
-
1. Начало
- 1.1 За Version Control системите
- 1.2 Кратка история на Git
- 1.3 Какво е Git
- 1.4 Конзолата на Git
- 1.5 Инсталиране на Git
- 1.6 Първоначална настройка на Git
- 1.7 Помощна информация в Git
- 1.8 Обобщение
-
2. Основи на Git
-
3. Клонове в Git
-
4. GitHub
-
5. Git инструменти
- 5.1 Избор на къмити
- 5.2 Интерактивно индексиране
- 5.3 Stashing и Cleaning
- 5.4 Подписване на вашата работа
- 5.5 Търсене
- 5.6 Манипулация на историята
- 5.7 Мистерията на командата Reset
- 5.8 Сливане за напреднали
- 5.9 Rerere
- 5.10 Дебъгване с Git
- 5.11 Подмодули
- 5.12 Пакети в Git (Bundling)
- 5.13 Заместване
- 5.14 Credential Storage система
- 5.15 Обобщение
-
6. Настройване на Git
- 6.1 Git конфигурации
- 6.2 Git атрибути
- 6.3 Git Hooks
- 6.4 Примерна Git-Enforced политика
- 6.5 Обобщение
-
7. Git и други системи
- 7.1 Git като клиент
- 7.2 Миграция към Git
- 7.3 Обобщение
-
8. Git на ниско ниво
- 8.1 Plumbing и Porcelain команди
- 8.2 Git обекти
- 8.3 Git референции
- 8.4 Packfiles
- 8.5 Refspec спецификации
- 8.6 Транспортни протоколи
- 8.7 Поддръжка и възстановяване на данни
- 8.8 Environment променливи
- 8.9 Обобщение
-
9. Приложение A: Git в други среди
-
10. Приложение B: Вграждане на Git в приложения
- 10.1 Git от команден ред
- 10.2 Libgit2
- 10.3 JGit
- 10.4 go-git
- 10.5 Dulwich
-
A1. Приложение C: Git команди
- A1.1 Настройки и конфигурация
- A1.2 Издърпване и създаване на проекти
- A1.3 Snapshotting
- A1.4 Клонове и сливане
- A1.5 Споделяне и обновяване на проекти
- A1.6 Инспекция и сравнение
- A1.7 Дебъгване
- A1.8 Patching
- A1.9 Email команди
- A1.10 Външни системи
- A1.11 Административни команди
- A1.12 Plumbing команди
3.5 Клонове в Git - Отдалечени клонове
Отдалечени клонове
Отдалечените референции са указатели към вашите отдалечени хранилища, вкл. клонове, тагове и др.
Можете да получите списък на всички отдалечени указатели изрично с командата git ls-remote <remote>, или git remote show <remote> за отдалечени клонове и друга информация.
Най-използваната функционалност от разработчиците е да се възползват от предимствата на remote-tracking клоновете.
Remote-tracking клоновете са указатели към състоянието на отдалечените клонове код. Това са локални референции, които не можете да местите, те се преместват автоматично за вас в резултат от някакви мрежови комуникации, така че да е сигурно, че те акуратно отразяват статуса на отдалеченото хранилище. Служат като отметки за да ви напомнят в какво състояние са били отдалечените клонове код последния път, когато сте се свързвали с тях.
Те следват конвенцията <remote>/<branch>.
Например, ако искате да видите в какво състояние е бил master клона на вашето отдалечено хранилище origin последния път, когато сте комуникирали с него, можете да го направите посредством клона origin/master.
Ако съвместно с ваш колега работите по даден проблем и той е публикувал нещо в клона iss53, вие можете да имате локален такъв със същото име, но клонът на сървъра ще е достъпен през референцията origin/iss53.
Това може да е объркващо, така че нека го разгледаме с пример.
Нека кажем, че имате Git сървър в мрежата ви на адрес git.ourcompany.com.
Ако клонирате хранилище от него, clone командата на Git автоматично ще го именува с името origin, ще издърпва всички данни от него, ще създаде указател към мястото където е master клона на това хранилище и ще го съхрани като origin/master локално при вас.
Git също така създава локален master клон, който сочи към същото място в проекта, така че да имате от къде да започнете локалната си работа.
|
Забележка
|
“origin” не е специална дума
Точно както и |
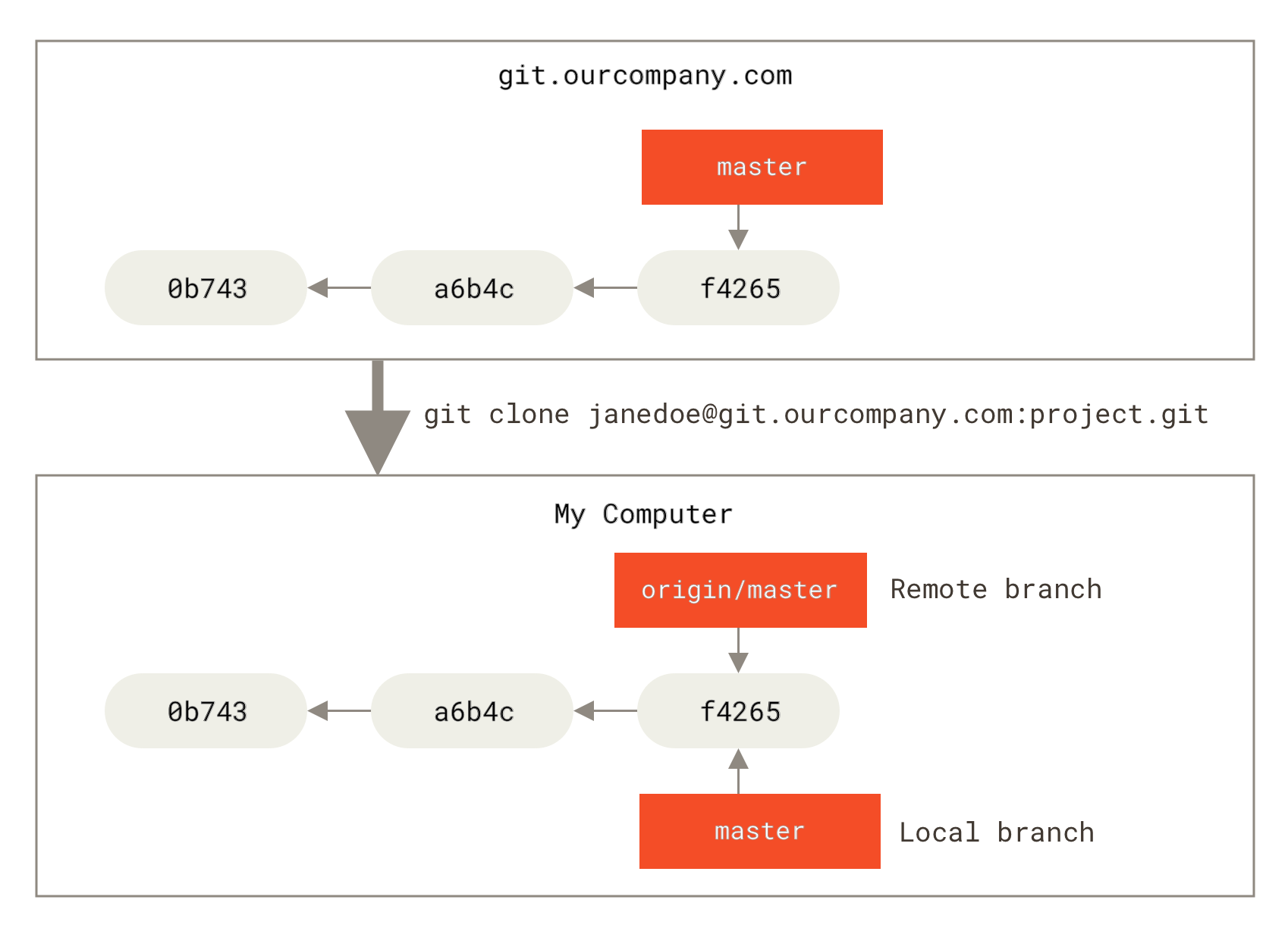
Ако вие вършите някаква работа в локалния си master клон и междувременно някой друг изпрати нещо към git.ourcompany.com и промени master клона там, тогава вашите истории на промените ще се движат напред по различни начини.
Също така, докато не контакувате с вашия origin сървър, указателят origin/master не се премества самичък.
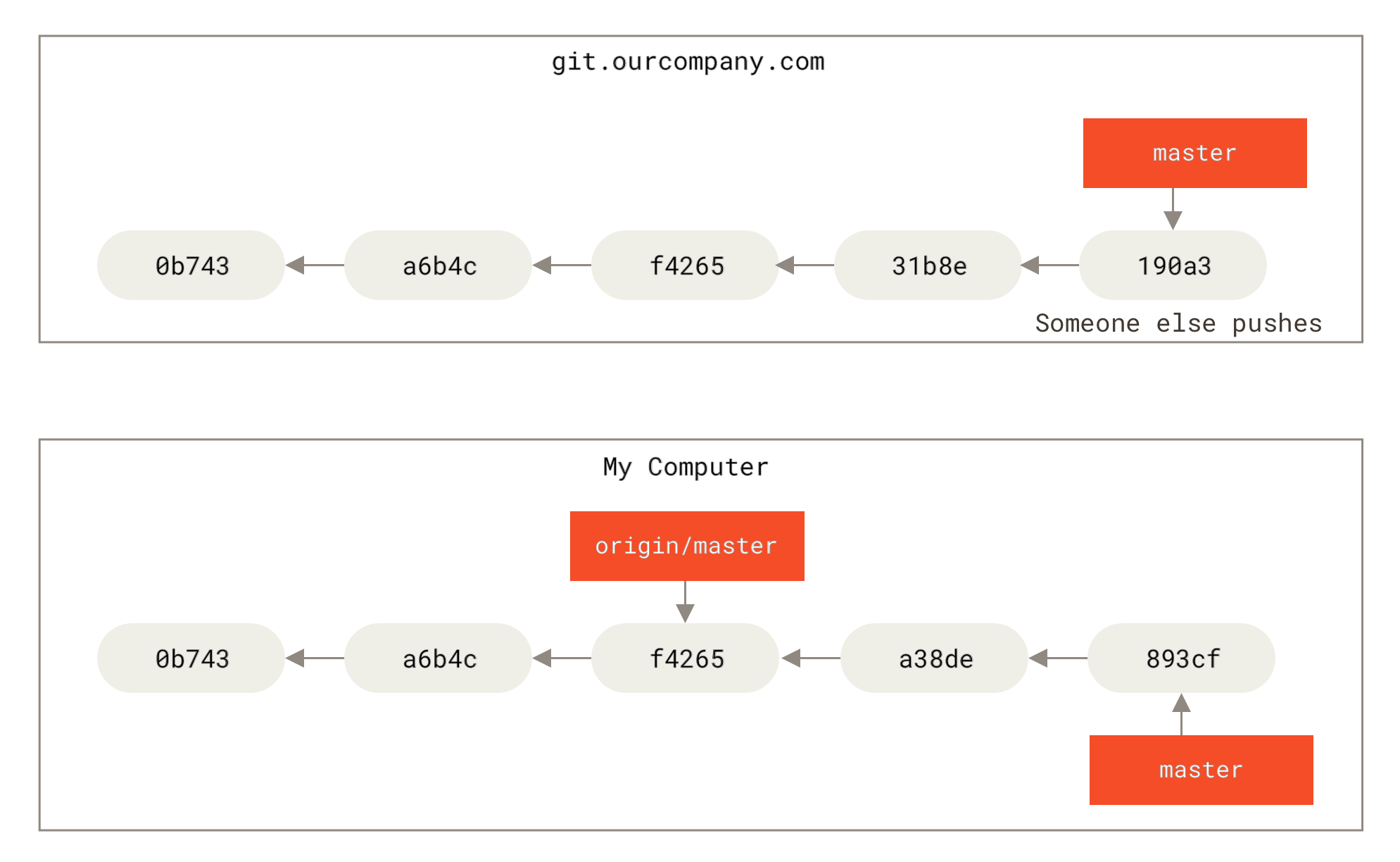
За да синхронизирате работата си така, че да отразява промените на сървъра, използвайте командата git fetch <remote> (в нашия случай git fetch origin).
Тази команда установява кой е адреса на сървъра “origin” (в случая git.ourcompany.com), издърпва всички данни, които все още нямате локално и обновява локалната база данни, така че указателят origin/master вече да сочи към нова, по-актуална позиция от историята.
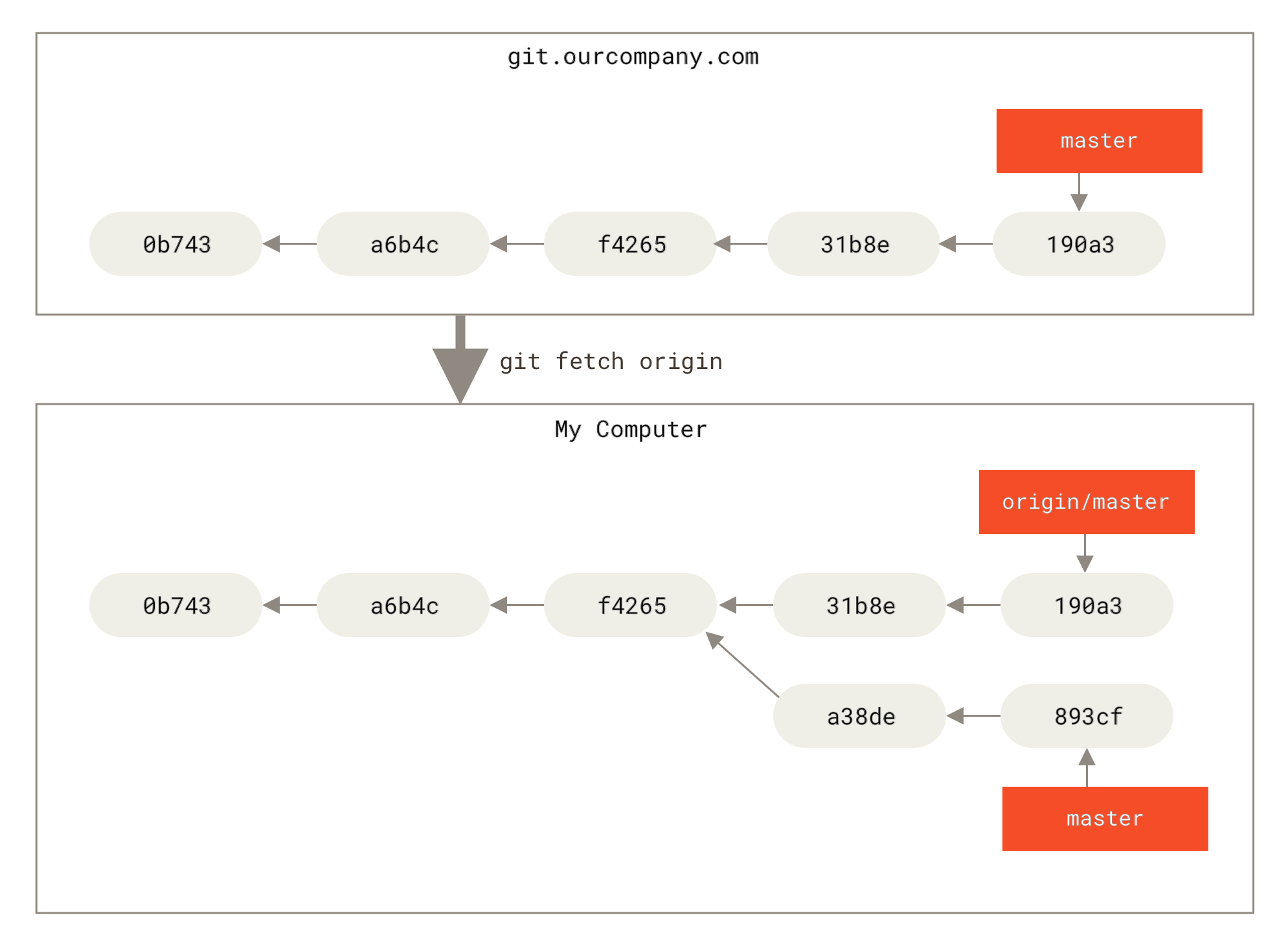
git fetch обновява отдалечените ви референцииЗа да демонстрираме какво е да имате много отдалечени сървъри и как изглеждат клоновете на съответните отдалечени проекти, нека приемем, че имате още един вътрешнофирмен Git сървър, който се използва само за разработка от някой от вашите sprint екипи.
Сървърът е на адрес git.team1.ourcompany.com.
Можете да го добавите като нова отдалечена референция към проекта, в който работите, с командата git remote add, която разгледахме в Основи на Git.
Наречете това отдалечено хранилище teamone, което ще е краткото име за целия URL.
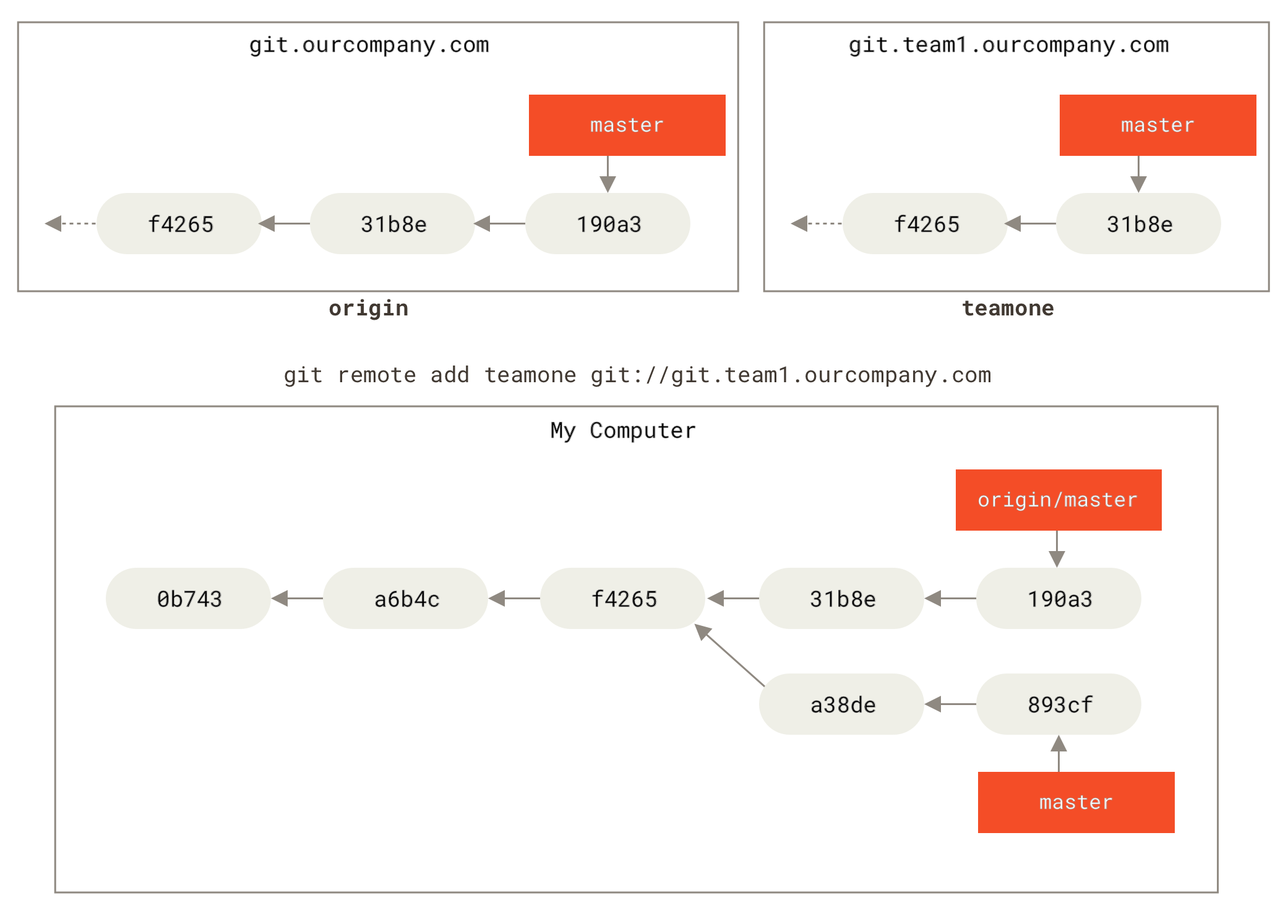
Сега можете да изпълните git fetch teamone за да изтеглите всичко, което този сървър има, а вие все още нямате локално. Понеже този сървър съхранява подмножество от данните на вашия origin сървър, Git всъщност не тегли от него нищо, а просто създава remote-tracking клон наречен teamone/master, който сочи към последния къмит, който teamone има за своя master клон.
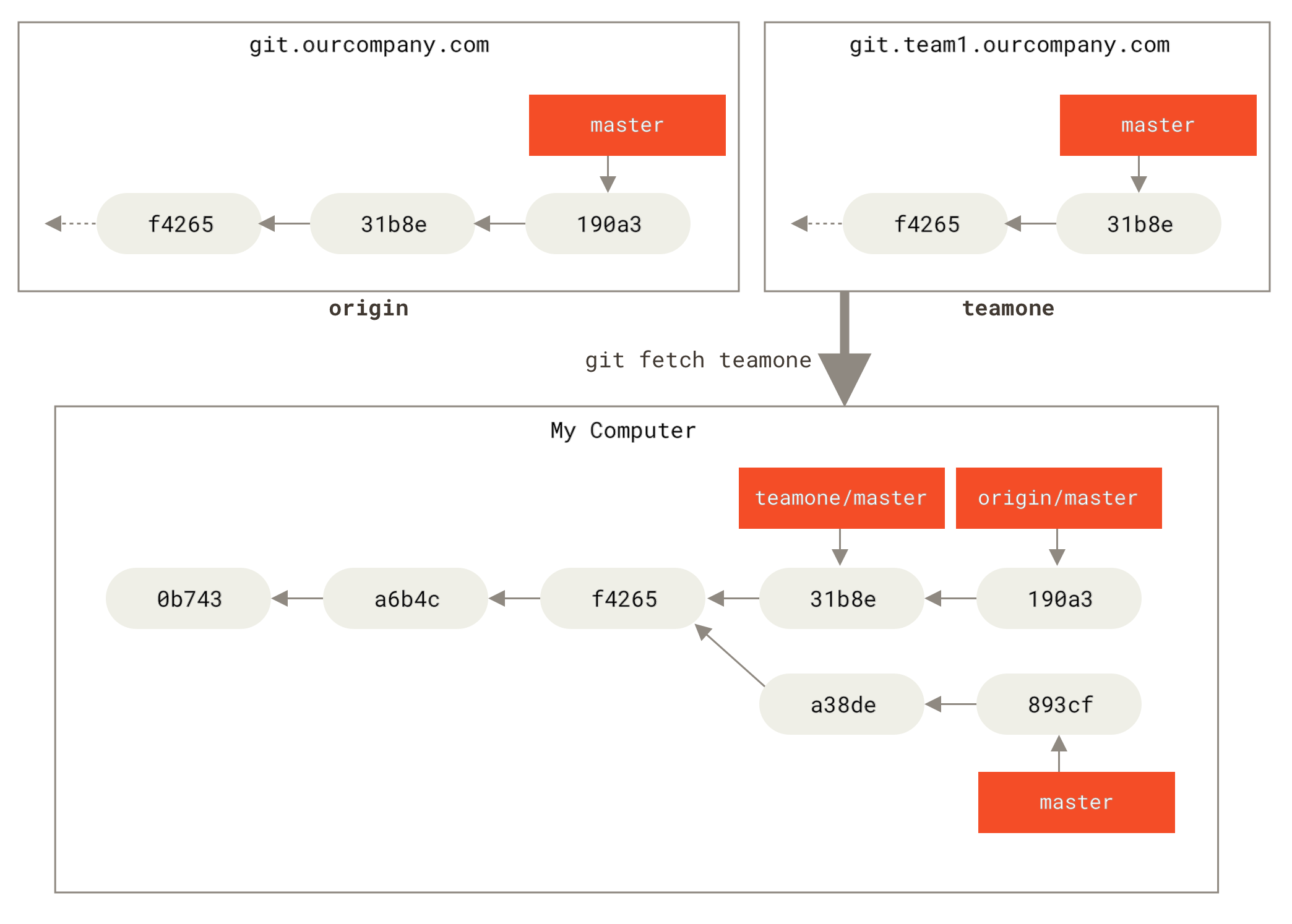
teamone/master
Изпращане към сървъра (pushing)
Когато искате да споделите работата от ваш локален клон с другите си колеги, трябва да го изпратите към отдалечено хранилище, към което имате права за писане. Вашите локални клонове не се синхронизират автоматично с регистрираните отдалечени хранилища — вие трябва изрично да ги изпратите към тях. По този начин, можете да си имате частни клонове код само за вас и които не желаете да споделяте, а да споделяте само topic клоновете, към които допринасяте.
Ако имате клон наречен serverfix, който искате да споделите с другите, можете да го изпратите по същия начин, по който изпратихте първия си клон.
Изпълнете git push <remote> <branch>:
$ git push origin serverfix
Counting objects: 24, done.
Delta compression using up to 8 threads.
Compressing objects: 100% (15/15), done.
