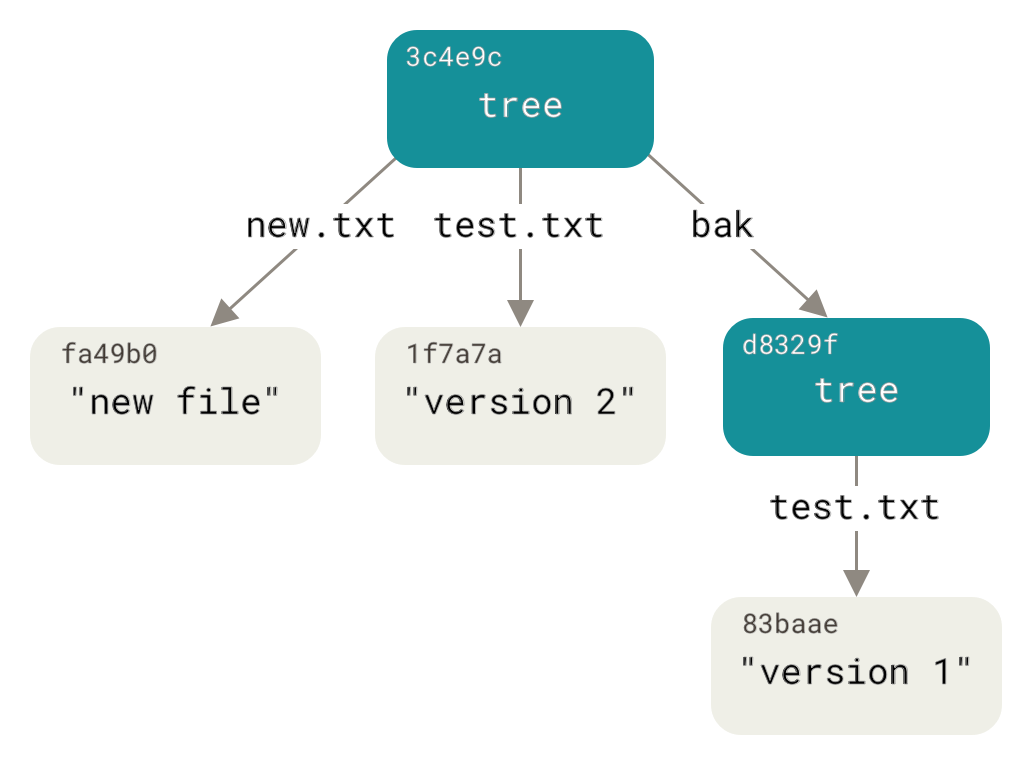
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtАко създадем работна директория от новозаписаното дърво, ще получим в нея двата файла в корена ѝ и поддиректория bak, в която е първата версия на файла test.txt.
Може да пресъздадем данните, които Git пази за тези структури, така:
Commit обекти
Ако сте изпълнили всички стъпки досега, разполагате с три дървета, които представят различните snapshot-и на проекта, който искате да следите. Но проблемът все още стои: трябва да помните всичките три SHA-1 стойности, за да извлечете съдържанието им. Също така, нямате никаква информация за това кой е съхранил тези snapshot-и, кога са записани или защо са записани. Това е информацията, която съхраняват къмит обектите.
За да създадем такъв обект, използваме командата commit-tree, която очаква като аргументи SHA-1 хеша на единично дърво и също така, кой къмит обект (ако има такъв) директно го предшества.