Writing objects: 100% (24/24), 1.91 KiB | 0 bytes/s, done.
Total 24 (delta 2), reused 0 (delta 0)
To https://github.com/schacon/simplegit
* [new branch] serverfix -> serverfixТова е един вид съкращение.
Git автоматично разширява името на клона serverfix до refs/heads/serverfix:refs/heads/serverfix, което означава, “Вземи локалния ми клон serverfix и го изпрати към отдалеченото хранилище, обновявайки отдалечения клон serverfix”.
Ще разгледаме частта refs/heads/ в подробности в Git на ниско ниво, засега не ѝ обръщайте внимание.
Можете също да изпълните git push origin serverfix:serverfix, което върши същата работа, тази команда означава “Вземи локалния ми клон serverfix и го слей с отдалечения със същото име”.
Можете да използвате този формат, за да слеете локален клон с отдалечен, който се казва по различен начин.
Ако не желаете отдалеченият да се казва serverfix в сървърното хранилище, можете да изпълните например git push origin serverfix:awesomebranch и отдалечения клон ще се казва awesomebranch.
|
Забележка
|
Не пишете паролата си всеки път
Ако използвате HTTPS URL за изпращане, Git сървърът ще ви пита за име и парола всеки път когато изпращате към него. По подразбиране ще получите запитване в терминала, така че сървърът да знае дали можете да записвате на него Ако не желаете това, можете да направите т. нар. “credential cache”.
Най-лесно е да запомните паролата в кеша за известно време, което можете да направите с командата За повече информация за различните опции за този кеш, вижте Credential Storage система. |
Следващият път, когато колегите ви теглят от сървъра, ще получат референция към точката в която сочи сървърната версия на клона serverfix под формата на отдалечен за тях клон origin/serverfix:
$ git fetch origin
remote: Counting objects: 7, done.
remote: Compressing objects: 100% (2/2), done.
remote: Total 3 (delta 0), reused 3 (delta 0)
Unpacking objects: 100% (3/3), done.
From https://github.com/schacon/simplegit
* [new branch] serverfix -> origin/serverfixВажно е да се запомни, че когато изпълните git fetch за да изтеглите новосъздадени remote-tracking клонове, вие не получавате автоматично техни редактируеми копия!
С други думи, в този случай няма да имате действителното съдържание на клона serverfix, а само указателят origin/serverfix, който не можете да променяте.
За да стане това, трябва да го слеете в текущия си клон с git merge origin/serverfix.
Ако не желаете това да стане в текущия клон, а в нов локален такъв с име serverfix, можете да го базирате на remote-tracking клона:
$ git checkout -b serverfix origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Switched to a new branch 'serverfix'Това ви дава локален клон, в който да работите и който стартира от точката, в която е origin/serverfix.
Проследяване на клонове
Извличането на локален клон от remote-tracking такъв автоматично създава т. нар. “tracking branch” (и клонът, който той следи се нарича “upstream branch”).
Проследяващите клонове са локални такива, които имат директна връзка с отдалечен клон.
Ако сте в такъв проследяващ клон и изпълните git pull, Git автоматично знае кой сървър да ползва за изтегляне и в кой клон да слее разликите.
Когато клонирате хранилище, системата създава автоматично master клон, който проследява origin/master.
Обаче, ако желаете, можете да създадете и други проследяващи клонове - такива, които следят клонове от други отдалечени хранилища или пък не следят точно master клона от сървъра.
Прост случай е примерът, който току що видяхте, изпълнявайки git checkout -b <branch> <remote>/<branch>.
Това е често случваща се операция, за която Git осигурява --track съкращение:
$ git checkout --track origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Switched to a new branch 'serverfix'В действителност, това е толкова често срещано, че съществува съкращение на съкратената версия. Ако клонът с името, към който се опитвате да превключите, не съществува локално, но съвпада по име с такъв от точно едно отдалечено хранилище, Git ще създаде проследяващ клон за вас:
$ git checkout serverfix
Branch serverfix set up to track remote branch serverfix from origin.
Switched to a new branch 'serverfix'Ако искате да създадете клон с различно име от това, което е в отдалеченото хранилище, можете лесно да ползвате първата версия с различно име за локалния клон:
$ git checkout -b sf origin/serverfix
Branch sf set up to track remote branch serverfix from origin.
Switched to a new branch 'sf'Сега, локалният ви клон sf автоматично ще тегли от origin/serverfix.
Ако ли пък имате локален клон и искате да го накарате да следи клона, който току що изтеглихте, или пък искате да смените upstream клона, можете да използвате -u или --set-upstream-to опциите на git branch за да укажете изрично името.
$ git branch -u origin/serverfix
Branch serverfix set up to track remote branch serverfix from origin.|
Забележка
|
Upstream съкращение
Когато имате настроен проследяващ клон, можете да се обръщате към неговия upstream клон със съкращенията За да отпечатате какви проследявани клонове имате, използвайте параметъра Така можем да видим, че нашият Важно е да запомним, че тези цифри са актуални към момента на последното изпълнение на ==== Pulling (изтегляне и сливане)
Вече казахме, че командата В общия случай е по-добре да използвате ==== Изтриване на отдалечени клонове
Да допуснем, че сте готови с отдалечения клон - да кажем че колегите ви са свършили работа по определена функционалност и са я слели в отдалечения ви Всичко, което това прави е да изтрие указателя от сървъра. Git сървърът в повечето случаи ще пази данните за известно време докато мине garbage collection системата му, така че случайно изтритите данни често могат лесно да се възстановят. === Пребазиране на клонове
В Git съществуват два основни начина за интегриране на промени от един клон код в друг: сливане ( ==== Просто пребазиране Ако се върнете назад до по-ранния пример в Сливане, можете да си припомните, че работата ви се разклонява и вие правихте къмити в два различни клона. 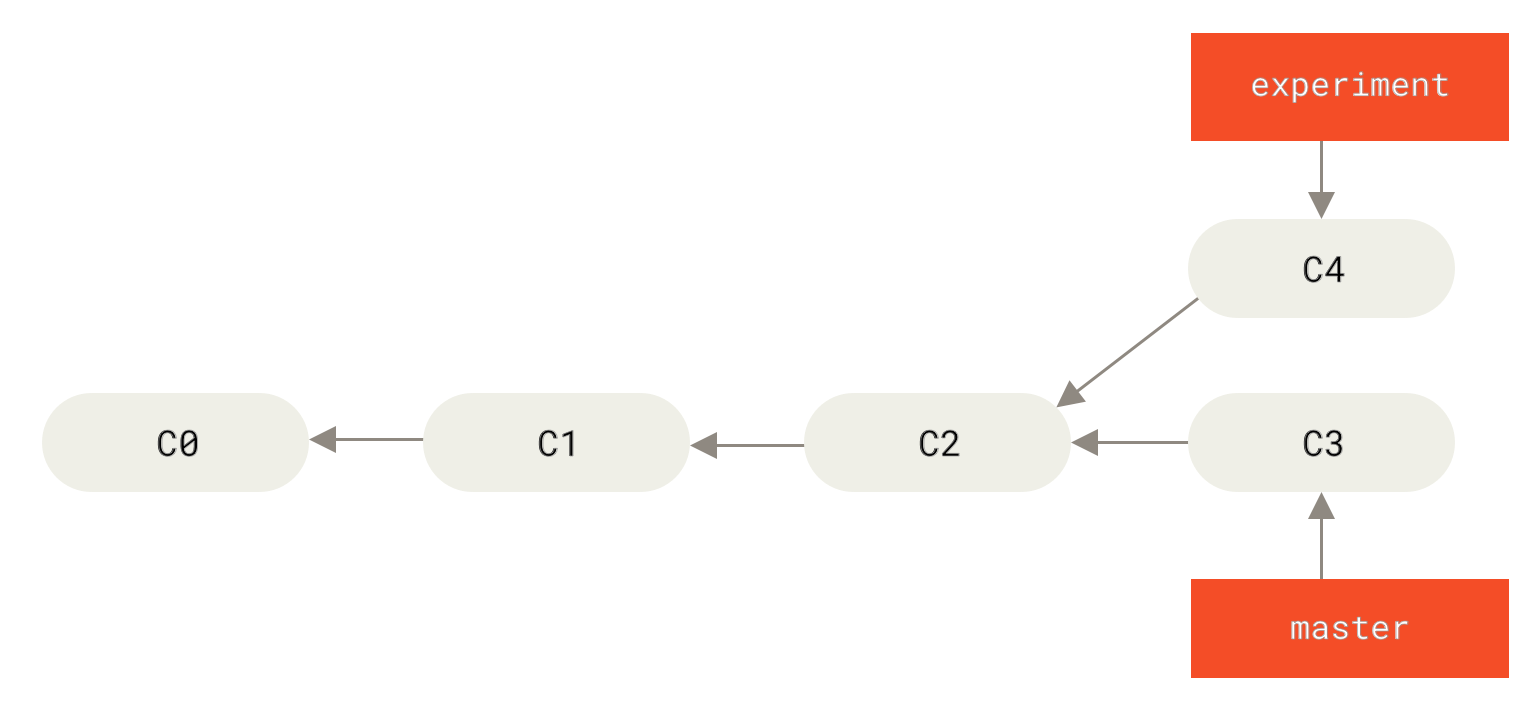
Фигура 35. Проста история на разклоняването
Най-лесният начин за интегрирането на клоновете, както вече разгледахме, беше командата 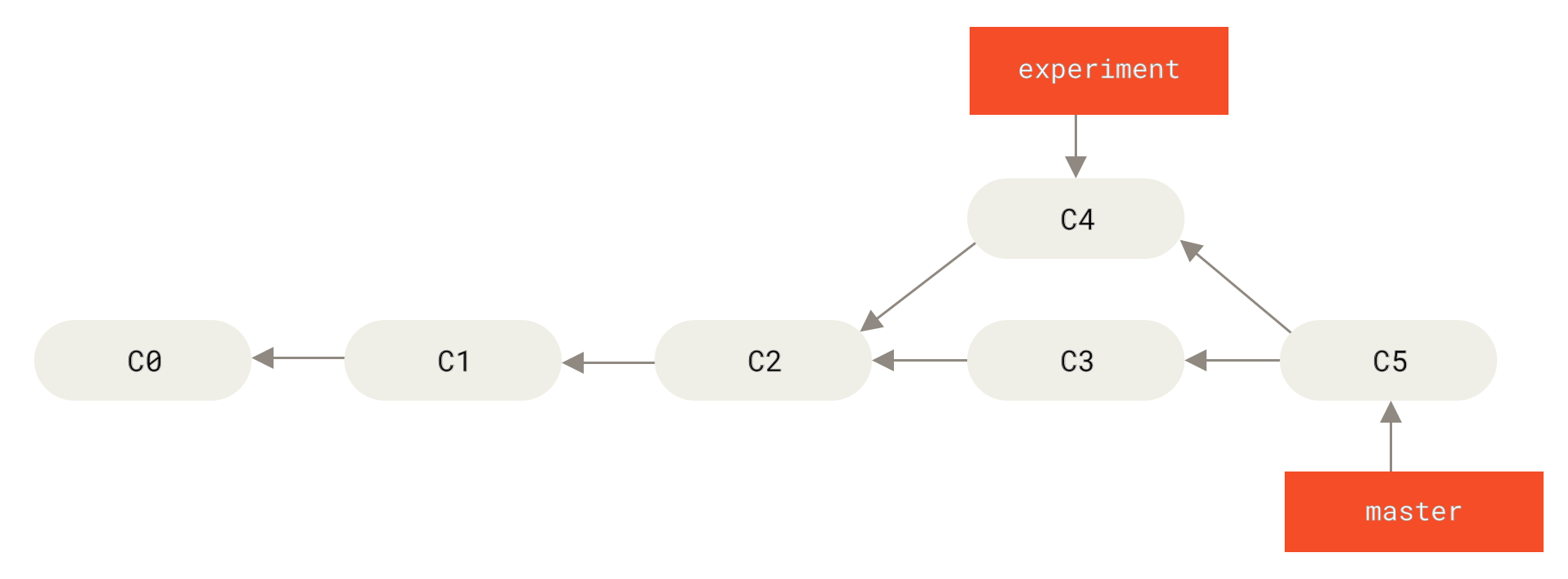
Фигура 36. Сливане за интегриране на разклонена работна история
Обаче, съществува и друг начин да направите това: можете да вземете patch на промените, които са въведени с В този пример, ще извлечете клона Това става, като се намери най-близкия общ предшестващ къмит на двата клона (този върху, който сте в момента и този, който ще пребазирате), вземат се разликите въведени от всеки къмит на клона, върху който сте, разликите се записват във временни файлове, текущият клон се ресетва към същия къмит, в който е клона, който ще се пребазира, и накрая се прилага всяка промяна поред. 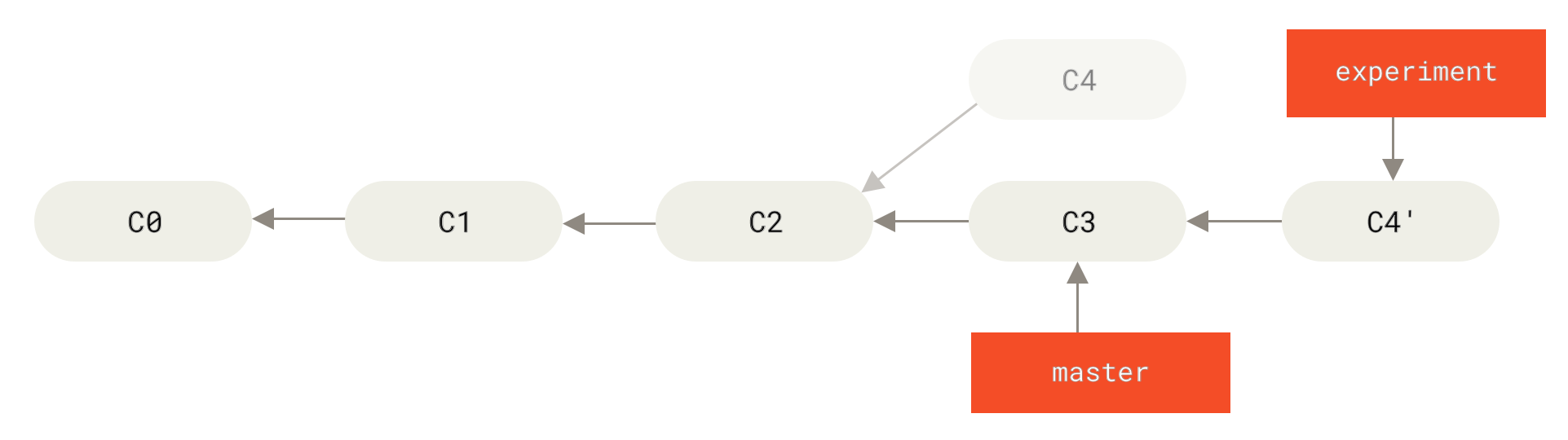
Фигура 37. Пребазиране на промяната от
C4 в C3
В този момент, можете да се върнете към 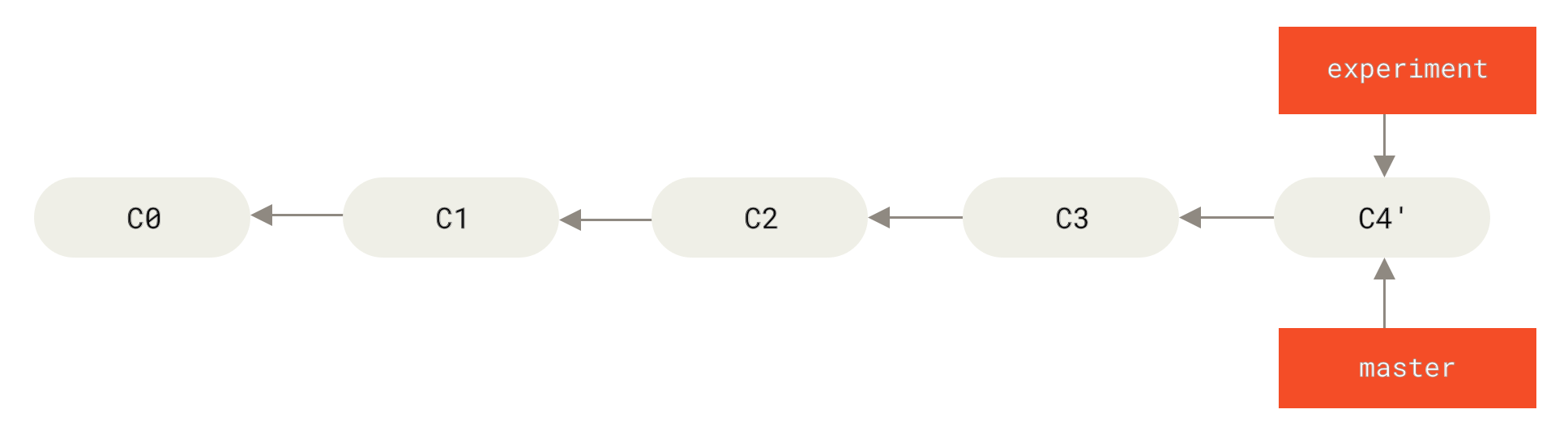
Фигура 38. Fast-forwarding на клона
master
Сега snapshot-ът, към който сочи Често ще правите това за да се уверите, че вашите къмити се прилагат безпроблемно върху отдалечен клон — вероятно проект, към който се опитвате да допринесете, но който не поддържате като автор.
В този случай, вие вършите своята дейност в собствен клон и след това пребазирате работата си върху Отбележете отново, че snapshot-ът, към който сочи финалния получил се къмит (бил той последния от пребазираните къмити за rebase или пък новосъздадения в резултат от merge) е един и същи и в двата случая — разликата е само в историята. Пребазирането прилага промените от една линия на разработка в друга по реда, в който те са били направени, докато сливането взема двата края на два клона и ги слива в едно. ==== Други интересни пребазирания Едно пребазиране може да бъде приложено и върху друг освен върху целевия му клон.
Например, вижте фигурата История с topic клон произлизащ от друг topic клон.
Създали сте един topic клон ( 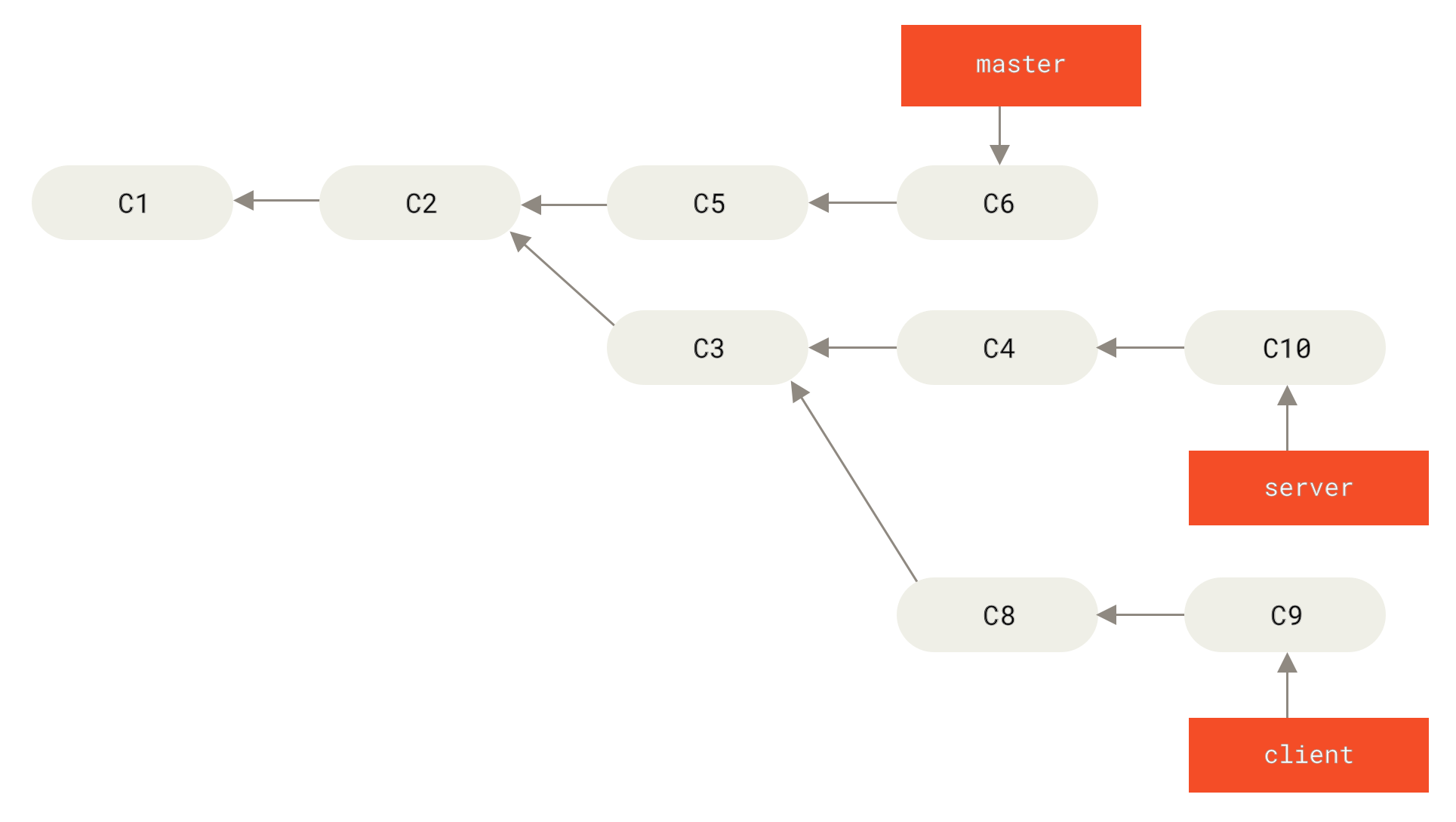
Фигура 39. История с topic клон произлизащ от друг topic клон
Да кажем, че решавате да слеете клиентските промени в Това звучи така, “Вземи клона 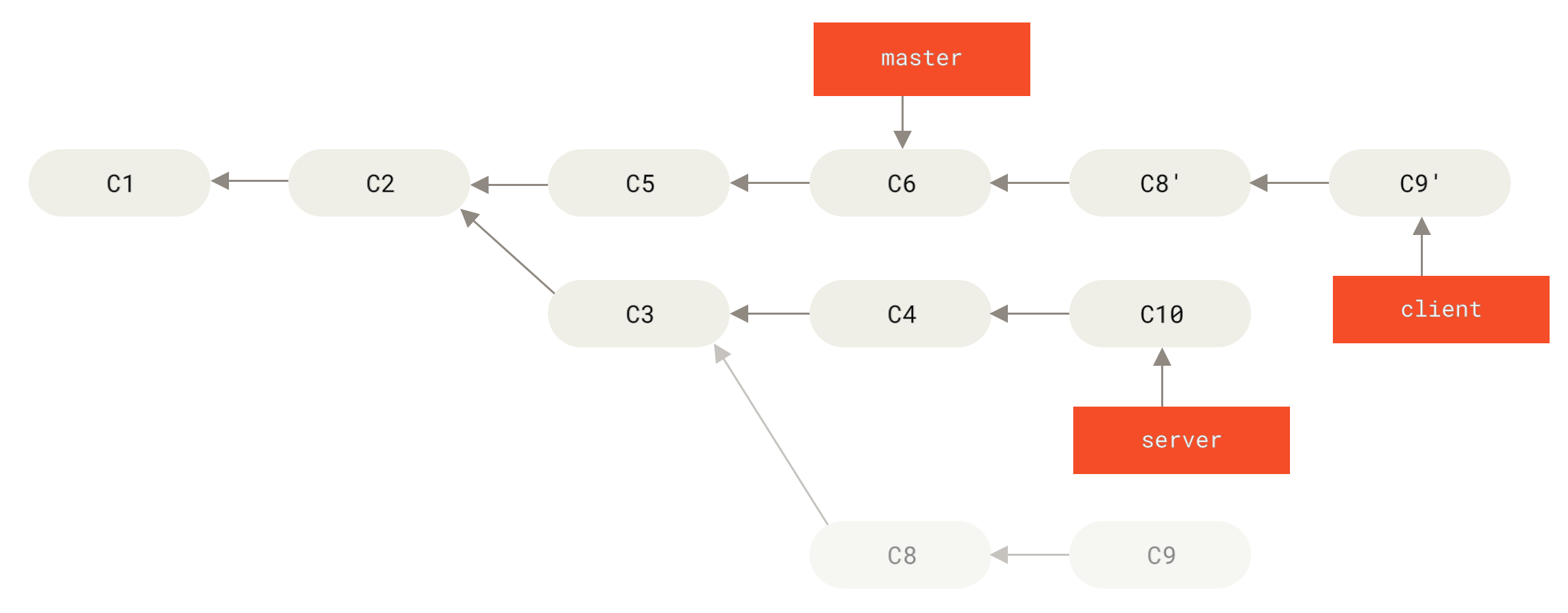
Фигура 40. Пребазиране на topic клон от друг topic branch
Сега можете да направите fast-forward на 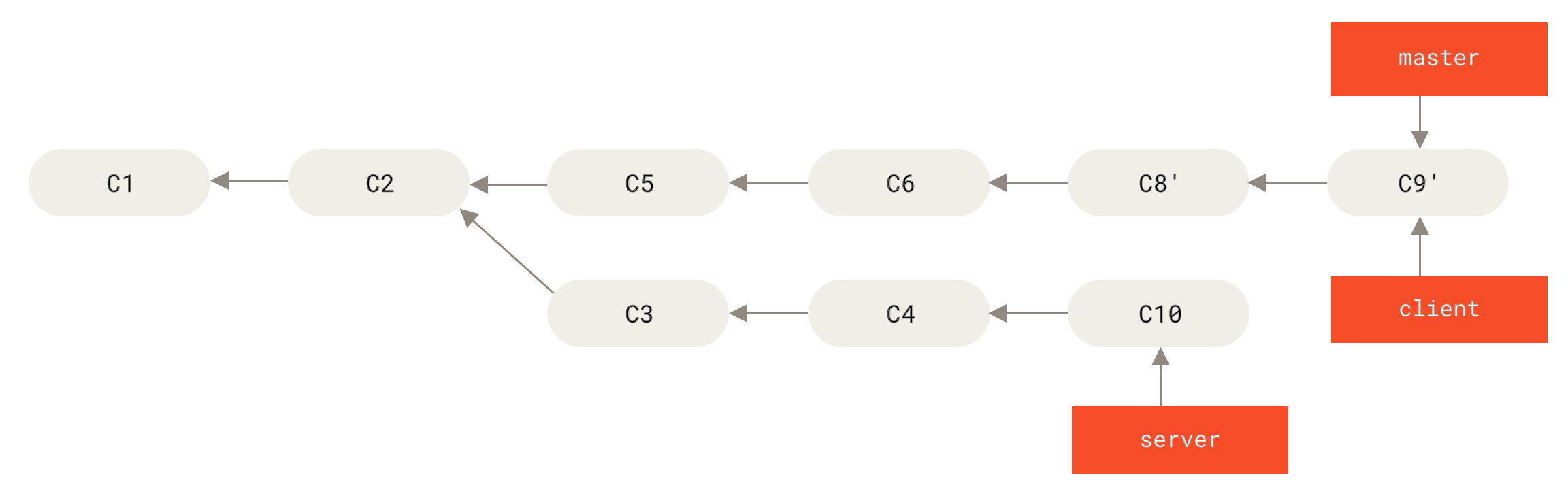
Фигура 41. Fast-forwarding на
master клона за включване на промените от клона clientНека кажем, че решите да интегрирате и промените от server клона.
Можете да пребазирате Това прилага вашите 
Фигура 42. Пребазиране на server клона в
master клонаСлед което, можете да превъртите основния клон ( Сега можете да изтриете клоновете 
Фигура 43. Историята на финалния къмит
==== Опасности при пребазиране Както можете да се досетите, пребазирането си има и недостатъци, които могат да се обобщят в едно изречение: Не пребазирайте къмити, които съществуват извън вашето собствено хранилище и върху които други хора може да са базирали работата си. Послушате ли този съвет, ще сте ОК. Не го ли направите, ще ви намразят. Когато пребазирате неща, вие зарязвате съществуващи къмити и създавате нови, които са подобни, но не съвсем същите.
Ако изпратите къмитите някъде и други ваши колеги ги издърпат и използват като изходна точка за тяхната работа, а след това вие ги презапишете с Нека видим един пример, как пребазирането на публична работа може да доведе до проблеми. Да допуснем, че клонирате от централен сървър и вършите някаква работа след това. Историята на къмитите ви изглежда по подобен начин: 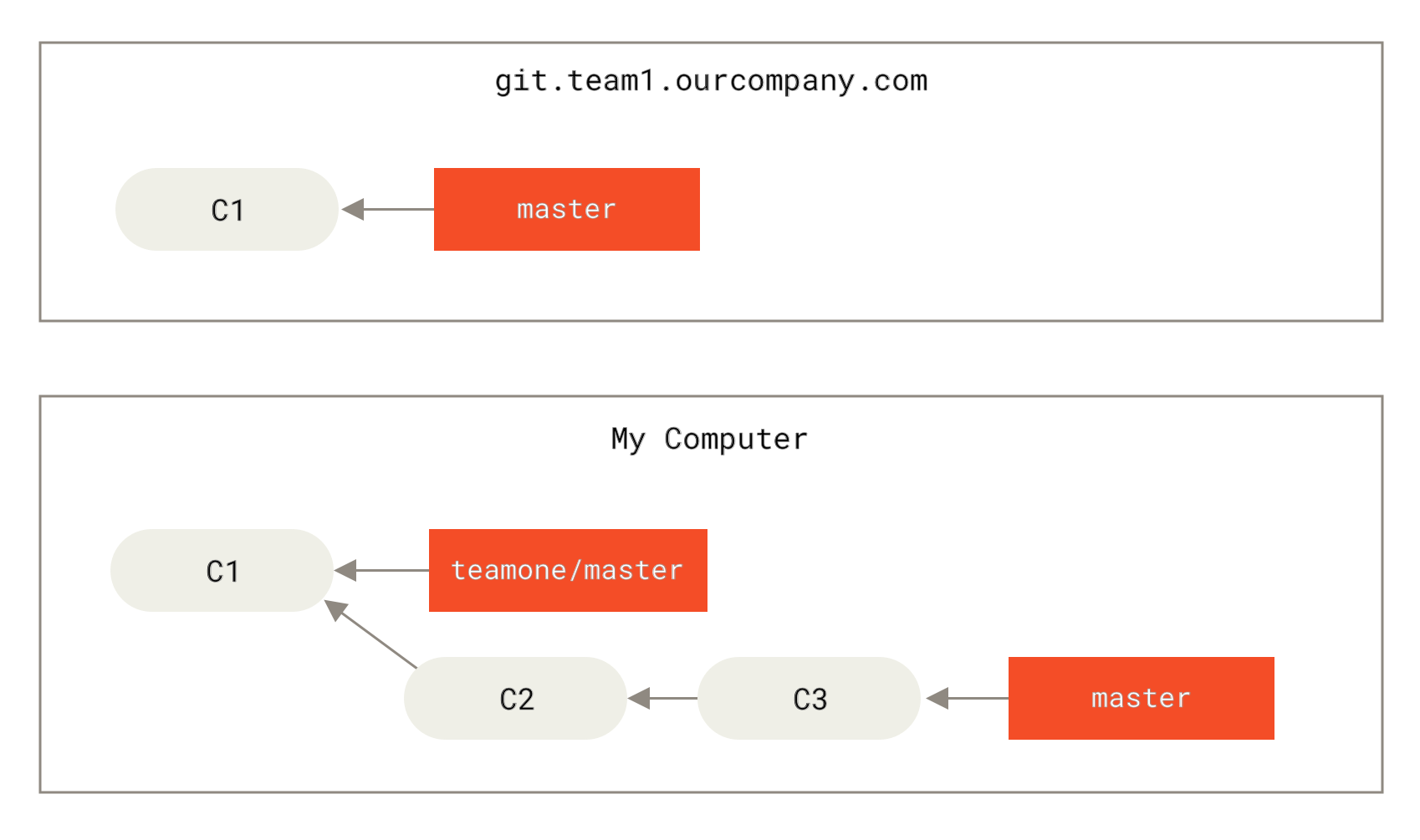
Фигура 44. Клонирайте хранилище и направете промени по него
Сега, някой друг върши друга работа, която включва сливане и я изпраща към централния сървър. Вие я издърпвате и сливате новия отдалечен клон във вашата работа, така че историята придобива подобен вид: 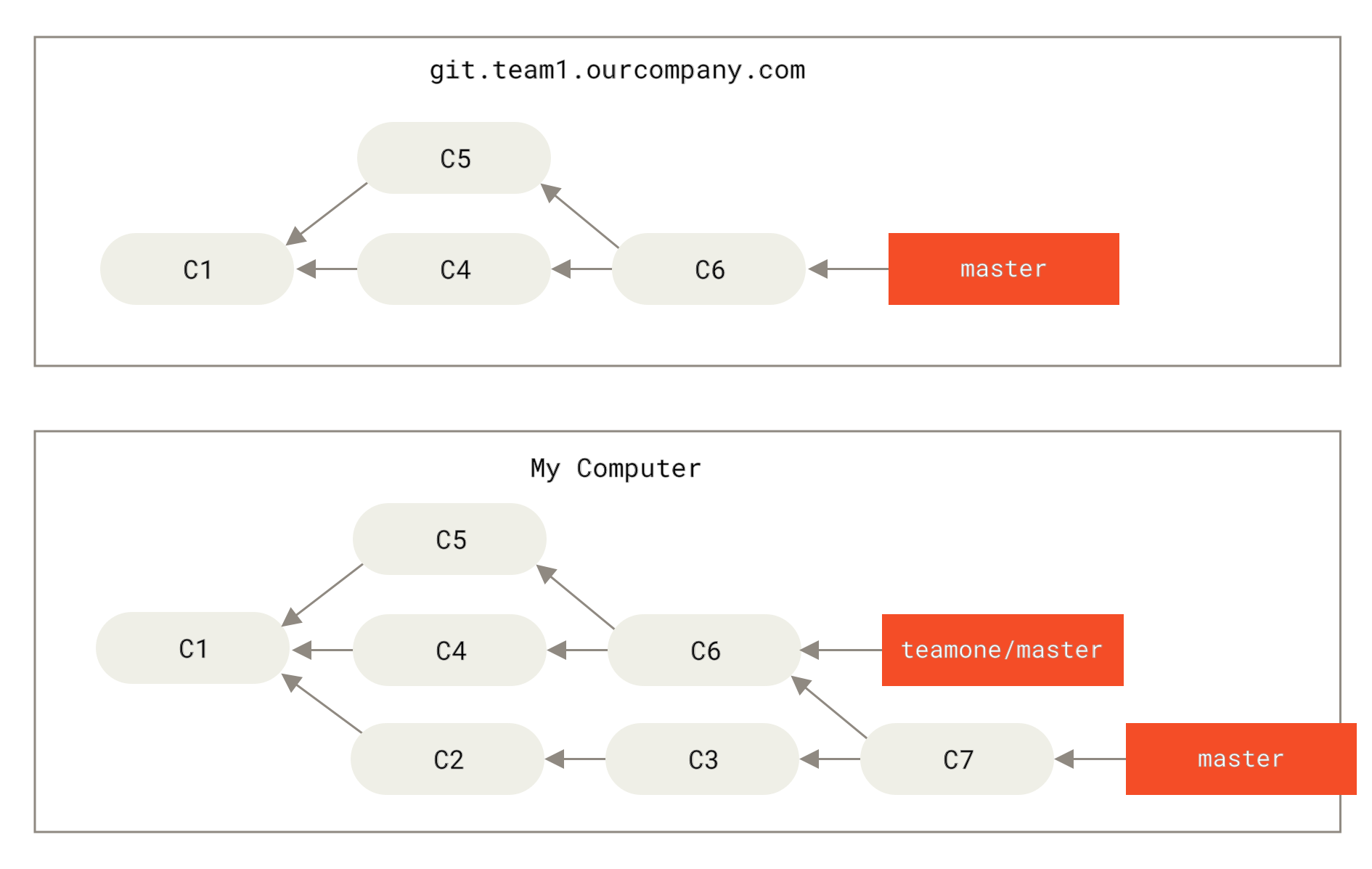
Фигура 45. Издърпвате още къмити и ги сливате във вашата работа
След това човекът, който е изпратил слетите си промени, решава да се върне назад и да пребазира работата си изпълнявайки 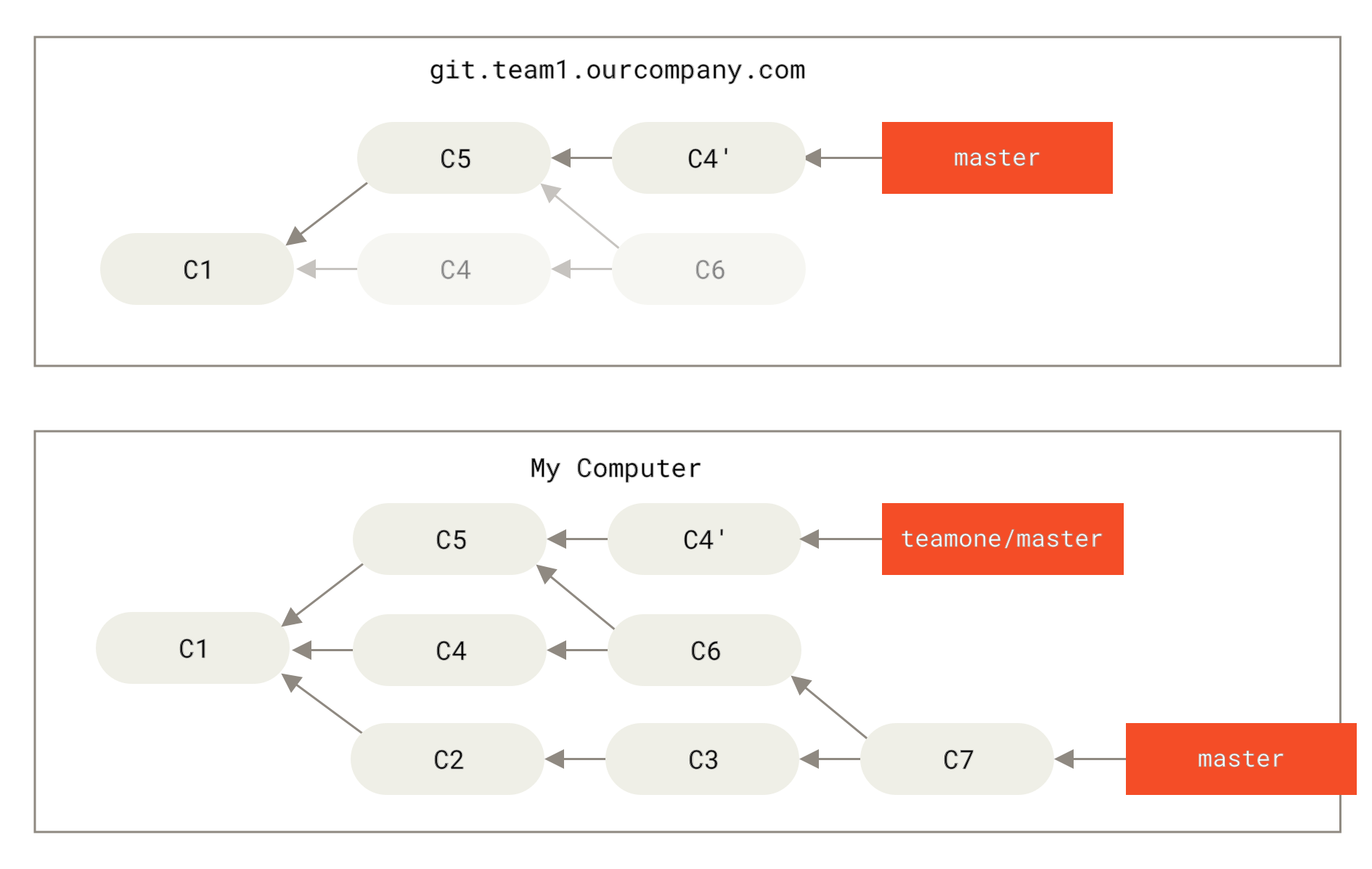
Фигура 46. Някой изпраща към сървъра пребазирани къмити, изоставяйки тези, върху които вие сте базирали работата си
Сега и двамата сте в бъркотия.
Ако направите 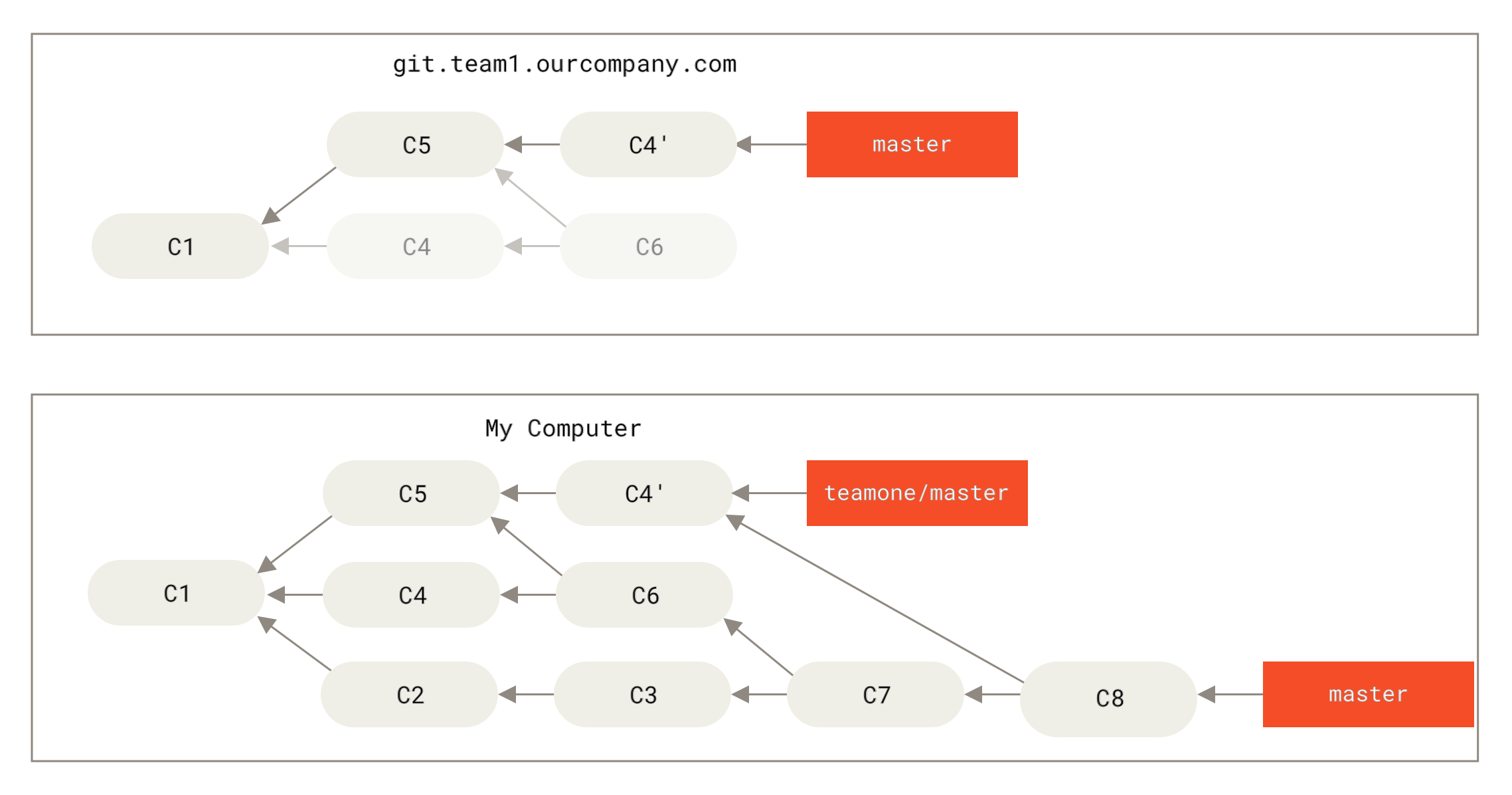
Фигура 47. Вие сливате в същата работа отново, в нов merge commit
Ако пуснете ==== Пребазиране по време на пребазиране Ако се окажете в подобна ситуация, Git разполага с допълнителни средства, които да ви помогнат. Ако някой от вашия екип форсирано изпрати промени, които презаписват нещата, които служат за база на вашата работа, трудността за вас ще е да откриете кое е ваше и какво е било презаписано. Оказва се, че в допълнение към SHA-1 чексумата на къмита, Git също така калкулира и чексума, която е базирана на поправката (patch-ът) въведена от него. Това се нарича “patch-id”. Ако издърпате работа, която е била пренаписана и я пребазирате върху новите къмити на вашия колега, Git често може успешно да определи кое е изцяло ваше и да ги приложи обратно върху новия клон. Например, в предишния сценарий, ако вместо да правим сливане докато сме в момента показан на фигурата Някой изпраща към сървъра пребазирани къмити, изоставяйки тези, върху които вие сте базирали работата си, изпълним
Така вместо резултатите, които виждаме във Вие сливате в същата работа отново, в нов merge commit, ще получим нещо приличащо повече на Пребазиране върху форсирано изпратена пребазирана работа 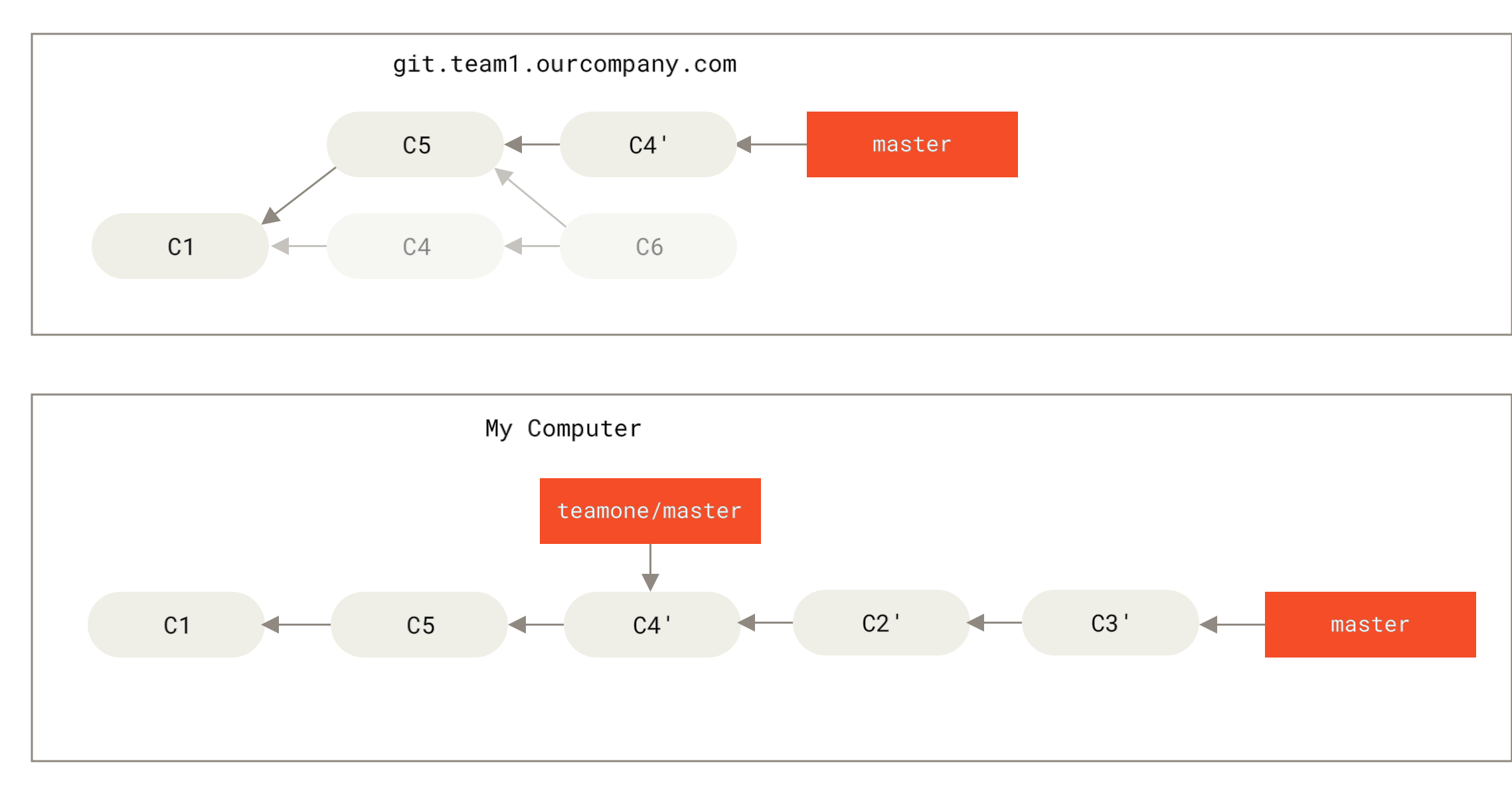
Фигура 48. Пребазиране върху форсирано изпратена пребазирана работа
Това работи само, ако Можете също така да опростите това изпълнявайки Ако използвате Ако пребазирате само къмити, които никога не са били публични, а са съществували само в локалния компютър - тогава няма да имате проблеми. Ако пребазирате публикувани вече къмити, за които знаете че никога не са използвани от някой друг - тогава също няма проблем. Ако обаче пребазирате къмити, които вече са изпратени и може би използвани като основа за работата на някой друг в екипа, тогава очаквайте много проблеми и негативно отношение в съвместната ви работа с колегите. Ако вие или ваш колега установи към даден момент, че това е необходимо - уверете се, че поне всеки знае и пуска ==== Пребазиране или сливане Сега, когато видяхте в действие пребазирането и сливането, може би се питате кое от двете е по-добро. Преди да отговорим, нека се върнем малко назад и да поговорим за това какво означава историята. Една възможна дефиниция е, че историята на къмитите във вашето хранилище е запис на това какво в действителност се е случвало. Това е исторически документ, ценен сам по себе си, който не бива да се модифицира. Погледнато по този начин, излиза че промяната на историята на къмитите е почти богохулство - вие лъжете за това какво се е случвало всъщност. А какво ще е ако имахте разхвърляни серии от merge къмити? Ами - просто така са протекли нещата и хранилището следва да пази този факт за идните поколения. Обратната гледна точка приема историята като хронология на това как проектът ви е бил създаден.