Започваме с първото съхранено дърво:
$ echo 'First commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3d|
Забележка
|
Получаваме различна хеш стойност поради различното време на създаване на обекта и данните за автора. Освен това, въпреки че по принцип всеки къмит обект може да се пресъздаде прецизно с тези данни, хронологичните особености на конструкцията на тази книга означават, че отпечатаните къмит хешове може да не съответстват на дадените къмити. По-натам в главата, замествайте commit и tag хешовете с вашите собствени чексуми. |
Сега можем да разгледаме новия ни къмит обект с командата git cat-file:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
First commitФорматът е прост: той указва top-level дървото за snapshot-а на проекта в този момент; родителските къмити, ако съществуват такива (описаният отгоре обект няма никакви родители); author/committer информацията (ще се използват текущите конфигурационни настройки за user.name и user.email и timestamp); следва празен ред и накрая е къмит съобщението.
Следва да запишем другите два къмит обекта, всеки от които сочи към къмита дошъл директно преди него:
$ echo 'Second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'Third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Всеки от трите къмит обекта сочи към едно от трите snapshot дървета, които създадохме.
Сега вече имаме и реална Git история, която може да видим с git log, ако я пуснем за SHA-1 стойността на последния къмит:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
Third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
Second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
First commit
test.txt | 1 +
1 file changed, 1 insertion(+)Чудесно.
Току що извършихме операции от ниско ниво за да си изградим Git история без да използваме нито една porcelain команда.
По същество това прави Git, когато изпълните git add и git commit — записва blob обекти за променените файлове, обновява индекса, записва дървета и записва къмит обекти, които сочат към top-level дърветата и къмитите дошли непосредствено преди тях.
Тези три основни Git обекта — blob, tree, и commit, първоначално се съхраняват като отделни файлове в директорията .git/objects.
Ето всички обекти в примерната ни директория с коментар за това, което съхраняват:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Ако проследим всички вътрешни указатели, получаваме графика от този вид:
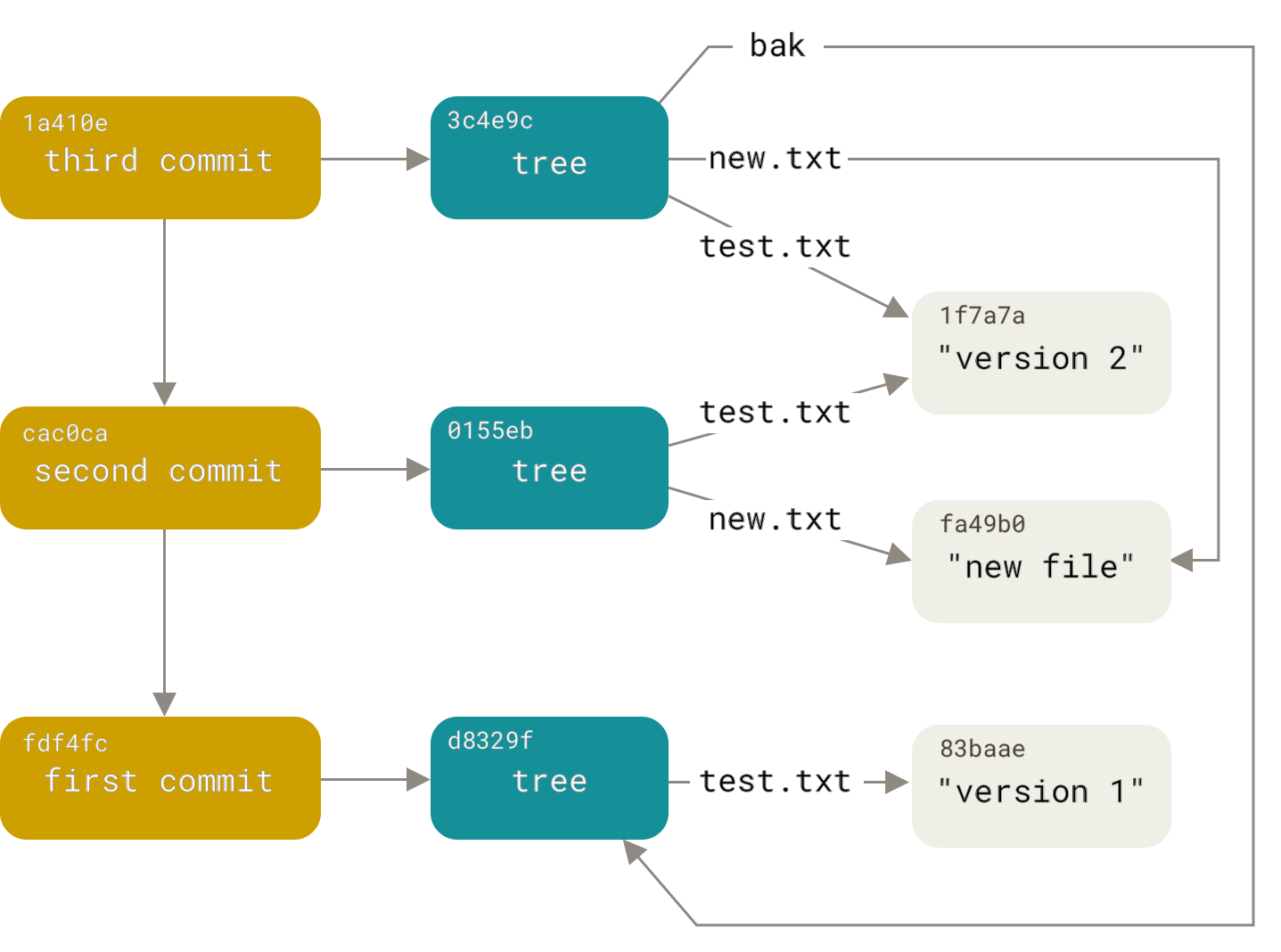
Съхранение на обектите
По-рано казахме, че с всеки обект, който къмитваме в базата данни се пази и по един хедър. Нека видим как Git съхранява обектите си. Ще видим как да съхраним blob обект, в този случай стринга “what is up, doc?” — интерактивно в Ruby scripting езика.
Може да стартирате интерактивния Ruby режим с irb командата:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git първо конструира хедър, който започва с идентифициране на типа на обекта — в този случай blob. Към тази първа част от хедъра, Git добавя интервал последван от размера на съдържанието в байтове и финален null байт:
>> header = "blob #{content.bytesize}\0"
=> "blob 16\u0000"Git конкатенира хедъра и оригиналното съдържание, след което калкулира нова SHA-1 стойност на резултата.
В Ruby, можете да калкулирате SHA-1 стойност на стринг като инклуднете SHA1 digest библиотеката с require команда и след това викайки метода Digest::SHA1.hexdigest() със стринга:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Нека сравним това с изхода от git hash-object.
Тук използваме echo -n за да избегнем добавянето на нов ред към входа.
$ echo -n "what is up, doc?" | git hash-object --stdin
bd9dbf5aae1a3862dd1526723246b20206e5fc37Git компресира новото съдържание със zlib, което може да направите в Ruby с библиотеката zlib.
Първо инклудвате библиотеката и след това изпълнявате Zlib::Deflate.deflate() за съдържанието:
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"Последно, записате zlib-deflated съдържанието в обект на диска.
Установявате пътя за обекта (първите два символа от SHA-1 стойността са името на поддиректорията, останалите 38 са името на файла в нея).
В Ruby може да използвате функцията FileUtils.mkdir_p() за да създадете директорията, ако тя не съществува.
След това, отворете файла с File.open() и запишете в него zlib-компресираното съдържание с write() повикване към получения файлов указател:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32Нека проверим съдържанието на обекта с git cat-file:
---
$ git cat-file -p bd9dbf5aae1a3862dd1526723246b20206e5fc37
what is up, doc?
---Това е, вече създадохте валиден Git blob обект.
Всички Git обекти се записват по същия начин, само с различни типове — вместо със стринга blob, хедърът ще започва с commit или tree. Също така, въпреки че blob съдържанието може да е практически всякакво, то commit и tree съдържанията се форматират строго специфично.