Например, не бихте публикували първата чернова на една книга и ръководството за това как да поддържате вашия софтуер заслужава внимателно редактиране.
Когато работите върху проект, може да ви трябва запис на всичките ви погрешни стъпки, но когато дойде време да споделите проекта с останалите, вероятно ще искате да покажете съвсем ясно как сте стигнали от точка А до точка В.
Това е гледната точка на поддръжниците на инструменти като Обратно на въпроса кое е по-добро, пребазирането или сливането? Надяваме се виждате и сами, че отговорът не може да е еднозначен. Git е мощна система, която ви позволява да правите много неща с историята на проекта, но няма еднакви екипи и няма еднакви проекти. Накратко, най-добрият отговор на въпроса е, че трябва сами да решите кой подход е най-добър според конретната специфична ситуация. Ако се колебаете, но искате да се възползвате от предимствата и на двата подхода, просто помнете това правило - спокойно използвайте пребазиране за локални промени, които сте направили, но не са публични. Така ще си подредите историята в чист вид. Но никога не пребазирайте нещо, което вече сте изпратили за споделено ползване. === Обобщение Разгледахме основите на разклоненията и сливанията в Git. Би следвало сега да умеете с лекота да създавате и превключвате клонове, както и да сливате локални клонове заедно. Също така, би следвало да можете да споделяте клоновете си код изпращайки ги към общ сървър, да работите с други колеги по споделени клонове код и да пребазирате вашите клонове преди споделянето им. Следва да разгледаме какви ви е необходимо за да си пуснете свой собствен хостинг сървър за Git хранилища. == Git на сървъра На този етап, би следвало да можете да вършите повечето си ежедневна работа, за която ви е нужен Git. Обаче, за да участвате с вашия труд в какъвто и да било вид съвместна работа с Git, ще ви е нужно отдалечено Git хранилище. Въпреки, че теоретично можете да пращате и издърпвате промени към хранилищата на индивидуални отделни колеги, това не е препоръчително, защото лесно можете да объркате нещата, върху които те работят, ако не сте внимателни. Освен това, вероятно искате вашите колеги да имат достъп до хранилището ви дори когато компютърът ви е без връзка с мрежата. Затова, препоръчителният начин да сътрудничите с други разработчици е да настроите междинно хранилище, към което да имат достъп всички, и да теглите и изпращате код през него. Да пуснете Git сървър е сравнително лесно. Първо, избирате протоколите, които желаете той да поддържа за комуникация с клиентите. Първата секция от тази глава ще разгледа наличните протоколи в едно с предимствата и недостатъците им. Следващите части ще обяснят някои типични настройки свързани с тези протоколи. Накрая, ще преминем през няколко хоствани опции, в случай че нямате нищо против кода ви да се съхранява на външен сървър и не ви се занимава с настройката и поддръжката на собствен такъв. Ако е така, можете да преминете директно към последната част на тази глава, за да разгледате какви са опциите за създаване на хостван акаунт и след това да разгледате следващата глава, където дискутираме предимствата и недостатъците на това да работите в distributed source control среда. Отдалеченото хранилище накратко казано е bare repository –- Git хранилище без работна директория.
Понеже то се ползва само като обща точка за сътрудничество между членовете на екипа, няма необходимост в него да има snapshot от данните разположен на диска, там присъстват само Git данните.
Казано възможно най-просто, едно голо (bare) хранилище има само съдържанието на директорията === Комуникационни протоколи Git може да използва 4 основни протокола за трансфер на данни: локален, HTTP, Secure Shell (SSH) и Git. Сега ще погледнем какво представляват те и по какви причини бихте желали да ги използвате (или избягвате). ==== Локален протокол Най-простият от четирите е локалният протокол, при който отдалеченото хранилище се намира просто в друга директория на диска. Това често се ползва, ако всички в екипа ви имат достъп до споделена файлова система от рода на NFS споделено устройство или пък, в по-редки случаи, когато всички се логват на един и същи компютър. Последното не е препоръчително, защото всички копия на хранилището ще се пазят на едно място и рискът от загубата на данни при хардуерна повреда е значително по-голям. Ако имате споделена монтирана файлова система, тогава вие клонирате, изпращате и изтегляте данни от локално, файлово-базирано хранилище. За да клонирате хранилище от този вид или за да добавите такова като отдалечено към съществуващ проект, използвайте пътя до хранилището вместо URL. Например, за да клонирате, може да изпълните нещо подобно: Или пък така: Git работи малко по-различно ако изрично укажете За да добавите локално хранилище като remote към съществуващ Git проект, можете да направите това: След това, можете да изпращате и издърпвате от него използвайки името му ===== Предимствата Предимствата на файл-базираните хранилища са в това, че са прости и използват наличните права за файловете и мрежовия достъп. Ако вече имате споделена файлова система, до която има достъп целия ви екип, създаването на хранилище е много просто. Пазите копие от bare хранилището някъде, където всички имат достъп и задавате права за чете и писане като на всяка друга споделена директория. Ще дискутираме как да експортирате копие от хранилището като bare копие за целта в [_getting_git_on_a_server]. Това също е полезен начин за бързо изтегляне на работата на друг човек от неговото работещо хранилище.
Ако с ваш колега работите по един и същи проект и той поиска да погледнете нещо по неговата работа, то една команда от рода на ===== Недостатъци Неудобствата при този подход се състоят в това, че споделеният достъп в повечето случаи се настройва и достъпва от различни локации по-трудно в сравнение със стандартния мрежов достъп. Ако искате да изпратите данни от домашния си лаптоп, докато сте вкъщи, ще трябва да монтирате отдалечения диск, което често може да е трудно и досадно бавно. Също така трябва да посочим, че локалният протокол не винаги е най-бързата опция, ако използвате споделен монтиран ресурс от някои видове. Локалното хранилище е бързо само, ако имате бърз достъп до данните. Едно хранилище разположено върху NFS ресурс често е по-бавно от SSH такова на същия сървър (което освен това позволява на Git да работи през локалните дискове на всеки от компютрите). Накрая, този протокол не защитава хранилището от непредвидени поражения. Всеки потребител разполага с пълен шел достъп до “отдалеченото” хранилище и нищо не пречи на един невнимателен колега да промени или изтрие служебни Git файлове, което от своя страна да повреди цялото хранилище. ==== HTTP протоколите Git може да работи през HTTP в два различни режима. Преди Git версия 1.6.6, начинът беше само един и то доста опростен и в общия случай - read-only. С тази версия обаче, беше представен нов, по-усъвършенстван протокол, който позволява на Git интелигентно да уговаря транфера на данни по маниер подобен на този, който се използва през SSH. В последните няколко години този нов HTTP протокол придоби голяма популярност, защото е по-прост за потребителя и по-интелигентен в механизма на комуникация. Тази нова версия често е наричана Smart HTTP протокол, докато старата е известна като Dumb HTTP. Ще разгледаме първо smart HTTP протокола. ===== Smart HTTP Протоколът smart HTTP работи много подобно на SSH или Git протоколите, но използва стандартните HTTP/S портове и може да използва различни механизми за HTTP автентикация, което често го прави по-лесен за много потребители, защото можете да използвате неща като оторизиране с име и парола, вместо създаване на SSH ключове. Този протокол в момента е най-популярния начин за използване в Git, понеже може да работи както анонимно, подобно на протокола На практика, в услуги като GitHub, URL-ът който ползвате за да разглеждате хранилището в браузъра (например, https://github.com/schacon/simplegit) е същият URL, който можете да използвате за клонирането му или пък за изпращане на промени към него (ако имате права за това). ===== Dumb HTTP
Ако сървърът не разполага с Git HTTP smart услуга, Git клиентът ще се опита да използва протокола dumb HTTP.
Този вид комуникация очаква bare Git хранилището да се обслужва като нормални файлове от уеб сървъра.
Красотата на dumb протокола се крие в простотата на настройката му.
В общи линии, всичко което трябва да направите е да копирате едно bare Git хранилище там където уеб сървърът има достъп и да настроите специфичен Това е всичко.
Инструментът В този специфичен случай, ние използваме Kато обобщение, имате два избора, да пуснете read/write Smart HTTP сървър или read-only такъв с Dumb HTTP. Рядко се случва да се прави комбинация от двете. ===== Предимствата Ще разгледаме предимствата на Smart HTTP версията на протокола. Простотата да имате единичен URL за всички видове достъп и да оставите сървърът да пита за име и парола, когато се налага, прави нещата много по-лесни за крайния потребител. Възможността за оторизация с име и парола е голямо предимство сравнена с SSH, защото потребителите няма нужда да генерират SSH ключове локално и да изпращат публичния си ключ към сървъра преди да могат да комуникират с него. За по-неопитните потребители или за потребителите на системи, в които SSH не се ползва интензивно, това може да бъде голямо улеснение по отношение на лекотата на ползване. В допълнение, протоколът е бърз и ефективен, подобно на SSH. Можете също да обслужвате хранилищата си само за четене през HTTPS, което значи че можете да криптирате съдържанието на трансфера или дори да стигнете и до по-рестриктивни мерки, като например да изисквате от клиентите да използват специфични signed SSL сертификати. Друго предимство е и факта, че HTTP и HTTPS са толкова разпространени протоколи, че корпоративните защитни стени често вече са настроени да пропускат трафика през техните портове. ===== Недостатъци Git през HTTP/S може да е една идея по-сложен за настройване в сравнение с SSH на някои сървъри. Отделно от това, съществува съвсем леко предимство, което другите протоколи за обслужване на Git имат, в сравнение със Smart HTTP. Ако използвате HTTP за автентикирано изпращане на промени към хранилището, изпращането на името и паролата понякога може да е малко по-сложно отколкото използването на SSH ключове. Обаче, съществуват няколко credential caching инструменти, които можете да ползвате, включително Keychain access на OSX или Credential Manager под Windows, за да си улесните нещата. Погледнете Credential Storage система за да видите как да настроите системата за защитено кеширане на HTTP пароли. ==== SSH протоколът Често използван протокол за Git при self-hosting инсталации е SSH. Това е защото SSH достъпът до сървърите е много разпространен и настроен на повечето от тях - а и да не е, лесно може да се пусне. SSH също така е автентикиран мрежов протокол, повсеместно използван и лесно управляем. За да клонирате Git хранилище през SSH, използвайте Или, може да предпочетете съкратения, подобен на scp синтаксис: И в двата случая отгоре, ако не укажете потребителско име, Git ще използва това, с което сте логнати в системата. ===== Предимствата Предимствата на SSH са много. Първо, SSH е сравнително лесен за настройка - SSH демоните са често използвани и познати, повечето системни администратори имат опит с тях и повечето OS дистрибуции идват с настроен SSH или имат съответните средства за настройка и управление на SSH комуникация. След това, комуникацията е сигурна - целият трансфер през SSH е криптиран и оторизиран. Последно, подобно на HTTP/S, Git и Local протоколите, SSH е ефективен и прави данните максимално компактни преди да ги изпрати. ===== Недостатъци Негативната страна на SSH е, че не можете да имате анонимен достъп. Потребителите трябва да имат достъп до машината ви през SSH, за да се доберат до хранилището ви, дори и в режим само за четене, което не прави SSH толкова подходящ за проекти с отворен код. Ако го използвате само в рамките на корпоративната мрежа, SSH може да е единственият протокол, с който се налага да работите. Ако искате да позволите анонимен достъп само за четене до вашите проекти и същевременно искате да ползвате SSH, ще трябва да настроите SSH за вас, за да изпращате до хранилището, но за колегите, които ще теглят - ще трябва да настроите друг метод. ==== Git протокол
Следва протоколът Git.
Той е реализиран чрез специален daemon, който идва заедно с Git, слуша на специфичен порт (9418) и осигурява услуга подобна на тази на SSH, но без абсолютно никаква автентикация.
Ако искате хранилището ви да е достъпно през този протокол, трябва да създадете файл ===== Предимства Git протоколът често е най-бързия мрежов протокол. Ако обслужвате голям трафик за публичен проект, или пък проектът е много голям и не изисква автентикация за четене, вероятно ще си заслужава да пуснете Git daemon. Той използва същия механизъм за трансфер на данни като SSH, но без забавянето за криптиране и автентикация. ===== Недостатъци Недостатъкът на Git протокола е липсата на автентикация.
Като цяло е нежелателно Git протоколът да е единствения протокол за достъп до вашия проект.
В повечето случаи, може да го ползвате в комбинация с SSH или HTTPS за достъп от ваши сътрудници, които трябва да имат права за запис в хранилището, а всички останали - read-only достъп през === Достъп до Git на сървъра Сега ще разгледаме настройката на Git услуга, ползваща тези протоколи на ваш собствен сървър. |
Тук ще демонстрираме командите и стъпките за базови опростени инсталации на Linux базиран сървър, но разбира се, възможно е това да стане на macOS и Windows машини. В действителност, изграждането на production сървър в рамките на вашата инфраструктура ще изисква различни стъпки по отношение на мерките за сигурност или според конкретните инструменти на операционната ви система, но да се надяваме, че тези стъпки ще ви дадат първоначална насока за това какво се изисква.
Като първа стъпка, за да получите Git на сървъра, ще трябва да експортирате налично хранилище в ново, bare хранилище - това е хранилище, което не съдържа работна директория.
Това обикновено е съвсем лесно.
Използвайте командата за клониране с параметър --bare.
По конвенция, директориите за bare хранилището завършват на .git, например така:
$ git clone --bare my_project my_project.git
Cloning into bare repository 'my_project.git'...
done.Сега трябва да имате копие от Git директорията във вашата директория my_project.git.
Това е приблизително еквивалентно на резултата от командата:
$ cp -Rf my_project/.git my_project.gitСъществуват някои незначителни разлики в конфигурационния файл, но за нашите цели резултатът е почти един и същ. Командата взема Git хранилището, без работната му директория и създава директория специално за него.
==== Изпращане на Bare хранилище към сървъра
След като вече имате копие на хранилището, всичко което трябва да сторите е да го копирате на сървъра и да настроите съответния протокол/протоколи за достъп.
Нека кажем, че имате сървър наречен git.example.com, към който имате SSH достъп и искате да пазите всичките си Git хранилища в директорията /srv/git.
Като приемаме, че /srv/git съществува на сървъра, можете да създадете ново хранилище копирайки наличното такова:
$ scp -r my_project.git user@git.example.com:/srv/gitВ този момент, другите потребители с SSH достъп до същия сървър и права за четене към /srv/git директорията му, вече могат да клонират вашето хранилище изпълнявайки:
$ git clone user@git.example.com:/srv/git/my_project.gitАко някой от тях има и права за писане до директорията /srv/git/my_project.git, то той ще има автоматично и push права до хранилището.
Git автоматично ще добави group write права до хранилището по коректен начин, ако изпълните git init с параметъра --shared.
Изпълнението на тази команда не унищожава никакви къмити, референции или други обекти
$ ssh user@git.example.com
$ cd /srv/git/my_project.git
$ git init --bare --sharedВиждате колко лесно е да вземете Git хранилище, да създадете bare версия и да го поставите в сървър, към който колегите ви имат SSH достъп. Сега сте готови да работите съвместно по проекта.
Важно е да посочим, че това буквално е всичко, от което имате нужда за да пуснете използваем Git сървър - просто добавете акаунти с SSH достъп за колегите ви и копирайте едно bare хранилище там, където те имат права за четене и писане. Сега сте готови, не трябва нищо повече.
В следващите секции ще видим как да направим по-модерни конфигурации. Ще направим обзор на това как да настроите нещата така, че да не се нуждаете от отделни акаунти за всеки потребител, как да добавим публичен достъп за четене до хранилища, настройване на уеб потребителски интерфейси и др. Обаче, просто помнете, че това са допълнения - всичко, което ви трябва за да работите съвместно по частен проект е SSH сървър и bare хранилище.
==== Малки конфигурации
Ако сте малък екип или просто тествате Git във вашата организация и имате само няколко разработчика, нещата могат да са простички за вас. Един от най-сложните аспекти в настройката на Git сървъра е управлението на потребителите. Ако искате някои хранилища да са само за четене за определени потребители, а други да са достъпни за писане, то настройките на достъпа и съответните права могат да са по-трудни за наместване.
===== SSH достъп
Ако имате сървър, към който всичките ви колеги имат SSH достъп, най-лесно е да разположите хранилищата си в него, защото както видяхме в предната секция - няма да имате почти никаква работа по настройките. Ако искате по-комплексен контрол на достъпа, можете да се справите с нормалните средства за достъп до файловата система, които операционната система предлага.
Ако искате да разположите хранилищата си на сървър, който няма акаунти за всички в екипа ви, за които допускате, че ще е нужен достъп с права за писане, тогава трябва да настроите SSH достъп за тях. Допускаме, че ако имате сървър с който да правите това, вече имате инсталиран SSH за достъп до него.
Има няколко начина да дадете достъп на всеки от екипа.
Първо, можете да създадете акаунти за всички колеги, което е лесно, но може да е досадно.
Може да не искате да изпълнявате adduser/useradd и да правите временни пароли за всеки колега.
Втори начин е да създадете единичен 'git' потребител на машината, да помолите всеки ваш колега, който трябва да има права за писане да ви изпрати свой SSH публичен ключ, и да добавите ключовете във файла ~/.ssh/authorized_keys на потребителя 'git'.
Така всеки от колегите ви ще има достъп до машината през потребителското име 'git'.
Това не засяга по никакъв начин commit данните — SSH потребителят, с който се свързвате към машината не се отразява на записаните къмити.
Друг начин е да настроите вашия SSH сървър да автентикира потребителите през LDAP сървър или някакъв друг централизиран източник за автентикация, който може да имате. Докато всеки от потребителите може да получи шел-достъп на машината, всеки SSH оторизационен механизъм за който се сещате, би трябвало да работи.
=== Генериране на SSH публичен ключ
Много Git сървъри автентикират достъпа ползвайки SSH публични ключове.
За да осигури такъв ключ, всеки потребител на системата ви трябва първо да си го генерира.
Процесът е подобен за всички операционни системи.
Първо, трябва да проверите дали вече нямате ключ.
По подразбиране, генерираните от потребителя SSH ключове се пазят в директория ~/.ssh в домашната му папка.
Може лесно да проверите дали имате ключове като просто отворите директорията и покажете съдържанието ѝ:
$ cd ~/.ssh
$ ls
authorized_keys2 id_dsa known_hosts
config id_dsa.pubТърсите чифт файлове с имена от рода на id_dsa или id_rsa и съответен файл с разширение .pub.
Файлът с разширение .pub е публичният ви ключ, а другият е секретния.
Ако нямате тези файлове (или дори не разполагате с .ssh директория), можете да ги създадете с програмата ssh-keygen, която идва с пакета SSH под Linux/macOS и също така с Git for Windows:
$ ssh-keygen -o
Generating public/private rsa key pair.
Enter file in which to save the key (/home/schacon/.ssh/id_rsa):
Created directory '/home/schacon/.ssh'.
Enter passphrase (empty for no passphrase):
Enter same passphrase again:
Your identification has been saved in /home/schacon/.ssh/id_rsa.
Your public key has been saved in /home/schacon/.ssh/id_rsa.pub.
The key fingerprint is:
d0:82:24:8e:d7:f1:bb:9b:33:53:96:93:49:da:9b:e3 schacon@mylaptop.localПрограмата първо пита къде да съхранява ключа (.ssh/id_rsa) и след това пита два пъти за парола, която можете да оставите празна, ако не желаете да я въвеждате всеки път, когато използвате ключа.
Обаче, ако използвате парола, уверете се че сте добавили флага -o; това ще съхрани частния ключ във формат, който е по-устойчив на brute-force атаки за пароли в сравнение с формата по подразбиране.
Може също да използвате ssh-agent инструмента за да избегнете въвеждането на паролата всеки път.
След това, всеки потребител трябва да изпрати публичния си ключ на вас или който администрира Git сървъра (подразбираме, че използвате схема, при която SSH сървърът изисква публични ключове).
Всичко което трябва да се направи е да се копира съдържанието на .pub файла и да се изпрати по имейл.
Публичните ключове изглеждат по подобен начин:
$ cat ~/.ssh/id_rsa.pub
ssh-rsa AAAAB3NzaC1yc2EAAAABIwAAAQEAklOUpkDHrfHY17SbrmTIpNLTGK9Tjom/BWDSU
GPl+nafzlHDTYW7hdI4yZ5ew18JH4JW9jbhUFrviQzM7xlELEVf4h9lFX5QVkbPppSwg0cda3
Pbv7kOdJ/MTyBlWXFCR+HAo3FXRitBqxiX1nKhXpHAZsMciLq8V6RjsNAQwdsdMFvSlVK/7XA
t3FaoJoAsncM1Q9x5+3V0Ww68/eIFmb1zuUFljQJKprrX88XypNDvjYNby6vw/Pb0rwert/En
mZ+AW4OZPnTPI89ZPmVMLuayrD2cE86Z/il8b+gw3r3+1nKatmIkjn2so1d01QraTlMqVSsbx
NrRFi9wrf+M7Q== schacon@mylaptop.localЗа повече информация и детайлно упътване за създаване на SSH ключове на множество операционни системи, погледнете GitHub SSH keys страницата на адрес https://docs.github.com/en/github/authenticating-to-github/generating-a-new-ssh-key-and-adding-it-to-the-ssh-agent.
=== Настройка на сървъра
Нека преминем през настройката на SSH достъпа от страна на сървъра.
В този пример, ще използвате метода authorized_keys за автентикиране на вашите потребители.
Подразбираме също така, че използвате стандартна Linux дистрибуция, например Ubuntu.
Голяма част от описаното тук може да се автоматизира с командата ssh-copy-id, вместо чрез ръчно копиране и инсталиране на публични ключове.
Първо, създавате git потребител и .ssh директория за него.
$ sudo adduser git
$ su git
$ cd
$ mkdir .ssh && chmod 700 .ssh
$ touch .ssh/authorized_keys && chmod 600 .ssh/authorized_keysСлед това, трябва да добавите няколко публични ключа на разработчици към файла authorized_keys на потребителя git.
Нека кажем, че имате няколко такива ключа и ги съхранявате във временни файлове.
Да припомним, публичните ключове изглеждат така:
$ cat /tmp/id_rsa.john.pub
ssh-rsa AAAAB3NzaC1yc2EAAAADAQABAAABAQCB007n/ww+ouN4gSLKssMxXnBOvf9LGt4L
ojG6rs6hPB09j9R/T17/x4lhJA0F3FR1rP6kYBRsWj2aThGw6HXLm9/5zytK6Ztg3RPKK+4k
Yjh6541NYsnEAZuXz0jTTyAUfrtU3Z5E003C4oxOj6H0rfIF1kKI9MAQLMdpGW1GYEIgS9Ez
Sdfd8AcCIicTDWbqLAcU4UpkaX8KyGlLwsNuuGztobF8m72ALC/nLF6JLtPofwFBlgc+myiv
O7TCUSBdLQlgMVOFq1I2uPWQOkOWQAHukEOmfjy2jctxSDBQ220ymjaNsHT4kgtZg2AYYgPq
dAv8JggJICUvax2T9va5 gsg-keypairПросто трябва да ги добавите към authorized_keys файла на потребителя git в .ssh директорията му:
$ cat /tmp/id_rsa.john.pub >> ~/.ssh/authorized_keys
$ cat /tmp/id_rsa.josie.pub >> ~/.ssh/authorized_keys
$ cat /tmp/id_rsa.jessica.pub >> ~/.ssh/authorized_keysСега можете да инициализирате празно хранилище за тях изпълнявайки git init с опцията --bare, което ще създаде хранилище без работна директория:
$ cd /srv/git
$ mkdir project.git
$ cd project.git
$ git init --bare
Initialized empty Git repository in /srv/git/project.git/След като направите това, John, Josie, или Jessica могат да изпратят първата версия на своя проект в това хранилище като го добавят като отдалечено и изпратят някой клон.
Отбележете, че е необходимо някой да се логва в тази машина и да създава празно хранилище всеки път, когато искате да добавите проект.
Нека ползваме gitserver за име на сървъра, който настроихме.
Ако го използвате само локално и настроите DNS сървъра си да сочи към адреса му, тогава може да използвате командите буквално така (подразбираме, че myproject е съществуващ проект с файлове):
# от компютъра на John
$ cd myproject
$ git init
$ git add .
$ git commit -m 'Initial commit'
$ git remote add origin git@gitserver:/srv/git/project.git
$ git push origin masterСега вече другите могат да клонират проекта и да изпращат промени към него също така лесно:
$ git clone git@gitserver:/srv/git/project.git
$ cd project
$ vim README
$ git commit -am 'Fix for README file'
$ git push origin masterПолзвайки този подход можете лесно да пуснете read/write Git сървър за малък екип разработчици.
Следва да сте забелязали, че сега всички тези потребители могат също така да се логнат на сървъра като потребител git.
Ако искате да ограничите това, ще трябва да смените шела на git с нещо различно във файла /etc/passwd.
Можете лесно да ограничите git потребителя само до Git дейности с рестриктивния инструмент git-shell, който идва с Git.
Ако го използвате за login шел за вашия git потребител, то той ще има доста по-ограничени права в сървъра.
Просто използвайте git-shell вместо bash или csh за шел на потребителя.
За да го направите, първо трябва да добавите git-shell към /etc/shells, ако той вече не е там:
$ cat /etc/shells # проверявате дали git-shell е вече във файла и ако не е...
$ which git-shell # уверете се, че git-shell е инсталиран на системата
$ sudo -e /etc/shells # и добавете пътя до него, който показва командата whichСега можете да редактирате шела за даден потребител изпълнявайки chsh <username> -s <shell>:
$ sudo chsh git -s $(which git-shell)Сега вече git потребителят може да използва SSH комуникация само за да изтегля и изпраща Git хранилища и няма да има пълноценен шел достъп в машината.
Ако пробвате, ще получите отказ:
$ ssh git@gitserver
fatal: Interactive git shell is not enabled.
hint: ~/git-shell-commands should exist and have read and execute access.
Connection to gitserver closed.В този момент обаче, потребителите все още могат да използват SSH port forwarding за достъп до всеки хост, който git сървърът вижда.
Ако искате да избегнете това, може да редактирате файла authorized_keys и да добавите следните опции за всеки ключ, който искате да ограничите:
no-port-forwarding,no-X11-forwarding,no-agent-forwarding,no-ptyРезултатът трябва да изглежда така:
$ cat ~/.ssh/authorized_keys
no-port-forwarding,no-X11-forwarding,no-agent-forwarding,no-pty ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQCB007n/ww+ouN4gSLKssMxXnBOvf9LGt4LojG6rs6h
PB09j9R/T17/x4lhJA0F3FR1rP6kYBRsWj2aThGw6HXLm9/5zytK6Ztg3RPKK+4kYjh6541N
YsnEAZuXz0jTTyAUfrtU3Z5E003C4oxOj6H0rfIF1kKI9MAQLMdpGW1GYEIgS9EzSdfd8AcC
IicTDWbqLAcU4UpkaX8KyGlLwsNuuGztobF8m72ALC/nLF6JLtPofwFBlgc+myivO7TCUSBd
LQlgMVOFq1I2uPWQOkOWQAHukEOmfjy2jctxSDBQ220ymjaNsHT4kgtZg2AYYgPqdAv8JggJ
ICUvax2T9va5 gsg-keypair
no-port-forwarding,no-X11-forwarding,no-agent-forwarding,no-pty ssh-rsa
AAAAB3NzaC1yc2EAAAADAQABAAABAQDEwENNMomTboYI+LJieaAY16qiXiH3wuvENhBG...Сега мрежовите команди на Git ще работят нормално, но потребителите няма да имат шел достъп.
Както се вижда от изхода на командата, можете също така да направите директория в домашната такава на потребителя git, което ще специализира малко git-shell командата.
Например, можете да ограничите наличните Git команди, които сървърът приема или да промените съобщението, които потребителите виждат, ако се опитат да се логнат през SSH.
Изпълнете git help shell за повече информация за настройване на шела.
=== Git Daemon
Следващата стъпка е да настроим демон, който обслужва хранилища чрез “Git” протокола. Това е често срещан избор за бърз достъп до вашите Git данни, без автентикация. Помнете, че в този случай данните ви са публично достъпни в рамките на съответната мрежа.
Ако използвате протокола на сървър извън защитната стена, това следва да става само за публично достъпни проекти. Ако сте зад защитна стена обаче, бихте могли да го ползвате за проекти, до които достъп за четене трябва да имат голям брой сътрудници и за които не желаете да настройвате SSH ключове поотделно.
Независимо от случая, Git протоколът е сравнително лесен за настройка. В общи линии, трябва да изпълните долната команда в daemonized режим:
$ git daemon --reuseaddr --base-path=/srv/git/ /srv/git/Опцията --reuseaddr позволява сървърът да се рестартира без да изчаква таймаут на старите конекции, а --base-path позволява на хората да клонират проекти без да трябва да указват пълния път. Пътят в края на командата указва на Git демона къде да следи за хранилища за експорт.
Ако използвате защитна стена, ще трябва също така да разрешите достъпа до порт 9418 на сървъра.
Пускането на демона може да се прави по различни начини в зависимост от използваната операционна система.
Понеже systemd вече е най-разпространената init система в модерните Linux дистрибуции, бихте могли да я ползвате за целта.
Просто създайте файл /etc/systemd/system/git-daemon.service със следното съдържание:
[Unit]
Description=Start Git Daemon
[Service]
ExecStart=/usr/bin/git daemon --reuseaddr --base-path=/srv/git/ /srv/git/
Restart=always
RestartSec=500ms
StandardOutput=syslog
StandardError=syslog
SyslogIdentifier=git-daemon
User=git
Group=git
[Install]
WantedBy=multi-user.targetМоже да видите, че Git демонът се пуска с потребител и група git.
Ако се налага, променете ги според вашите нужди и се уверете, че потребителят който сте написали съществува в системата.
Също така, проверете дали изпълнимият файл се намира в /usr/bin/git и го коригирайте, ако не е.
Накрая трябва да изпълните systemctl enable git-daemon за да пуснете услугата автоматично при рестарт на компютъра. Ръчното пускане и спиране на услугата се прави с командите systemctl start git-daemon и systemctl stop git-daemon, съответно.
На други системи, може да искате да ползвате xinetd, скрипт в sysvinit системата или пък нещо друго като похват — трябва просто да пуснете командата като демон и да наблюдавате статуса ѝ.
Остава да кажете на Git в кои хранилища трябва да се разреши свободния достъп през Git протокола.
Можете да направите това във всяко хранилище създавайки файл с име git-daemon-export-ok.
$ cd /path/to/project.git
$ touch git-daemon-export-okНаличието му казва на Git, че е ОК да обслужва съответния проект без автентикация.
=== Smart HTTP
Вече имаме автентикиран достъп през SSH и неавтентикиран през git:// протокола, но съществува и протокол, който може да прави и двете едновременно.
Процесът по настройка на Smart HTTP всъщност се свежда до разрешаването на CGI скрипт, който идва с Git и е известен като git-http-backend на сървъра.
Този скрипт ще чете пътя и хедърите изпратени от git fetch или git push към HTTP URL и ще разбере дали клиентът може да комуникира през http (което е така за всеки клиент след версия 1.6.6).
Ако CGI скриптът види, че клиентът е смарт, той ще комуникира с него по интелигентен начин. В противен случай, ще се върне към по-опростения способ (така че да е обратно съвместим с по-старите клиенти).
Нека минем през съвсем простата настройка. Ще използваме Apache като CGI сървър. Ако нямате настроен Apache, можете да го направите в Linux система приблизително така:
$ sudo apt-get install apache2 apache2-utils
$ a2enmod cgi alias envТова ще разреши модулите mod_cgi, mod_alias, и mod_env, които са необходими за нашите цели.
Ще трябва също така да промените групата на директориите в /srv/git на www-data, така че уеб сървърът да има права за четене и писане в хранилищата, защото инстанцията на Apache, която ще изпълнява CGI скрипта, ще работи по подразбиране като този потребител:
$ chgrp -R www-data /srv/gitСлед това трябва да променим някои неща по конфигурацията на Apache, така че да използва git-http-backend скрипта като средство за обработка на всички заявки, идващи в /git пътя на уеб сървъра.
SetEnv GIT_PROJECT_ROOT /srv/git
SetEnv GIT_HTTP_EXPORT_ALL
ScriptAlias /git/ /usr/lib/git-core/git-http-backend/Ако оставите променливата GIT_HTTP_EXPORT_ALL, тогава Git ще допуска неавтентикираните потребители само до хранилищата, съдържащи файла git-daemon-export-ok - точно както го прави и Git демона.
Накрая, ще искаме да накараме Apache да позволява заявки от автентикирани потребители с права на запис към git-http-backend с блок подобен на следния:
<Files "git-http-backend">
AuthType Basic
AuthName "Git Access"
AuthUserFile /srv/git/.htpasswd
Require expr !(%{QUERY_STRING} -strmatch '*service=git-receive-pack*' || %{REQUEST_URI} =~ m#/git-receive-pack$#)
Require valid-user
</Files>Това значи, че трябва да създадете .htpasswd файл, съдържащ паролите за всички валидни потребители.
Ето пример за добавен потребител “schacon” в такъв файл:
$ htpasswd -c /srv/git/.htpasswd schaconИма много различни начини да накарате Apache да автентикира потребители, просто трябва да изберете подходящия за вас. Тук просто посочихме един от най-простите варианти. Вероятно също ще искате да настроите достъп през SSL, така че комуникацията да е криптирана.
Няма да навлизаме по-навътре в конфигурационните детайли на Apache, тъй като може да използвате различни похвати за автентикация или изцяло различен уеб сървър.
Идеята е, че Git идва с CGI скрипт наречен git-http-backend, който когато бъде извикан, ще поеме цялата комуникация по приемането и изпращането на данни през HTTP.
Самият скрипт не извършва сам по себе си никаква автентикация, но това може лесно да бъде контролирано при уеб сървъра, който го извиква.
Можете да го използвате почти с всеки CGI уеб сървър, така че изберете този, който предпочитате.
За повече информация за настройка на Apache, вижте документацията тук: https://httpd.apache.org/docs/current/howto/auth.html
=== GitWeb
Сега, когато имате базисен read/write и read-only достъп до вашия проект, може да искате да добавите прост уеб базиран визуализатор. Git предоставя CGI скрипт наречен GitWeb, който понякога се ползва за целта.
Ако искате да проверите как ще изглежда GitWeb за вашия проект, Git предлага команда с която да пуснете временна инстанция при условие че системата ви има инсталиран олекотен уеб сървър като lighttpd или webrick.
На Linux машини, lighttpd често идва предварително инсталиран, така че може да го стартирате с командата git instaweb в директорията на проекта.
Ако сте на Mac, Leopard идва с инсталиран Ruby, така че webrick може да е удобна опция.
За да пуснете instaweb с non-lighttpd сървър, можете да я изпълните с аргумента --httpd.
$ git instaweb --httpd=webrick
[2009-02-21 10:02:21] INFO WEBrick 1.3.1
[2009-02-21 10:02:21] INFO ruby 1.8.6 (2008-03-03) [universal-darwin9.0]Това ще ви пусне HTTPD сървър на порт 1234 и след това автоматично ще се стартира уеб браузър, който отваря тази страница.
Лесно е от ваша страна.
Когато сте готови и искате да спрете сървъра, изпълнете командата с аргумента --stop:
$ git instaweb --httpd=webrick --stopАко пък искате уеб интерфейсът да е постоянно достъпен, например за екипа ви или за проект с отворен код, ще трябва да направите така, че CGI скриптът да се обслужва от нормален уеб сървър.
Някои Linux дистрибуции имат пакета gitweb, който може да се инсталира през apt или dnf, така че може да ползвате и този начин.
Ще преминем набързо през инсталацията на GitWeb.
Първо, ще ви трябва сорс кода на Git, с който идва GitWeb и след това генерирате custom CGI скрипт:
$ git clone git://git.kernel.org/pub/scm/git/git.git
$ cd git/
$ make GITWEB_PROJECTROOT="/srv/git" prefix=/usr gitweb
SUBDIR gitweb
SUBDIR ../
make[2]: `GIT-VERSION-FILE' is up to date.
GEN gitweb.cgi
GEN static/gitweb.js
$ sudo cp -Rf gitweb /var/www/Отбележете, че трябва да кажете на командата къде да намира Git хранилищата ви посредством променливата GITWEB_PROJECTROOT.
След това, трябва да накарате Apache да използва CGI за този скрипт, за което може да добавите виртуален хост:
<VirtualHost *:80>
ServerName gitserver
DocumentRoot /var/www/gitweb
<Directory /var/www/gitweb>
Options +ExecCGI +FollowSymLinks +SymLinksIfOwnerMatch
AllowOverride All
order allow,deny
Allow from all
AddHandler cgi-script cgi
DirectoryIndex gitweb.cgi
</Directory>
</VirtualHost>Да кажем пак, GitWeb може да се обслужва с произволен CGI или Perl съвместим уеб сървър; ако предпочитате различен от Apache, няма проблем да го ползвате.
В този момент трябва да можете да отворите адреса http://gitserver/ за да видите хранилищата си онлайн.
=== GitLab
GitWeb е доста семпъл вариант за визуализация. Ако търсите по-модерен, напълно функционален Git сървър, съществуват няколко проекта с отворен код, които са на ваше разположение. Понеже GitLab е един от най-популярните, ще разгледаме него за пример. Това е малко по-сложно от GitWeb и вероятно ще изисква повече поддръжка, но е и много по-пълноценна алтернатива.
==== Инсталация
GitLab е уеб приложение използващо база данни, така че инсталацията му изисква малко повече усилия сравнена с някои други Git сървъри. За щастие, този процес е много добре документиран и проектът активно се поддържа. GitLab горещо препоръчва инсталирането на сървъра ви да се прави през официалния Omnibus GitLab пакет.
Другите опции за инсталиране са:
-
GitLab Helm chart, за ползване с Kubernetes.
-
Dockerized GitLab пакети за използване с Docker.
-
От сорс-файлове.
-
От облачен доставчик като AWS, Google Cloud Platform, Azure, OpenShift и Digital Ocean.
За повече информация прочетете GitLab Community Edition (CE) ръководството.
==== Администрация
Административният интерфейс на GitLab е достъпен през браузър.
Отворете страницата на IP адреса на машината, на която е инсталиран GitLab и се логнете като администратор.
Фабричното потребителско име е admin@local.host, а паролата 5iveL!fe (ще бъдете помолени да я промените веднага след входа).
След това натиснете иконата “Admin area” в менюто в горния десен край.
===== Потребители
Потребителите в GitLab са акаунти, които съответстват на хора.
Самите акаунти не са сложни; в основни линии представляват колекция от персонални данни прикачени към логин информацията.
Всеки потребителски акаунт притежава namespace, за логическо групиране на проектите, които притежава.
Така, ако потребител с име jane има проект с име project, то този проект ще е с url http://server/jane/project.
Изтриването на потребител може да стане по два начина: “Блокирането” на потребител забранява логването му в GitLab инстанцията, но всички данни в съответния namespace ще бъдат запазени и всички къмити подписани с имейл адреса на този потребител ще сочат все още към съответния потребителски профил.
“Изтриването” от своя страна, тотално унищожава потребителя от базата данни и файловата система. Всички проекти и данните в съответния namespace се изтриват и всички групи, които потребителят притежава, също се изтриват. Очевидно тази втора опция е много по-деструктивна и се използва рядко.
===== Групи
GitLab групата представлява съвкупност от проекти плюс информация за това как потребителите имат достъп до тях.
Всяка група има namespace за проектите (по същия начин като потребителите), така че ако групата training съдържа проект materials, то неговият url ще бъде http://server/training/materials.
Всяка група е асоциирана с множество потребители, всеки от които разполага с ниво на достъп до групата и проектите в нея. То варира от “Guest” (с достъп до issues и chat) до “Owner” (пълен контрол над групата, членовете ѝ и нейните проекти). Типовете права са твърде много, за да ги изброяваме всичките, но GitLab има полезни линкове за помощ в административния интерфейс.
===== Проекти
Един GitLab проект приблизително съответства на единично Git хранилище. Всеки проект принадлежи на един namespace, потребителски или на група. Ако проектът принадлежи на потребител, то този потребител има пряк контрол върху това кой ще има достъп до него; ако е в група, то тогава user-level правата на групата ще се приложат съответно.
Всеки проект има също така ниво на видимост, което контролира кой има права за четене на страниците и хранилището му.
Ако един проект е Private, то собственикът му трябва изрично да даде права за достъп на него до потребителите, които пожелае да го виждат.
Internal проектите са видими за всеки логнат потребител, а Public проектите са видими за всички.
Това контролира както git fetch достъпа, така и достъпа до уеб UI интерфейса за този проект.
===== Hooks
GitLab подържа hooks като способ за сигнализация, на ниво проект и система. За всеки от тях, GitLab сървърът ще направи HTTP POST заявка с описателна JSON-фирматирана информация, когато възникнат съответните събития. Това е полезен начин да свържете вашите Git хранилища и GitLab инстанцията си към останалата част от автоматизацията на разработките като например CI сървъри, чат стаи или deployment инструменти.
==== Използване
Вероятно най-напред ще искате да създадете GitLab проект. Това се прави чрез иконата “+” на лентата с инструменти. Ще трябва да въведете име за проекта, към кой namespace ще принадлежи той и какво ниво на видимост ще има. Повечето от тези неща не са перманентни и могат да се редактират по-късно. Натиснете “Create Project” и сте готови.
След като проектът съществува, вероятно ще искате да го свържете с локално Git хранилище.
Всеки проект е достъпен през HTTPS или SSH и всеки от тези протоколи може да се използва като Git remote.
Адресите са видими в горната част на страницата на проекта.
В налично локално Git хранилище, тази команда ще създаде отдалечена референция с име gitlab към хостваната локация:
$ git remote add gitlab https://server/namespace/project.gitАко нямате локално копие на хранилището, може просто да изпълните:
$ git clone https://server/namespace/project.gitУеб интерфейсът осигурява достъп до множество удобни изгледи на самото хранилище. Домашната страница на всеки проект показва последната активност и линковете в горната част ще ви преведат до изгледи на файловете в проекта и историята на къмитите.
==== Съвместна работа
Най-простият начин за съвместна работа в GitLab е да дадете на друг потребител директно push права за достъп до Git хранилището ви. Можете да добавите потребител към проекта от секцията “Members” в настройките на проекта, където може да асоциирате и ниво на достъп за него (различните нива на достъп се разглеждат по-подробно в [_gitlab_groups_section]). Давайки на потребителя ниво “Developer” или по-високо, вие му позволявате свободно да изпраща къмити и клонове директно в хранилището.
Друг метод за колаборация е чрез използването на merge requests.
Тази функция позволява на всеки потребител, който вижда даден проект, да сътрудничи в него по контролиран начин.
Потребителите с директен достъп могат просто да създадат клон, да изпратят в него къмити и да отворят merge request от техния клон обратно в master или който и да е друг клон.
Потребителите без push права за дадено хранилище могат да го клонират при себе си (“fork”), да правят къмити в това тяхно копие и да отворят merge request от него обратно към основния проект.
Този модел на работа позволява на собственика на проекта да има пълен контрол върху това какво и кога влиза в хранилището и едновременно с това да позволява сътрудничество от непознати потребители.
Merge requests и issues са основните обекти на дискусиите в GitLab. Всеки merge request позволява line-by-line дискусия на предложената промяна (което поддържа олекотен вид code review), както и обща дискусионна нишка. И двата обекта могат да се асоциират към потребители или да се организират в milestones.
Тази секция е фокусирана основно върху Git функциите на GitLab, но като един наистина зрял проект, той предлага много други възможности за съвместна работа на екипа ви като например множество wiki за проектите и инструменти за системна поддръжка. Едно от предимствата на GitLab е в това, че веднъж настроен и пуснат, рядко ще ви се налага да променяте конфигурационен файл или да влизате в сървъра през SSH; повечето административни задачи се осъществяват през уеб интерфейса.
=== Други опции за хостване
Ако не желаете да се занимавате с работата по инсталация и поддръжка на собствен Git сървър, налице са доста опции за хостване на Git проектите ви на външен такъв. Това си има предимства: обикновено хостваната услуга е лесна за създаване и поддържане на проекти и освен това не се нуждае да правите поддръжка и мониторинг. Дори и да сте си инсталирали собствен сървър, може все още да искате да се възползвате от публичните хостинг услуги за съхранение на проектите ви с отворен код – така по-лесно ще бъдете в контакт с общността от open source разработчици.
В днешни дни броят на хостинг опциите е достатъчно голям, така че да изберете вашата претегляйки предимствата и недостатъците им. Актуален списък на вариантите се поддържа в страницата GitHosting в основното wiki на Git на адрес https://git.wiki.kernel.org/index.php/GitHosting.
Ще разгледаме в детайли GitHub в главата GitHub, понеже е най-голямата хостинг система в момента и вероятно ще искате да я ползвате така или иначе. Но съществуват и дузини други варианти, ако не желаете да инсталирате и поддържате собствен Git сървър.
=== Обобщение
Разполагате с няколко опции за създаване и ползване на отдалечени Git хранилища, чрез които да сътрудничите заедно с екипа разработчици.
Пускането на собствен сървър ви дава висока степен на контрол и ви позволява да го разположите зад собствена защитна стена, но пък изисква известно време за настройка и регулярна поддръжка. Ако разположите кода си на хостван сървър, тогава първоначалната настройка и поддръжката не изискват никакви усилия, но от друга страна - не всички организации са съгласни на такъв един подход.
Би следвало да е лесно да изберете кое решение (или комбинация от решения) е подходящо за вашата организация.
== Git в разпределена среда
Сега, когато вече имате настроено отдалечено Git хранилище като обща точка за всички разработчици по даден проект и сте достатъчно сигурни в познанията за основните Git команди в процеса на локална работа, ще се спрем на това как да ползваме някои разпределени похвати за работа.
В тази глава ще видите как се работи с Git в разпределена работна среда като сътрудник и интегратор. Това включва инструкции за това как да допринасяте успешно със свой код в общ проект по възможно най-лесния начин за вас и за автора на проекта, а също така и как самите вие да поддържате успешно проект, по който работят множество разработчици.
=== Разпределени работни процеси
За разлика от централизираните Version Control Systems (CVCSs), разпределената натура на Git позволява по-голяма гъвкавост по отношение на това как разработчиците сътрудничат в проектите. В централизираните системи всеки разработчик е нещо като възел работещ повече или по-малко с един централен хъб. В Git обаче, всеки разработчик може потенциално да бъде и хъб и възел – това значи, че може както да сътрудничи в други хранилища, така и да поддържа свое собствено публично такова, на което негови колеги да базират работата си и да сътрудничат. Това отваря доста възможности за структуриране на работните процеси за проекта и/или екипа, така че ще разгледаме някои познати парадигми, които съществуват благодарение на тази гъвкавост. Ще погледнем силните и слаби страни на всеки дизайн, а вие може да изберете един от тях или да смесвате възможности от различни такива.
==== Централизиран работен процес
В централизираните системи съществува единичен модел за съвместна работа – централизираният работен процес. Един централен хъб, хранилище, може да приема код и всеки трябва да синхронизира работата си с него. Множеството разработчици са възлите, консуматорите в този хъб и те трябва да се синхронизират с неговия статус.
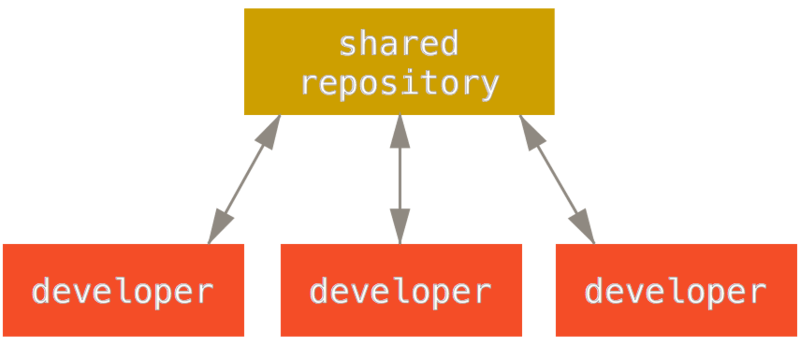
Това ще рече, че ако двама души клонират от централното хранилище и направят промени, то само първият от тях, който изпрати обратно промените си, ще може да направи това без проблем. Закъснелият разработчик ще трябва първо да слее при себе си работата на първия си колега, преди да публикува своите промени - така първите направени промени не се презаписват. Тази концепция работи както при Git, така и при Subversion (или всяка друга CVCS).
Ако вече се чувствате в свои води с този стил на работа във вашата компания или екип, можете лесно да продължите да го следвате и с Git. Просто направете единично хранилище и дайте на всеки от екипа си push достъп; Git няма да позволи на колегите да се презаписват един друг.
Да кажем, че John и Jessica започват да работят едновременно. John завършва промените си и ги изпраща към сървъра. След това Jessica опитва да публикува своите, но сървърът отказва това. Тя ще бъде уведомена, че се опитва да публикува non-fast-forward промени и че няма да може да го направи докато първо не изтегли и слее работата на John. Този работен процес е популярен, защото следва познати на много хора парадигми на работа.
Освен това не е ограничен до малки екипи. С модела за разклоняване на Git е възможно стотици разработчици успешно да работят едновременно по единичен проект през множество различни клонове код.
==== Integration-Manager работен процес
Понеже Git позволява да имате множество отдалечени хранилища, възможно е да имате работен процес, при който всеки разработчик има достъп за писане до собственото си публично хранилище и достъп само за четене до всички останали. Този сценарий често включва canonical хранилище, което представлява “официалния” проект. За да сътрудничите в него, вие създавате собствено публично негово копие и публикувате промените си в него. След това, можете да изпратите заявка до собственика на canonical проекта за интегриране на вашите промени. Тогава този автор може да добави вашето хранилище като свое отдалечено такова, да тества локално промените ви, да ги слее в собствен клон и накрая да ги публикува в публичното хранилище така че да са достъпни за всички. Процесът работи така (вижте Integration-manager работен процес):
-
Поддържащият проекта изпраща промени в публично хранилище.
-
Сътрудник клонира хранилището и прави собствени промени по него.
-
Сътрудникът публикува промените си в собственото си публично копие.
-
Сътрудникът изпраща на поддържащия проекта съобщение със заявка за интегриране на промените.
-
Поддържащият проекта добавя хранилището на сътрудника като отдалечено, издърпва и слива промените локално при себе си.
-
Поддържащият проекта публикува слетите промени обратно в главното хранилище.
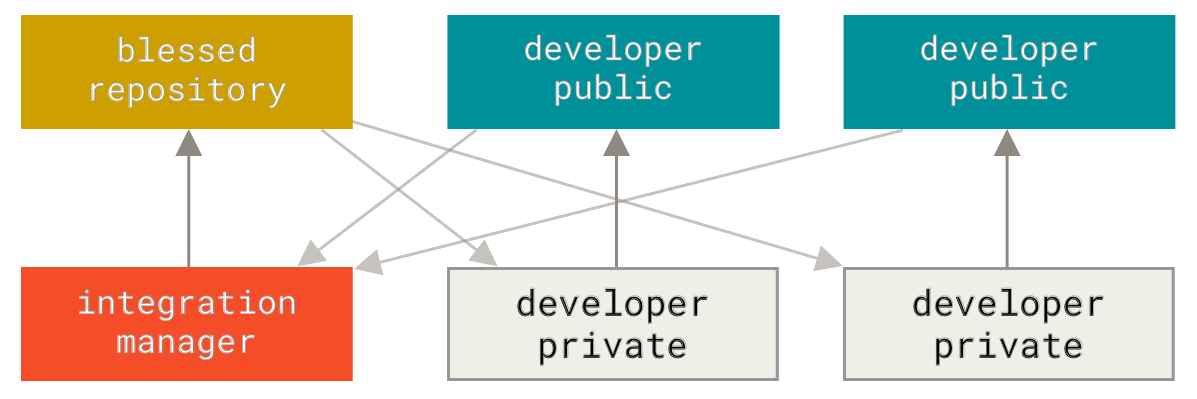
Това е доста разпространен начин на работа в хъб-базираните платформи като GitHub или Gitlab, където е лесно да клонирате проект и да публикувате промените си в него така, че всички да ги виждат. Едно от най-съществените предимства на този подход е, че позволява да продължите работата си, а поддържащият централното хранилище може да интегрира промените ви по всяко време. Сътрудниците не е нужно да чакат промените им да бъдат интегрирани – всяка страна може да работи със собствени темпове.
==== Dictator and Lieutenants работен процес
Това е вариант на работа с множество хранилища. Обикновено се използва в проекти от много голям мащаб, със стотици сътрудници; един пример за такъв е ядрото на Linux. Различни интегриращи мениджъри се грижат за определени части от хранилището; те се наричат лейтенанти. Всеки от лейтенантите има един интегриращ мениджър, известен като благосклонен диктатор (benevolent dictator). Този диктатор публикува код от собствена директория към референтно хранилище, от което всички сътрудници трябва да теглят. Процесът работи така (вижте Benevolent dictator работен процес):
-
Обикновените разработчици работят по своя topic клон и пребазират работата си върху
master.masterклонът е този от референтното хранилище, към което диктаторът публикува. -
Лейтенантите сливат topic клоновете на разработчиците в своя
masterклон. -
Диктаторът слива
masterклоновете на лейтенантите в свояmasterклон. -
Накрая, диктаторът изпраща този
masterклон към референтното хранилище, така че разработчиците могат да се пребазират по него.
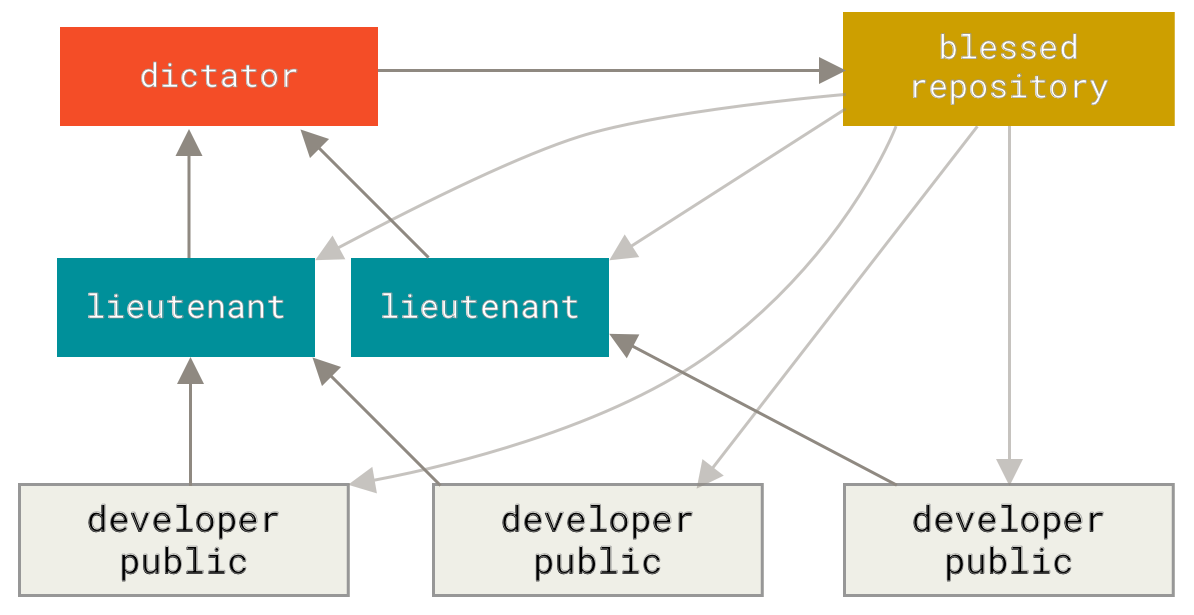
Този процес на работа се ползва рядко, но може да е полезен в много големи проекти или в йерархични работни среди. Той позволява на лидера на проекта (диктатора) да делегира повече работа и да събира големи подмножества от код от много локации преди да ги интегрира.
==== Patterns for Managing Source Code Branches
Martin Fowler е автор на ръководството "Patterns for Managing Source Code Branches". То обхваща всички популярни работни процеси в Git и обяснява как и кога да се използват. Налична е и глава сравняваща high и low integration frequencies.
==== Обобщение
Това са част от популярните работни процеси, които могат да се реализират с разпределена система като Git, но може да видите, че са възможни голям брой варианти, които да съответстват на вашата специфична работна среда. Сега, след като (надяваме се) можете да изберете варианта, който е най-подходящ за вас, ще разгледаме някои по-специфични примери за това как да изпълняваме основните роли, които съставляват тези работни процеси. В следващата секция ще посочим няколко основни правила за това как да сътрудничим в проект.
=== Как да сътрудничим в проект
Основната трудност с обяснението на това как се допринася към проект са големия брой варианти как да го направите. Понеже Git е много гъвкав, хората могат (и го правят) да си вършат работата по различни начини – затова е проблематично да се даде съвет как да постъпите – всеки проект си има специфики. Сред факторите, които влияят са броя разработчици, избрания вид работен процес, вашите права за достъп до хранилището и вероятно външния метод за съвместна работа.
Първата неизвестна е броят разработчици – колко са много активните колеги и колко често сътрудничат? В много случаи ще имате двама или трима програмисти с малко къмити на ден, или дори и по-малко при не толкова интензивни проекти. В големи компании или проекти обаче, могат да съществуват хиляди сътрудници със стотици или хиляди къмити на ден. Това е важно, защото с увеличаването на броя програмисти, ще срещате повече проблеми с това да се уверите, че кодът се прилага чисто или може лесно да се слива. Промените, които предлагате могат да се окажат остарели или несъвместими с друга работа, която е била слята докато сте работили или докато сте чакали вашия код да бъде одобрен. Възниква въпросът как да поддържате кода си актуален и къмитите си валидни?
Следващият фактор е избраният вид работен процес. Дали той е централизиран, при който всеки разработчик има еднакъв достъп за писане до основното хранилище? Дали проектът има поддържащ потребител или интегриращ мениджър, които да проверяват всички пачове? Дали всички пачове се разглеждат и одобряват колективно? Дали вие участвате в този процес? Съществува ли lieutenant-система и трябва ли първо да изпращате работата си на вашия лейтенант?
Следват правата ви на достъп. Последователността на работа, когато трябва да участвате в проект е доста различна в зависимост от това дали имате права за писане или не. Ако нямате права за писане, как този проект предпочита да приема външна помощ? Дали въобще съществува политика за това? Какво количество работа изпращате всеки път? Колко често правите това?
Всички тези въпроси могат да се отразят на начина, по който вие допринасяте към даден проект и какви работни процеси са предпочитани или достъпни за вас. Ще разгледаме различните аспекти в серия от примери, започвайки от прости към по-сложни и в края би следвало да си изградите представа какъв похват ще ви е необходим в различните случаи от реалната практика.
==== Упътвания за къмитване
Преди да се фокусираме върху конкретни примери, едно малко отклонение касаещо къмит съобщенията. Да имате добра насока за създаване на къмити и да се придържате към нея ще направи работата ви с Git и сътрудничеството с колегите много по-лесни. Самият проект Git предоставя документ формулиращ множество добри съвети за създаване на къмити, от които да изпращате пачове — можете да го прочетете в сорс кода на Git, във файла Documentation/SubmittingPatches`.
Първо, вашите промени не трябва да съдържат никакви whitespace грешки.
Git осигурява лесен начин да проверите това — преди да къмитнете, изпълнете командата git diff --check, която намира възможните whitespace грешки и ви ги показва.
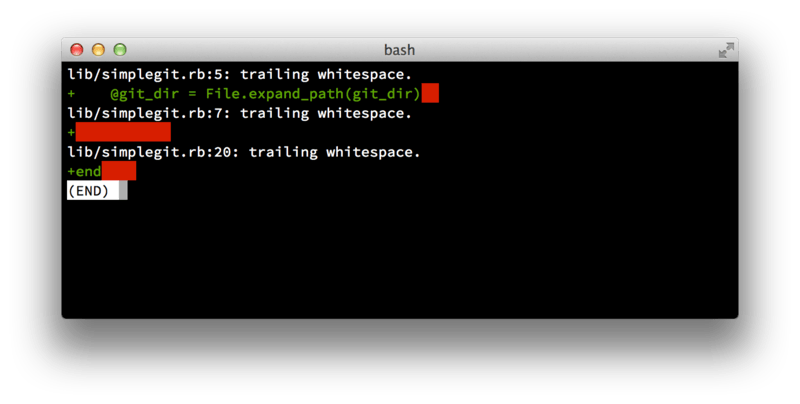
git diff --check
Ако я изпълните преди да къмитнете, можете да разберете дали не вкарвате в проекта излишни интервали, които да отегчат останалите ви колеги.
След това, опитайте се да направите от всеки един къмит логически отделена, самостоятелна и специфична за даден проблем промяна.
Ако можете, опитайте да правите промените си по-компактни — не програмирайте цял уикенд по пет различни задачи и после да ги изпращате като един масивен къмит в понеделник.
Дори ако през уикенда не сте къмитвали, използвайте индексната област в понеделник за да разделите работата си на няколко къмита, всеки от които обслужва конкретен решен проблем и съдържа съответното подходящо съобщение.
Ако някои от промените засягат един и същи файл, опитайте да използвате git add --patch за да индексирате файловете частично (показано в подробности в Интерактивно индексиране).
В края на краищата, snapshot-тът на края на клона ви ще е идентичен независимо дали сте направили един или пет къмита, така че пробвайте да улесните живота на вашите колеги, когато започнат да разглеждат работата ви.
Този подход също така ви позволява по-късно да премахнете или коригирате само част от промените си, ако се наложи. Манипулация на историята описва няколко полезни Git трика за презапис на историята и интерактивно индексиране на файлове — използвайте тези инструменти като помощ за поддържане на чиста и разбираема история преди да изпратите работата си към някой друг.
Последното нещо, което също не трябва да се пренебрегва, е къмит съобщението. Изработете си навик да създавате качествени къмит съобщения и ще работите с Git и колегите си много по-приятно. Като основно правило, съобщенията ви трябва да започват с един ред не по-дълъг от 50 символа, описващ стегнато промените, следван от празен ред, след което може да се разположат по-дългите обяснения. Git проектът например изисква подробното описание да включва мотивите ви за дадената промяна и да обяснява разликите с оригиналния вариант на кода — и това е добро правило, което може да следвате. Пишете съобщенията си в императивна форма: "Fix bug" а не "Fixed bug" или "Fixes bug" Тук има един шаблон, написан отначало от Tim Pope, който леко преработихме:
Кратко (50 или по-малко символа), изписано с големи букви описание на промените
По-детайлно описание, ако е нужно. Пренасяйте го на около 72 символа.
В някои случаи, първият ред се третира като subject на
email и останалото от текста като тяло. Празният ред разделящ двете
е много важен (освен ако не пропускате тялото
изцяло); инструменти като rebase може да се объркат
ако пуснете двете заедно.
Напишете съобщението си в императивна форма: "Fix bug" а не
"Fixed bug" или "Fixes bug". Тази конвенция съответства на къмит
съобщенията генерирани от команди като git merge и git revert.
Следващите абзаци се разделят с празни редове.
- точките (Bullet) също са ОК
- Обикновено за bullet се използва звездичка или тире следвани
от един интервал, с празни редове помежду им, но правилата тук варират
- Използвайте hanging indentАко всички ваши къмит съобщения следват този модел, нещата между вас и колегите ви разработчици ще вървят по-гладко.
Git проектът има добре форматирани къмит съобщения — пробвайте да пуснете git log --no-merges в хранилището и ще видите колко добре форматирана е историята на проекта.
Много от примерите в тази книга съвсем не съдържат добре форматирани къмит съобщения; ние използваме -m параметъра към git commit за по-кратко.
Накратко, следвайте правилото за добра практика, а не гледайте какво сме направили ние.
==== Малък частен екип
Най-простата схема, на която може да попаднете е частен проект с един или двама разработчици. “Частен,” в този смисъл, означава със затворен код — недостъпен за външния свят. Вие всички имате достъп за писане до хранилището.
В такава среда, можете да следвате работен процес подобен на този, който бихте ползвали в Subversion или друга централизирана система.
Може все още да използвате предимствата на неща като офлайн къмитване и съвсем прости разклонявания и сливания, но работният процес може да е много подобен; основната разлика е, че сливанията се случват от страна на клиента, вместо на сървъра по време на къмита.
Нека видим как би могло да изглежда това, когато двама разработчика започнат съвместна работа със споделено хранилище.
Първият програмист, John, клонира хранилището, прави промяна и къмитва локално.
Протоколните съобщения са заменени с … в тези примери за да ги съкратим.
# John's Machine
$ git clone john@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'Remove invalid default value'
[master 738ee87] Remove invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)Вторият разработчик, Jessica, прави същото нещо — клонира хранилището и къмитва промяна:
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Cloning into 'simplegit'...
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'Add reset task'
[master fbff5bc] Add reset task
1 files changed, 1 insertions(+), 0 deletions(-)Сега, Jessica публикува работата си на сървъра и това работи безпроблемно:
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterПоследният ред от изхода отгоре показва полезно съобщение за резултата от push операцията.
Основният формат е <oldref>..<newref> fromref → toref, където oldref означава референция към предишния къмит, newref - към текущия, fromref е името на локалния клон, който се изпраща, и toref - на отдалечения, който се обновява.
Ще виждате подобен изход по-натам в дискусиите, така че да имате представа какво означава това ще е полезно в осмислянето на различните статуси на хранилищата.
Повече подробности има в документацията на командата git-push.
Продължаваме с този пример. Скоро след това, John прави някакви промени, къмитва ги в локалното си хранилище и се опитва да ги изпрати в същия сървър:
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'В този случай, опитът му завършва с неуспех, защото Jessica е изпратила нейните промени по-рано. Това е особено важно да се разбере, ако сте ползвали Subversion, защото вероятно забелязвате, че двамата разработчици не са редактирали един и същи файл. Въпреки че Subversion ще направи автоматично сливане на сървъра в случаи като този (променени различни файлове), при Git вие трябва първо да слеете къмитите локално. С други думи, John трябва първо да изтегли upstream промените на Jessica, да ги слее в локалното си хранилище и едва след това ще може да изпраща към сървъра.
Като първа стъпка, John изтегля работата на Jessica (командата отдолу само изтегля последната работа на Jessica, не я слива автоматично):
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/masterВ този момент, локалното хранилище на John изглежда подобно на това:
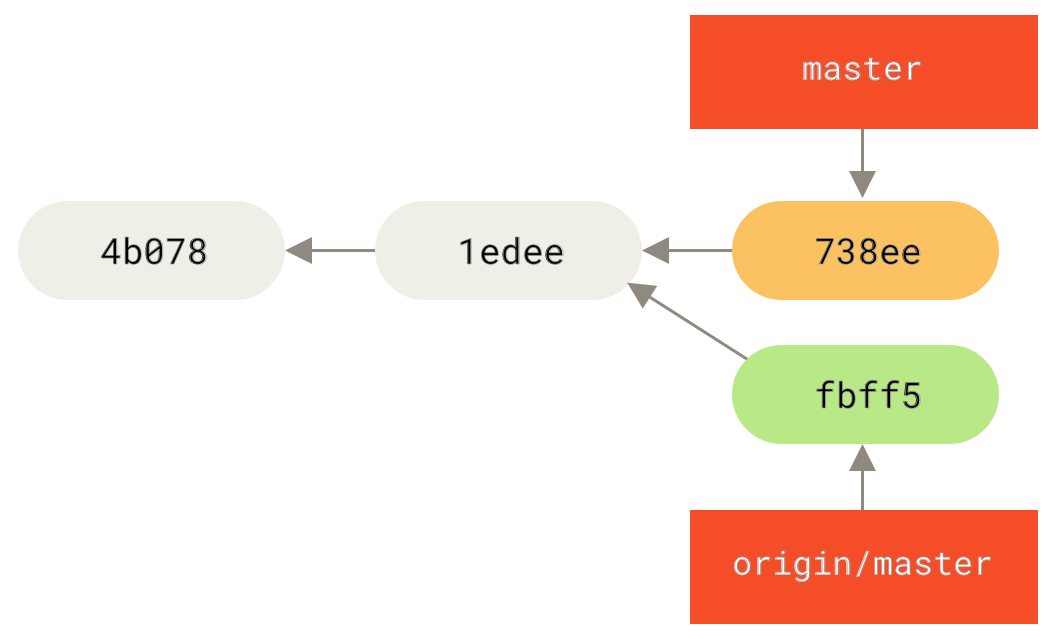
Следва командата за сливане в локалното хранилище:
$ git merge origin/master
Merge made by the 'recursive' strategy.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)След като това локално сливане мине гладко, обновената история на John ще изглежда така:
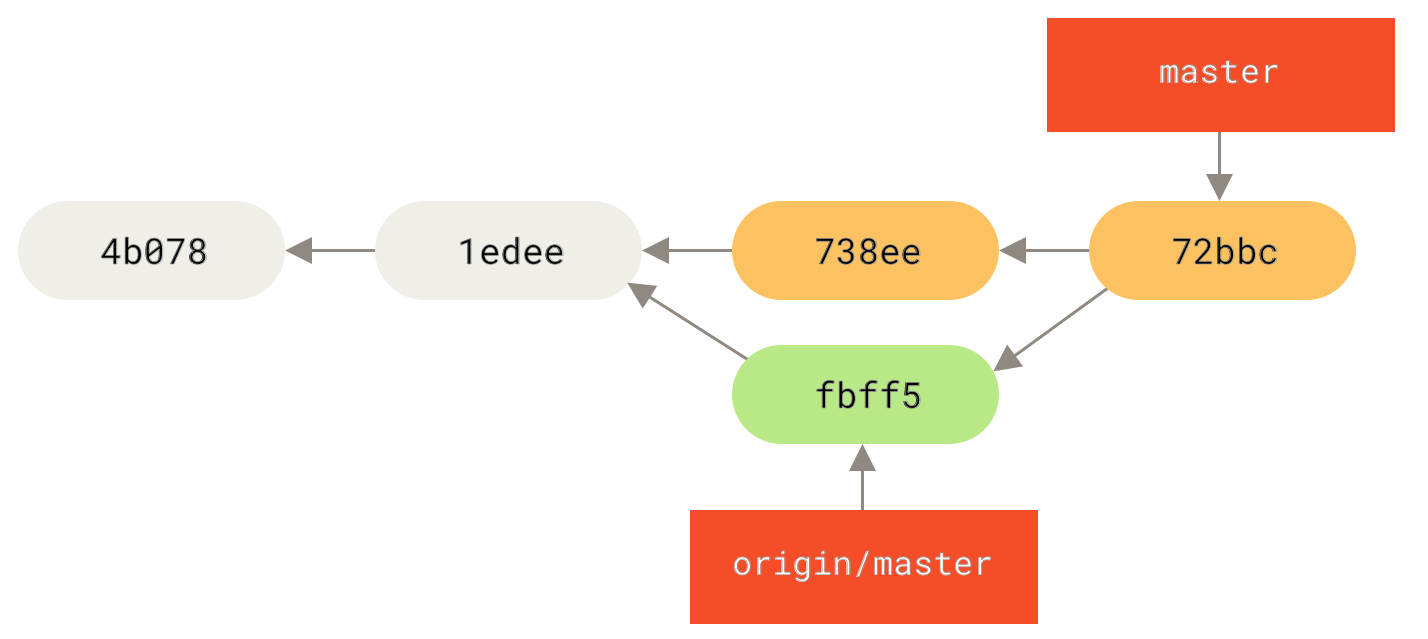
origin/master
В този момент, John може да поиска да провери дали новия код не засяга по някакъв начин неговата работа и след като всичко е нормално, може да изпрати всичко към сървъра:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> masterВ края, историята на къмитите на John ще изглежда така:
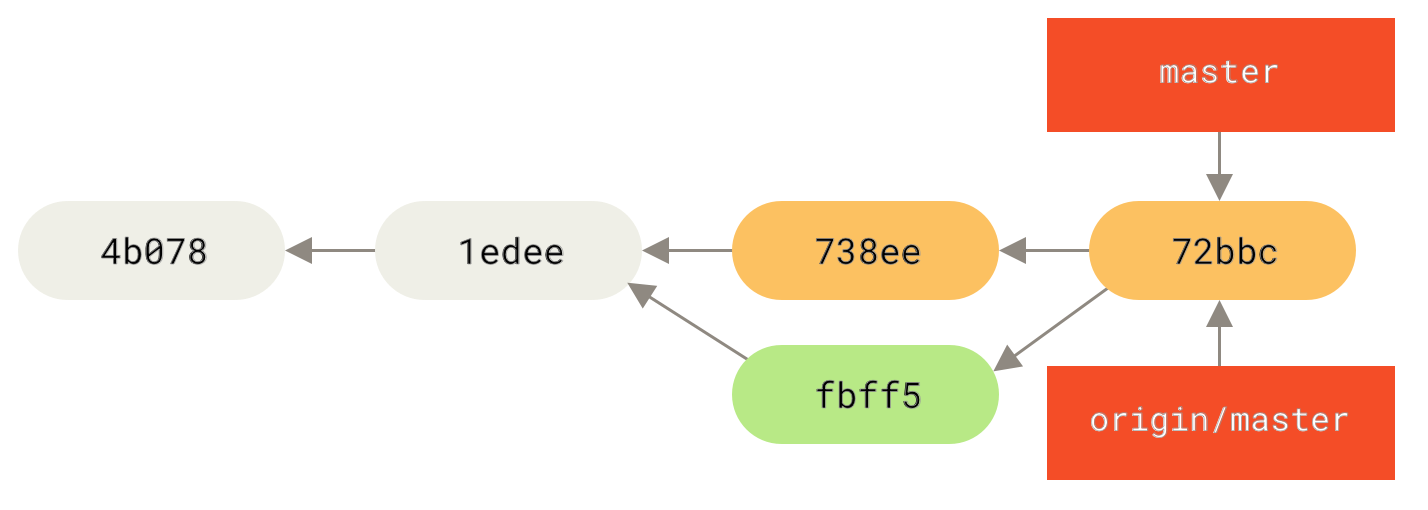
origin сървъраМеждувременно, Jessica създава нов topic клон наречен issue54 и прави три къмита в него.
Тя все още не е издърпала промените на John, така че историята ѝ изглежда така:
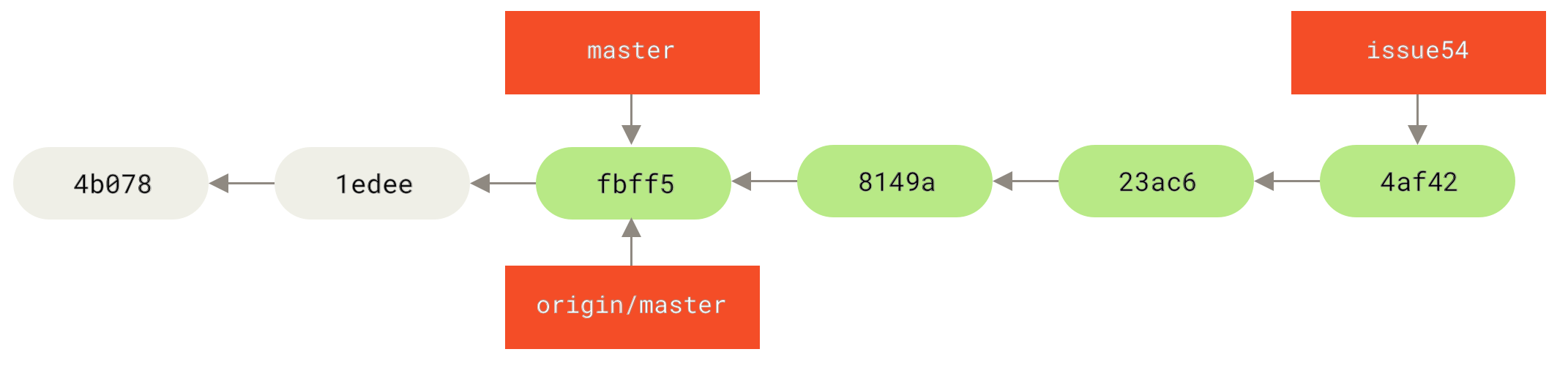
Внезапно Jessica научава, че John е публикувал някакви нови промени и иска да ги погледне, така че може да издърпа от сървъра:
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/masterТова ще изтегли промените на John и историята на Jessica изглежда така:
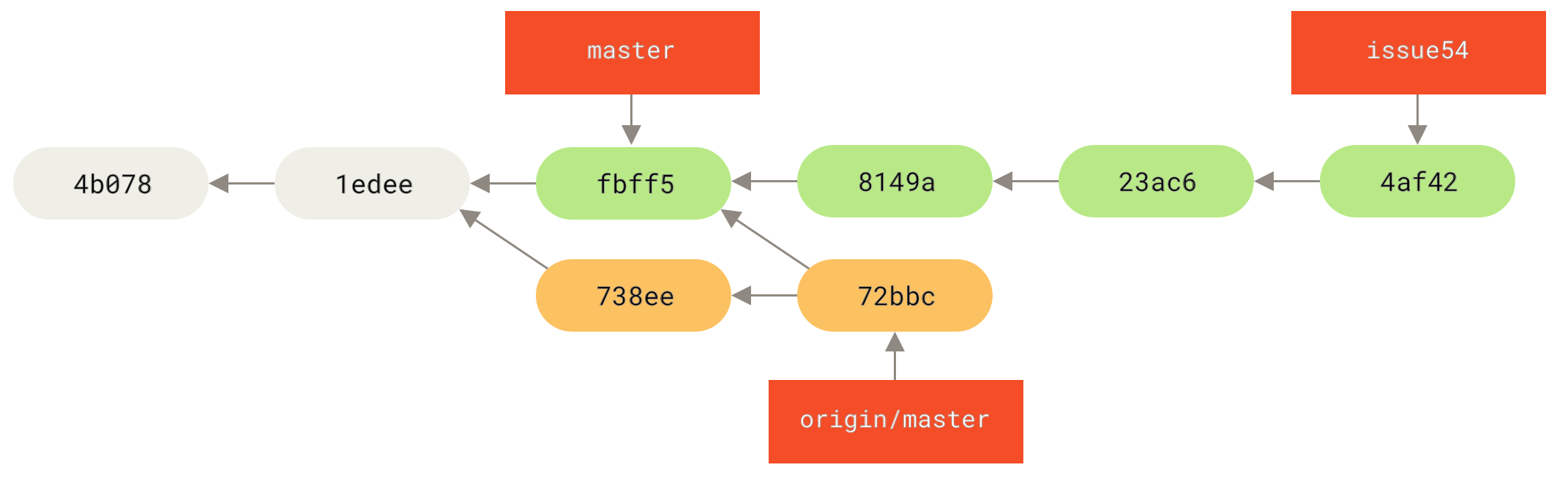
Jessica решава, че нейният topic клон вече е готов, но иска да знае коя част от работата на John трябва да слее със своята, така че да може да публикува.
За целта тя изпълнява командата git log:
$ git log --no-merges issue54..origin/master
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
Remove invalid default valueСинтаксисът issue54..origin/master е филтър, който указва на Git да покаже само тези къмити, които са налични във втория клон (в случая origin/master), но липсват в първия (issue54).
Ще разгледаме в подробности този синтаксис в Обхвати от къмити.
От горния изход можем да видим, че съществува един къмит направен от John, който Jessica не е сляла в локалното си копие.
Ако тя слее origin/master, това ще е единственият къмит, който би променил локалната ѝ работа.
Сега тя може да слее своя topic клон в master клона си, да слее работата на John (origin/master) пак в него и накрая да публикува всички промени към сървъра.
Първо (след като е къмитнала всичко в issue54 клона), Jessica превключва обратно към master клона си:
$ git checkout master
Switched to branch 'master'
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.Jessica може да слее първо origin/master или issue54 — и двата са upstream, така че редът е без значение.
Крайният snapshot трябва да е идентичен, само историята ще се различава.
Тя решава да слее първо issue54 клона:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)Не възникват проблеми, това е просто fast-forward сливане.
Jessica сега завършва процеса по локално сливане като вмъква и работата на John от клона orgin/master:
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)Всичко минава чисто и историята на Jessica сега изглежда така:
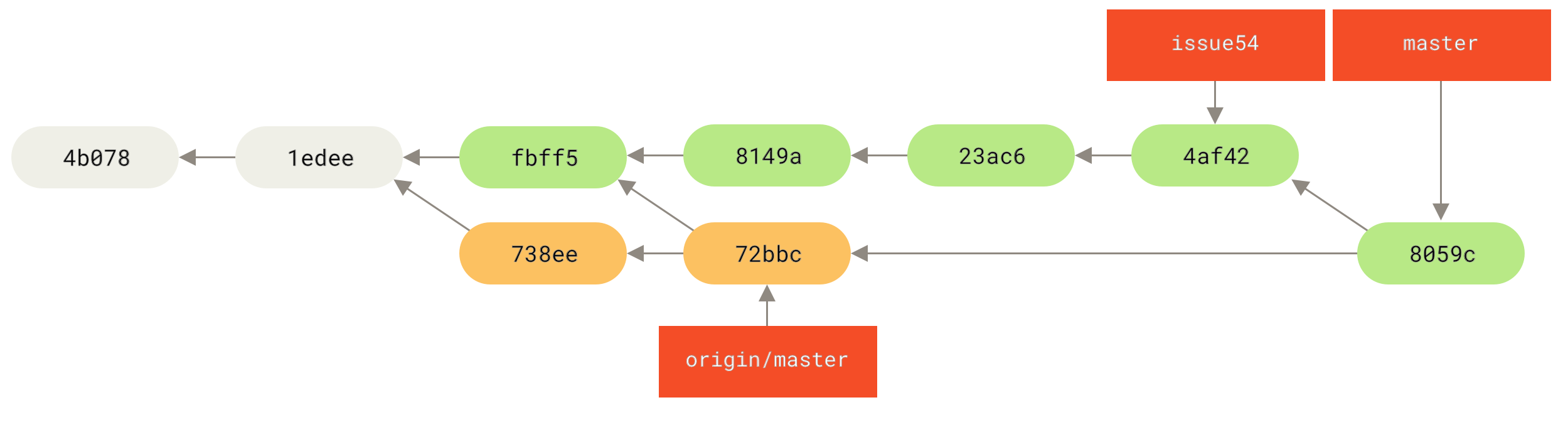
Сега origin/master е достъпен от master клона на Jessica, така че тя може успешно да публикува промените (приемаме, че междувременно John не е изпращал нови такива):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> masterСега всеки разработчик е къмитнал по няколко пъти и успешно е слял работата на колегата си.
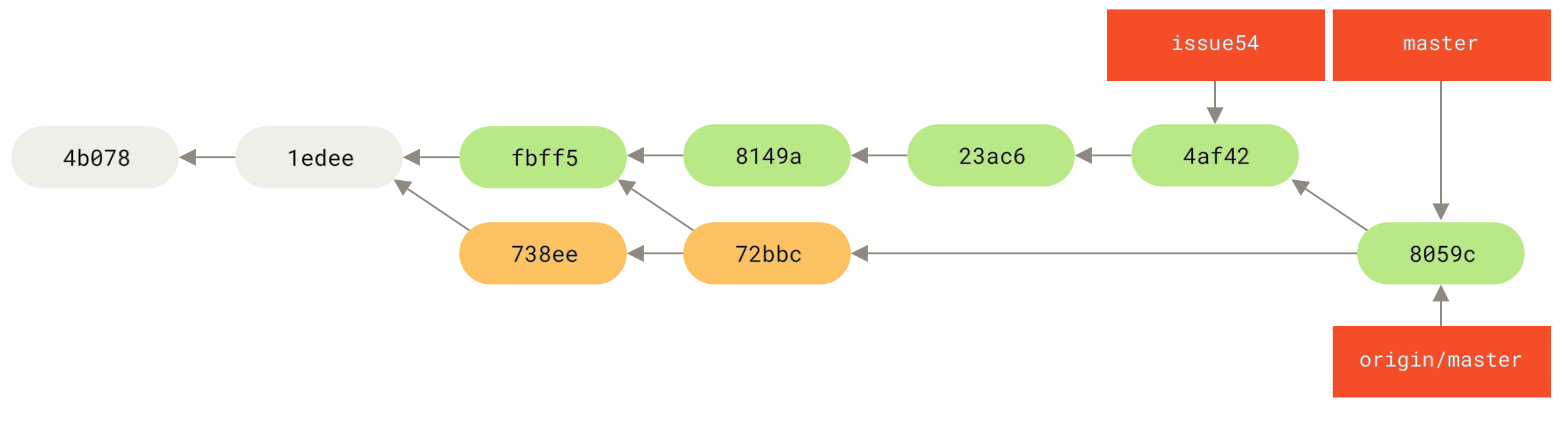
Това е един от най-простите процеси на работа.
Вие работите известно време (обикновено в topic клон) и сливате работата си в master клона, когато е свършена.
Когато желаете да споделите тази работа, вие изтегляте и сливате вашия master с origin/master, ако той е променен, накрая публикувате master клона си в сървъра.
Общата последователност изглежда подобно:
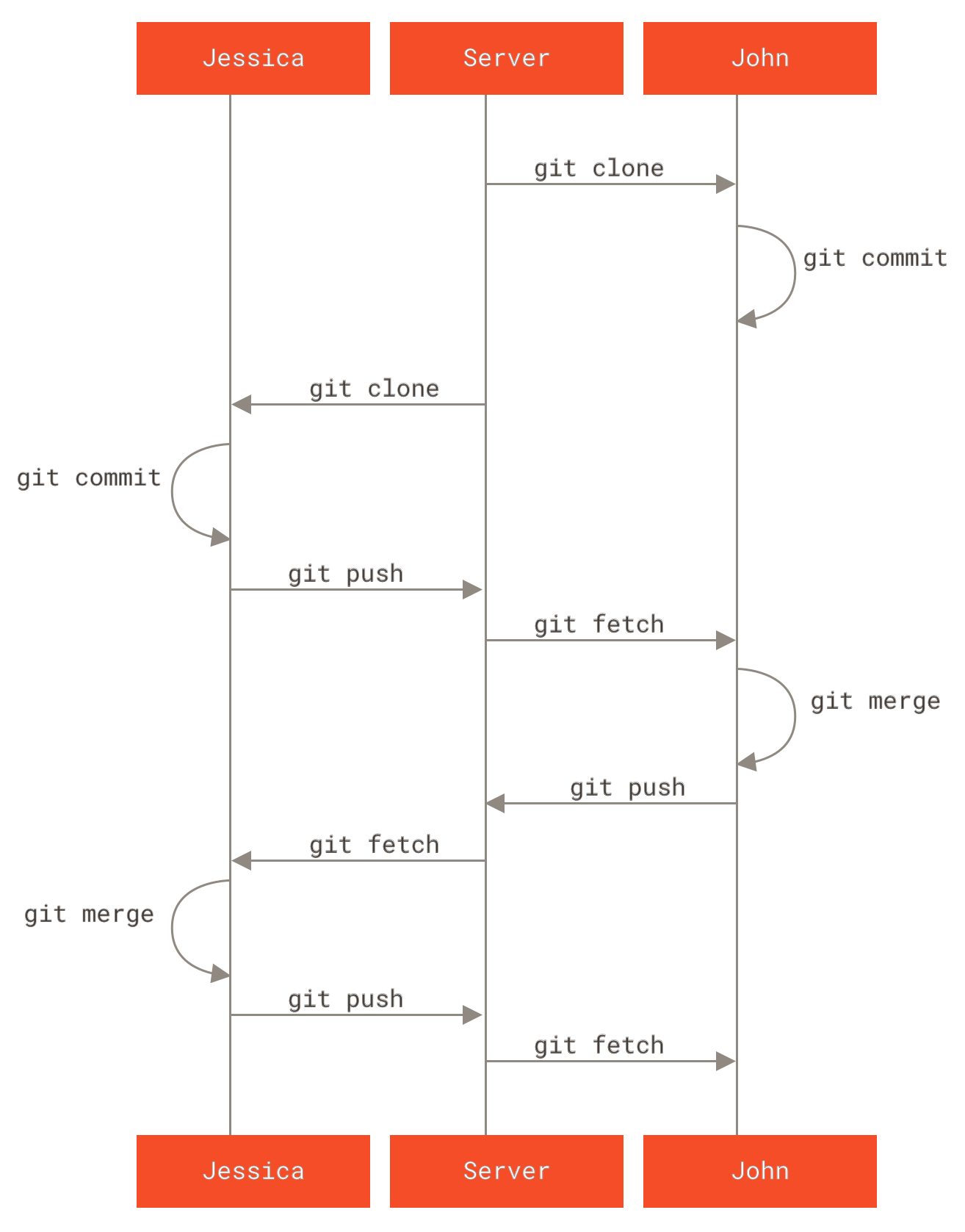
==== Работа в управляван екип
В този сценарий, ще разгледаме как да допринасяме в по-голям частен екип от разработчици. Ще разберете как да работите в обкръжение, в което малки групи си сътрудничат по определени функционалности, след което резултатът от работата на тези групи се интегрира в проекта от трети човек.
Нека приемем, че John и Jessica работят по функционалността “feature A”, докато Jessica и друг програмист, Josie, работят по друга опция, “feature B”.
В този случай, компанията използва работен процес от тип integration-manager, при който работата на индивидуалните групи се интегрира само от определени хора и master клонът на главното хранилище може да се обновява само от тези хора.
В сценарий като този, цялата работа се върши в екипни клонове, които интеграторите събират по-късно.
Нека проследим работата на Jessica, защото тя работи по две неща, в паралел с двама различни разработчици.
Допускаме, че тя вече има клонирано своето хранилище и решава да започне работа първо по featureA.
Тя създава нов клон и работи по него тук:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch 'featureA'
$ vim lib/simplegit.rb
$ git commit -am 'Add limit to log function'
[featureA 3300904] Add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)В този момент, тя трябва да сподели работата си с John, така че изпраща къмитите от клона featureA към сървъра.
Тя обаче няма push достъп до master клона, само интеграторите имат такъв — ето защо трябва да публикува в друг клон, за да работи съвместно с John:
$ git push -u origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica изпраща на John съобщение за това, че е изпратила своята работа в клон наречен feature A и сега той може да го погледне.
Докато чака за мнението на John, Jessica решава да започне работа по feature B с Josie.
За да започне, тя стартира нов feature клон, базирайки го на master клона от сървъра:
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch 'featureB'Сега тя прави няколко къмита в клона featureB:
$ vim lib/simplegit.rb
$ git commit -am 'Make ls-tree function recursive'
[featureB e5b0fdc] Make ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'Add ls-files'
[featureB 8512791] Add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)Хранилището на Jessica сега изглежда така:
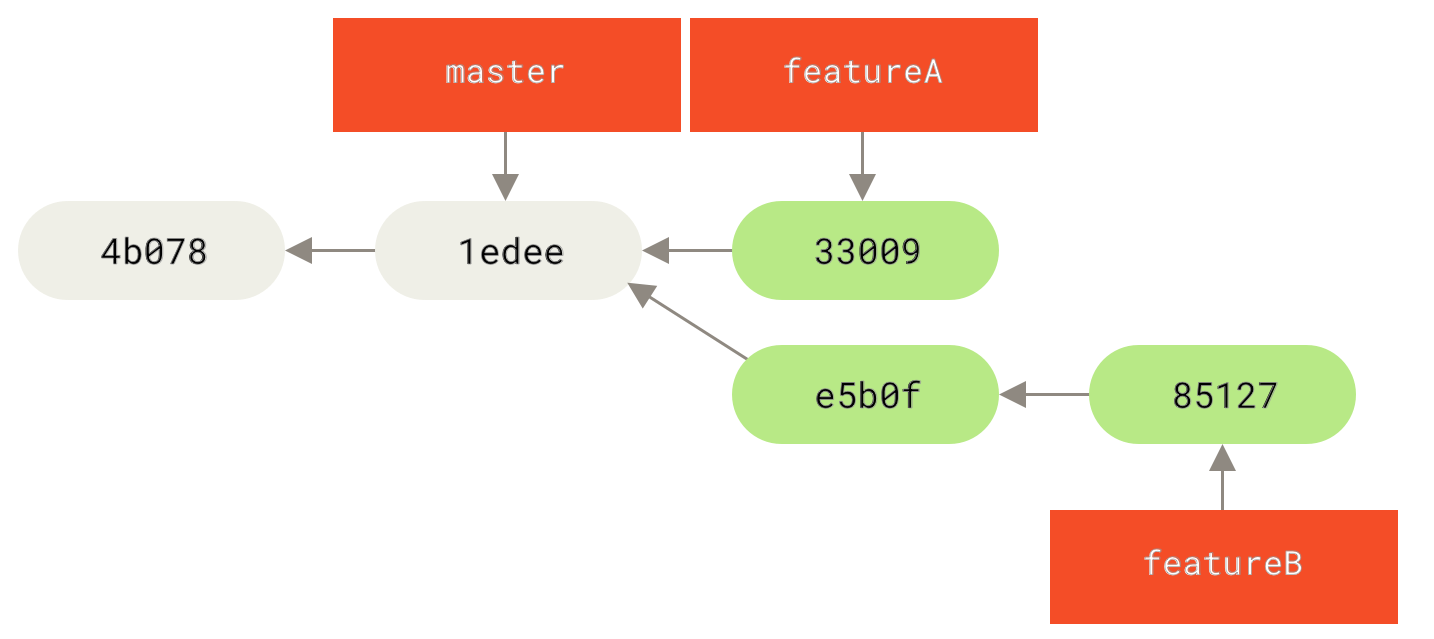
Готова е да изпрати своята работа, но в този момент получава имейл от Josie, в който се съобщава, че на сървъра вече има създаден клон с някаква предварително свършена работа по “featureB”. Този клон се казва featureBee.
Jessica сега трябва първо да слее тези промени със своите собствени преди да може да изпрати към сървъра.
Тя изтегля промените на Josie с git fetch:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBeeПриемайки, че локално тя е все още в клона featureB, тя може да слее работата на Josie с git merge:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by the 'recursive' strategy.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)В този момент, тя иска да изпрати цялата си слята работа от “featureB” обратно към сървъра, но не иска да го направи просто изпращайки своя собствен featureB клон.
Вместо това, понеже Josie вече е направил upstream featureBee клон, Jessica ще иска да изпраща промените си именно към този клон, затова тя прави така:
$ git push -u origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBeeТова се нарича refspec, указване на референция.
Вижте Refspec спецификации за повече детайли относно Git refspecs и различните възможности, които ви се предоставят с тях.
Отбележете също -u флага; това е съкращение за --set-upstream, който аргумент конфигурира клоновете за лесно дърпане и изпращане.
Внезапно Jessica получава имейл от John, който ѝ казва, че е публикувал някои промени по featureA клона, по който си сътрудничат и моли Jessica да ги погледне.
Отново, Jessica изпълнява git fetch за да изтегли цялото ново съдържание от сървъра, включително последните промени на John:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureAJessica може да покаже историята на промените на John сравнявайки съдържанието на новоизвлечения featureA клон с локалното копие на същия такъв:
$ git log featureA..origin/featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
Increase log output to 30 from 25Ако Jessica харесва това, което вижда, тя може да слее промените от John в локалния си featureA клон:
$ git checkout featureA
Switched to branch 'featureA'
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Накрая, Jessica може да желае да направи няколко малки корекции към цялото това слято съдържание, така че е свободна да ги реализира, да ги къмитне в локалния featureA клон, и да публикува финалния резултат на сървъра:
$ git commit -am 'Add small tweak to merged content'
[featureA 774b3ed] Add small tweak to merged content
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureAСега историята на къмитите на Jessica ще изглежда по подобен начин:
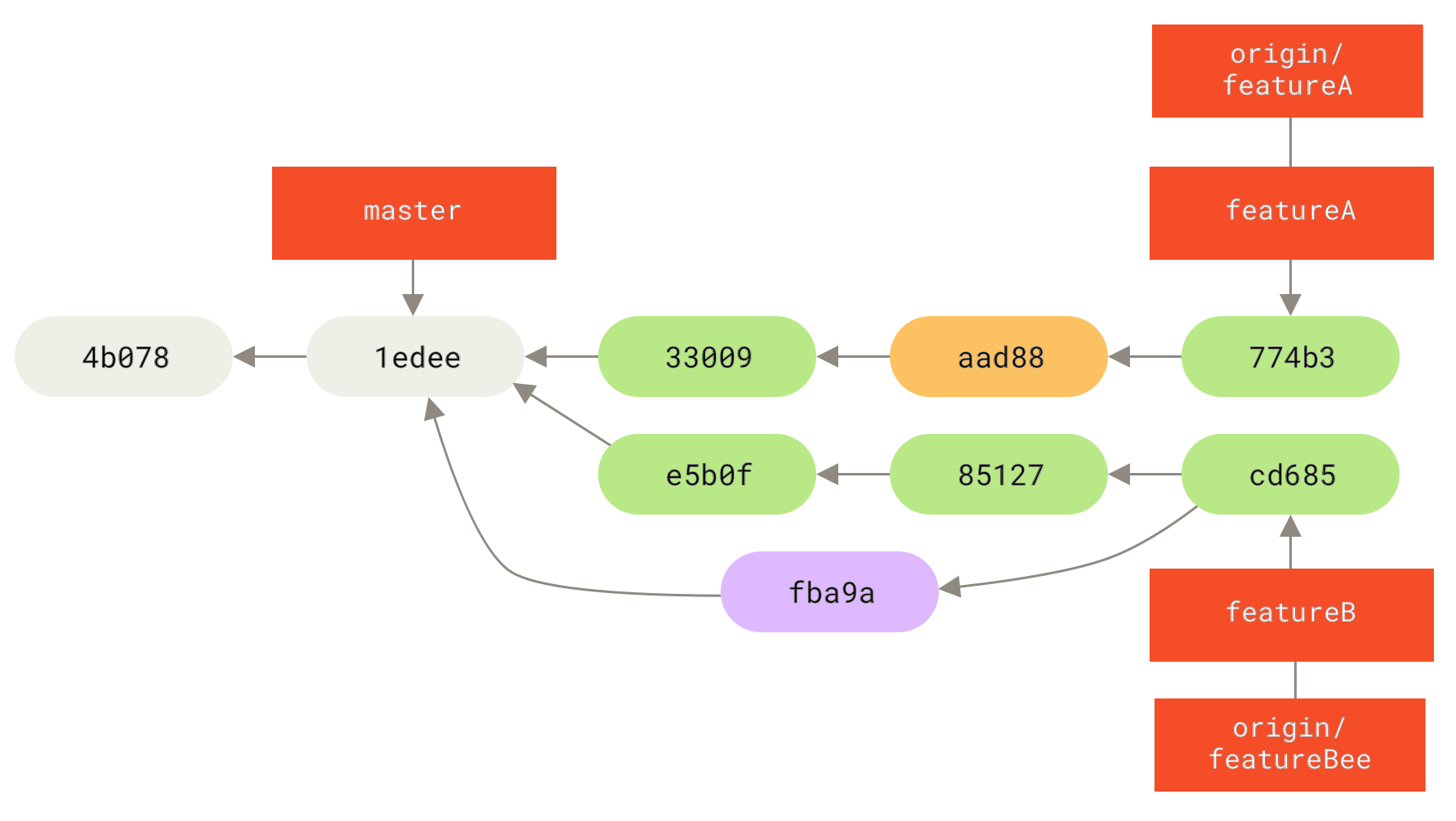
В даден момент, Jessica, Josie и John информират интеграторите, че featureA и featureBee клоновете на сървъра са готови за интегриране.
След като интеграторите слеят тези клонове в основния проект, едно изтегляне ще предостави новия merge къмит, променяйки историята така:
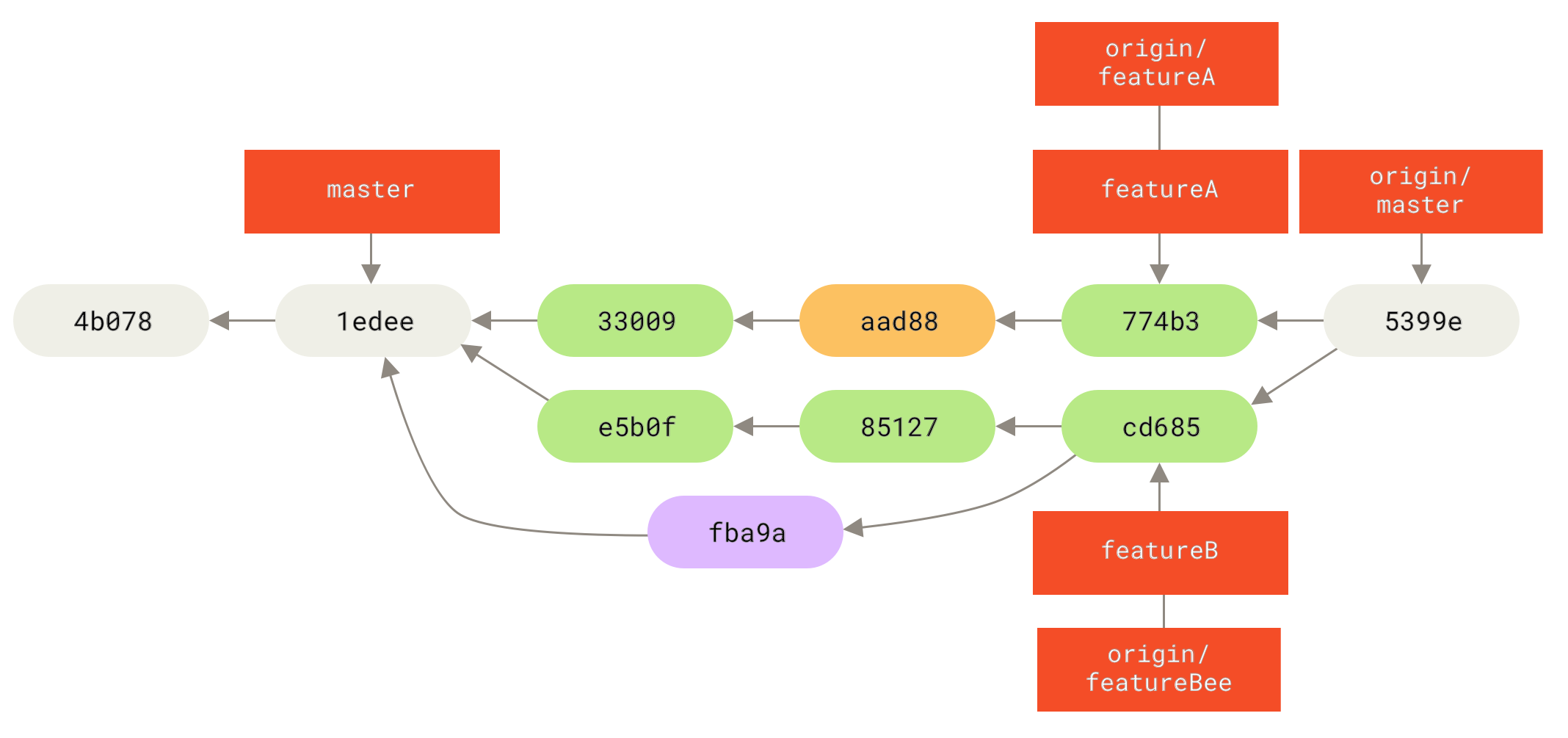
Много екипи преминават към Git поради възможностите за паралелна работа на множество тимове и сливане на различните работни нишки по-късно в процеса. Възможността малки подгрупи от един екип да работят съвместно чрез отдалечени клонове без да е необходимо да въвличат в това целия екип или да възпрепятстват работата на другите, е огромно преимущество с Git. Последователността на работния процес, който описахме, би могла да се илюстрира така:
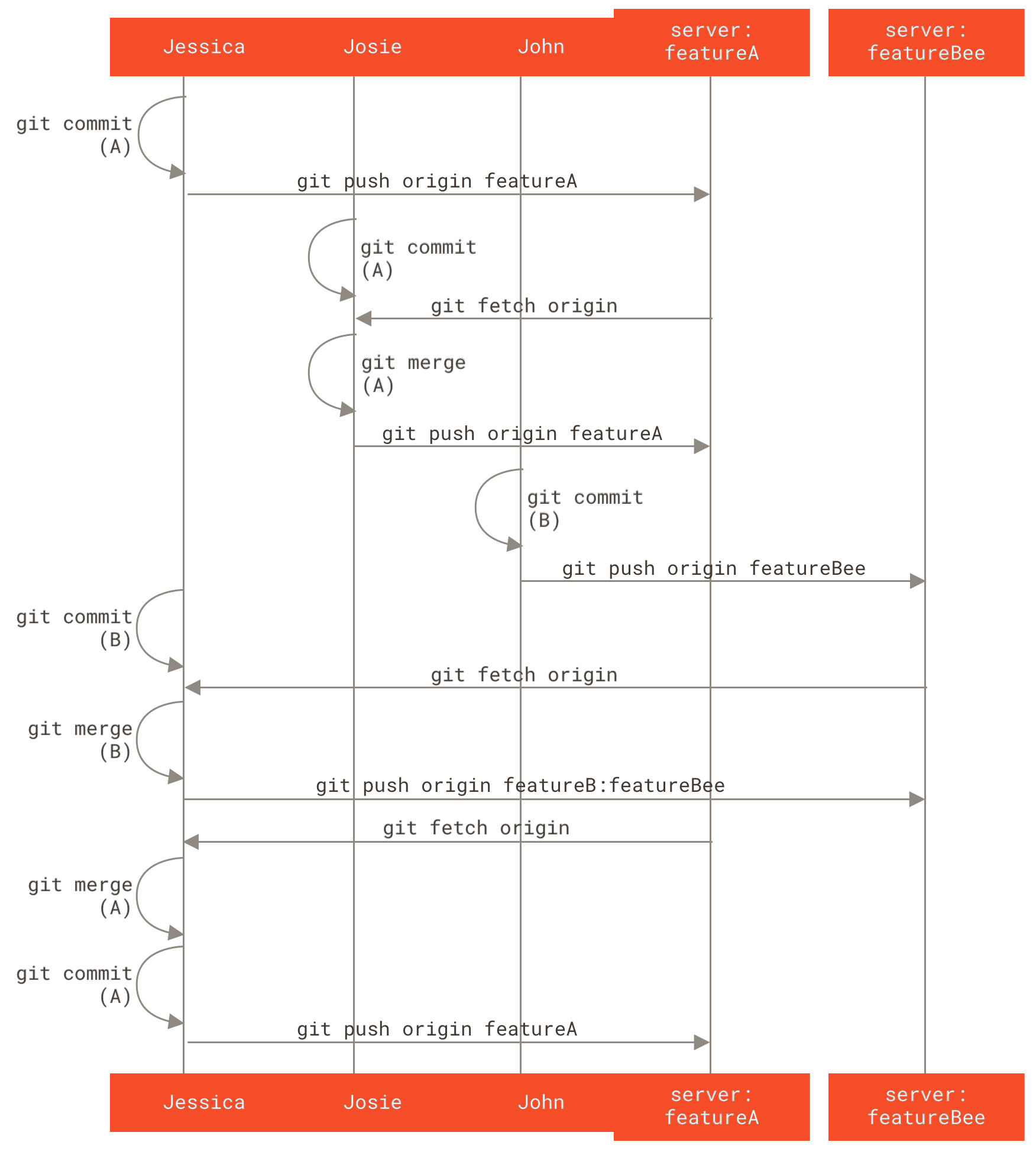
==== Клониран публичен проект
Допринасянето към публични проекти е малко по-различно. Понеже нямате права директно да обновявате клоновете на един такъв проект, по някакъв начин трябва да изпратите работата си до хората, които го поддържат. Този първи пример описва как се сътрудничи чрез клониране на Git хостове, които поддържат easy forking. Много от публичните хостинг платформи (вкл. GitHub, BitBucket, repo.or.cz, и други), както и много от поддържащите дадени проекти, очакват именно такъв подход за външна помощ. Следващата секция се занимава с проекти, които предпочитат да приемат предложените пачове чрез имейл.
Първо, вероятно ще искате да клонирате главното хранилище, да създадете topic клон за пача или серията пачове, които планирате да предложите, и да работите в него. Последователността изглежда така:
$ git clone <url>
$ cd project
$ git checkout -b featureA
... work ...
$ git commit
... work ...
$ git commitМоже да искате да използвате rebase -i за да съберете работата си в единичен къмит, или пък да реорганизирате нещата в множество къмити, така че мениджърът на проекта по-лесно да я разгледа — вижте Манипулация на историята за повече информация за интерактивното пребазиране.
Когато работата ви по клона е завършена и сте готови да я предложите на поддържащите проекта, отидете обратно в неговата страница и използвайте бутона “Fork”, така че да си направите свое собствено копие от проекта в сайта, с права за писане в него.
След това трябва да добавите URL-а на копието като нова отдалечена референция за локалното ви хранилище, за този пример - нека да я наречем myfork:
$ git remote add myfork <url>След това трябва да публикувате локалната си работа в това отдалечено хранилище.
Най-лесно е да публикувате topic клона, по който работите, вместо първо са го сливате в master клона и да публикувате него.
Причината за това е, че ако работата не бъде приета или е cherry-picked, няма да има нужда да превъртате обратно вашия master клон (cherry-pick операцията на Git се разглежда в повече подробности в Rebasing и Cherry-Picking работни процеси).
Ако поддържащите проекта слеят, пребазират, или cherry-pick-нат вашата работа, в крайна сметка ще я получите обратно чрез издърпване от тяхното хранилище.
Във всеки случай, можете да публикувате работата си чрез:
$ git push -u myfork featureA
След като работата ви е била публикувана във вашето клонирано онлайн хранилище, ще трябва да уведомите поддържащите оригиналния проект, че имате промени, които бихте искали да интегрират.
Това често се нарича pull request и обикновено такава заявка се генерира или директно през уеб сайта — GitHub има собствен “Pull Request” механизъм, който ще видим в GitHub — или пък с командата git request-pull чийто изход трябва да изпратите по имейл на мениджъра на проекта ръчно.
Командата git request-pull взема за параметри базовия клон, в който искате промените ви да бъдат интегрирани и адреса на Git хранилището, от което тези промени да бъдат изтеглени, след което изготвя списък с всички промени, които искате да бъдат изтеглени.
Например, ако Jessica иска да изпрати на John pull request и е направила два къмита в topic клона, който току що е публикувала, тя може да изпълни следното:
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
Jessica Smith (1):
Create new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
Add limit to log function
Increase log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Този изход може да се изпрати към поддържащия проекта — той ще покаже откъде е разклонена работата, обобщава къмитите и указва откъде може да се изтегли новата работа.
В проект, който не поддържате, обикновено е по-лесно да имате клон като master, който винаги следи origin/master ` и да вършите работата си в topic клонове, които лесно можете да премахнете, в случай че бъдат отхвърлени.
Изолирането на работата в topic клонове също така прави по-лесно пребазирането на вашата работа, ако "върха" на главното хранилище се премести междувременно и къмитите ви вече не се прилагат чисто.
Например, ако искате да изпратите втора промяна в проекта, не продължавайте да работите в topic клона, който вече сте изпратили — започнете от `master клона на главното хранилище:
$ git checkout -b featureB origin/master
... work ...
$ git commit
$ git push myfork featureB
$ git request-pull origin/master myfork
... email generated request pull to maintainer ...
$ git fetch originСега, всяка от промените ви се съдържа в силоз — подобно на опашка от пачове — които можете да пренапишете, пребазирате и променяте без различните теми да се преплитат или да зависят една от друга:
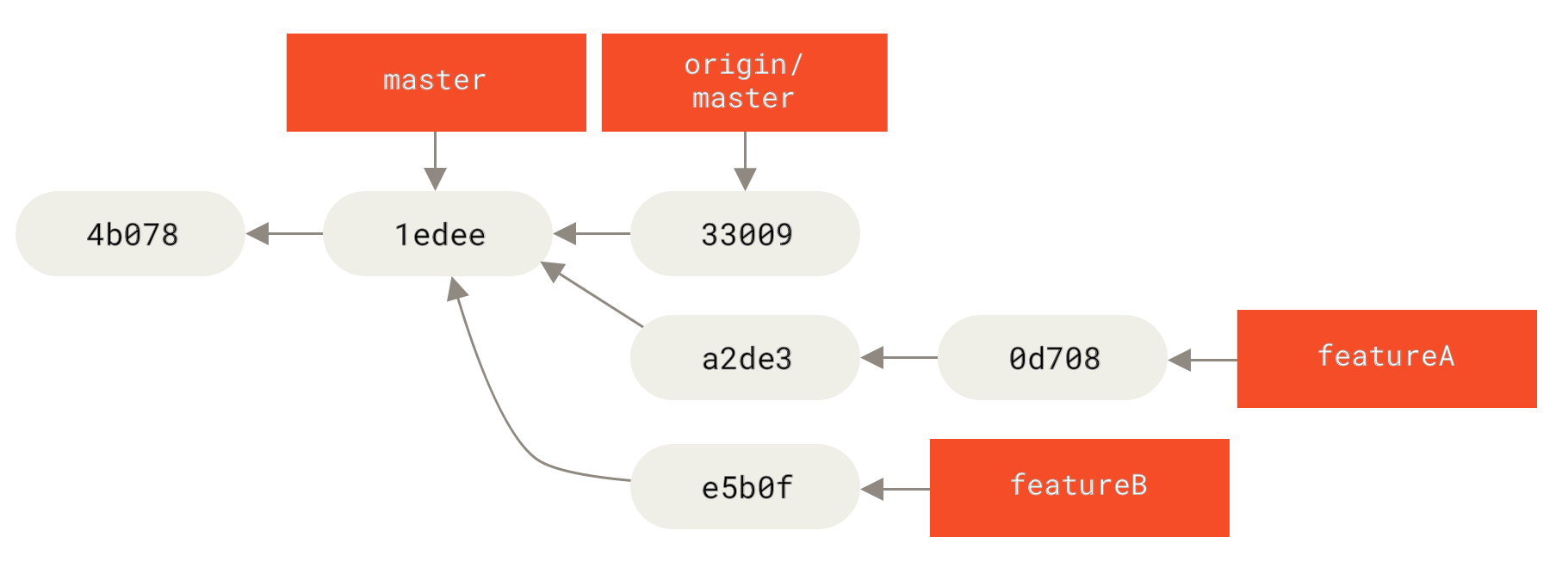
featureB
Да кажем, че мениджърът на проекта е интегрирал множество други пачове и е опитал вашия първи клон, който обаче вече не се слива чисто.
В този случай, можете да пробвате да пребазирате този клон върху origin/master, да оправите конфликтите и да изпратите повторно промените си:
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureAТова ще промени историята ви така:
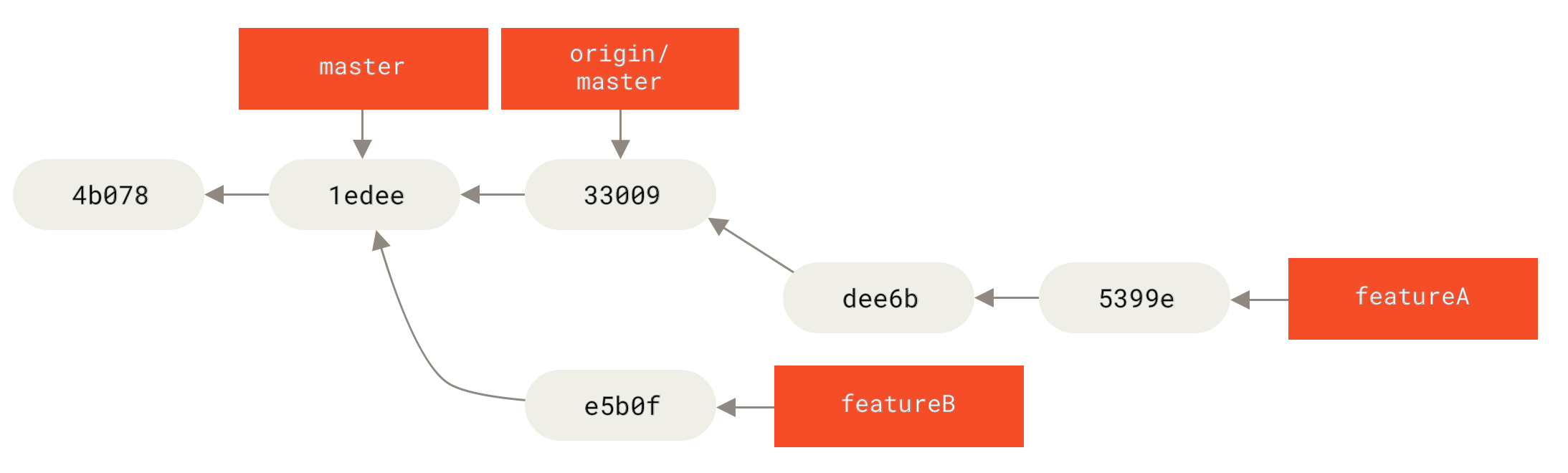
featureA
Понеже пребазирахте клона, трябва да подадете параметъра -f към push командата за да можете да замените featureA клона на сървъра с къмит, който не е негов наследник.
Като алтернатива, можете да публикувате тази нова работа към различен клон в сървъра (например featureAv2).
Нека погледнем още един възможен сценарий: поддържащият проекта е погледнал работата във втория ви клон и харесва идеята ви, но би желал да промените малко имплементацията.
Вие също ще се възползвате от тази възможност за да преместите работата си така, че да е базирана на текущия master клон на проекта.
Стартирате нов клон базиран на текущия origin/master, премествате featureB промените в него, решавате евентуалните конфликти, променяте имплементацията и го публикувате като нов клон:
$ git checkout -b featureBv2 origin/master
$ git merge --squash featureB
... change implementation ...
$ git commit
$ git push myfork featureBv2Опцията --squash взема цялата работа от слетия клон и я събира в едно множество промени, в резултат на което статусът на хранилището ще изглежда така сякаш е станало реално сливане, без в действителност да се прави merge къмит.
Това означава, че бъдещият ви къмит ще има само един родител и ви позволява да въведете всички промени от друг клон и да направите още такива преди да запишете новия къмит.
Също така, опцията --no-commit може да е полезна за отлагане на merge къмита в случай на нормален процес по сливане.
В този момент, можете да уведомите поддържащия проекта, че сте направили поисканите промени и те могат да се намерят в клона featureBv2.
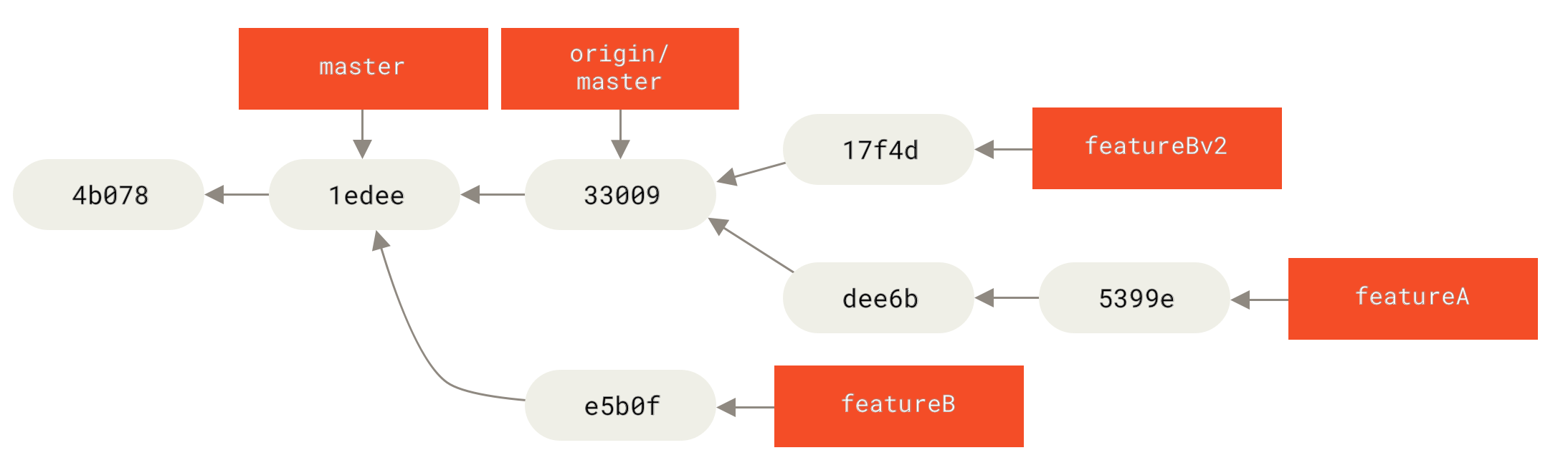
featureBv2.==== Публичен проект с комуникация по имейл
Много проекти имат установени процедури за приемане на пачове — ще трябва да проверите специфичните изисквания според вашия случай. Понеже все още съществуват множество по-стари, големи по мащаб проекти, които приемат пачовете през мейлинг лист за разработчици, ще дадем и един пример за такъв случай.
Работният процес е подобен на предишния — вие създавате topic клонове за всяка серия от пачове, по която работите. Разликата е в това как ги изпращате към проекта. Вместо да клонирате проекта и да публикувате във вашата версия, в която имате права за писане, вие генерирате имейл версии на всяка серия къмити и ги изпращате към мейлинг лист:
$ git checkout -b topicA
... work ...
$ git commit
... work ...
$ git commit
Сега имате два къмита, които искате да пратите.
Използвате git format-patch командата, за да генерирате mbox-форматирани файлове, които можете да пратите към списъка — тя превръща всеки къмит в имейл съобщение със subject отговарящ на първия ред от къмит съобщението и останалата част от съобщението плюс пача - като тяло на имейла.
Хубавото на това е, че прилагането на пач от имейл съобщение генерирано с тази команда запазва коректно цялата информация за къмита.
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-increase-log-output-to-30-from-25.patchКомандата format-patch отпечатва имената на пач-файловете, които създава.
Параметърът -M казва на Git да търси за преименувания.
Файловете изглеждат така:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
2.1.0Можете също да редактирате пач файловете за да добавите допълнителна информация за мейлинг листата, която не желаете да се показва в къмит съобщението.
Ако добавите текст между реда --- и началото на пача (реда diff --git), то разработчиците могат да я четат, но това съдържание ще бъде игнорирано от процеса по пачването.
За да изпратите това към листата, можете или да копирате файла в имейл програмата си или да използвате програма за изпращане на поща от команден ред.
Копирането на текст често предизвиква проблеми с форматирането, особено с “по-умните” клиенти, които не запазват новите редове и празните символи коректно.
За щастие, Git предоставя инструмент за изпращане на правилно форматирани пачове през IMAP, което може да е по-лесно за вас.
Ще покажем как да изпращаме пач през Gmail, тъй като е много популярна услуга, но можете да намерите детайлни инструкции за използването на много други имейл клиенти в края на гореспоменатия файл Documentation/SubmittingPatches в сорс кода на Git.
Първо, трябва да подготвите imap секцията във вашия ~/.gitconfig файл.
Можете да настроите всяка стойност отделно чрез серия от git config команди или пък да ги въведете ръчно, но независимо от подхода, конфигурационният файл ще изглежда по подобен начин:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = YX]8g76G_2^sFbd
port = 993
sslverify = falseАко IMAP сървърът ви не използва SSL, то последните два реда вероятно няма да са нужни и стойността за хоста ще започва с imap:// вместо с imaps://.
Когато това е готово, можете да използвате командата git imap-send за да поставите пачовете в Drafts папката на указания IMAP сървър:
$ cat *.patch |git imap-send
Resolving imap.gmail.com... ok
Connecting to [74.125.142.109]:993... ok
Logging in...
sending 2 messages
100% (2/2) doneВ този момент, би трябвало да можете да отворите Drafts папката, да смените To полето към адреса на мейлинг-листата, към която изпращате пача, вероятно да добавите CC поле за поддържащия проекта или човекът, който отговаря за тази секция и да изпратите пощата.
Можете да изпращате и през SMTP сървър.
Както и преди, ще трябва да отразите промените в ~/.gitconfig, в секцията му sendemail, ръчно или с git config команди:
[sendemail]
smtpencryption = tls
smtpserver = smtp.gmail.com
smtpuser = user@gmail.com
smtpserverport = 587След това, използвайте командата git send-email за да изпратите пачовете си:
$ git send-email *.patch
0001-add-limit-to-log-function.patch
0002-increase-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? yСлед това Git показва множество лог информация, която изглежда по подобен начин за всеки от пачовете:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] Add limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OKЗа повече информация относно конфигурирането на вашата система за работа с имейли, съвети и трикове, както и sandbox за изпращане на примерни пачове по електронна поща, посетете git-send-email.io.
Обобщение
В тази секция разгледахме различни работни процеси и разликите в работата в малък екип с closed-source проекти и тази при сътрудничество в голям публиен проект. Сега знаете, че трябва да проверявате за white-space грешки преди къмитването и да пишете перфектни къмит съобщения. Научихме как да форматираме пачове и да ги разпращаме по пощата до мейлинг-листа на разработчиците. В контекста на различните работни процеси обърнахме внимание и на особеностите при сливане. Сега сме достатъчно подготвени да сътрудничим в произволен проект.
Следва да погледнем от обратната страна на монетата: поддържането на Git проект. Ще научите как да изпълнявате ролите на benevolent dictator или integration manager.