
-
1. Inicio - Sobre el Control de Versiones
-
2. Fundamentos de Git
-
3. Ramificaciones en Git
-
4. Git en el Servidor
- 4.1 Los Protocolos
- 4.2 Configurando Git en un servidor
- 4.3 Generando tu clave pública SSH
- 4.4 Configurando el servidor
- 4.5 El demonio Git
- 4.6 HTTP Inteligente
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Git en un alojamiento externo
- 4.10 Resumen
-
5. Git en entornos distribuidos
-
6. GitHub
-
7. Herramientas de Git
- 7.1 Revisión por selección
- 7.2 Organización interactiva
- 7.3 Guardado rápido y Limpieza
- 7.4 Firmando tu trabajo
- 7.5 Buscando
- 7.6 Reescribiendo la Historia
- 7.7 Reiniciar Desmitificado
- 7.8 Fusión Avanzada
- 7.9 Rerere
- 7.10 Haciendo debug con Git
- 7.11 Submódulos
- 7.12 Agrupaciones
- 7.13 Replace
- 7.14 Almacenamiento de credenciales
- 7.15 Resumen
-
8. Personalización de Git
-
9. Git y Otros Sistemas
- 9.1 Git como Cliente
- 9.2 Migración a Git
- 9.3 Resumen
-
10. Los entresijos internos de Git
-
A1. Apéndice A: Git en otros entornos
- A1.1 Interfaces gráficas
- A1.2 Git en Visual Studio
- A1.3 Git en Eclipse
- A1.4 Git con Bash
- A1.5 Git en Zsh
- A1.6 Git en Powershell
- A1.7 Resumen
-
A2. Apéndice B: Integrando Git en tus Aplicaciones
- A2.1 Git mediante Línea de Comandos
- A2.2 Libgit2
- A2.3 JGit
-
A3. Apéndice C: Comandos de Git
- A3.1 Configuración
- A3.2 Obtener y Crear Proyectos
- A3.3 Seguimiento Básico
- A3.4 Ramificar y Fusionar
- A3.5 Compartir y Actualizar Proyectos
- A3.6 Inspección y Comparación
- A3.7 Depuración
- A3.8 Parcheo
- A3.9 Correo Electrónico
- A3.10 Sistemas Externos
- A3.11 Administración
- A3.12 Comandos de Fontanería
5.2 Git en entornos distribuidos - Contribuyendo a un Proyecto
Contribuyendo a un Proyecto
La principal dificultad con la descripción de cómo contribuir a un proyecto es que hay una gran cantidad de variaciones sobre cómo se hace. Debido a que Git es muy flexible, las personas pueden trabajar juntas de muchas maneras, y es problemático describir cómo deberían contribuir: cada proyecto es un poco diferente. Algunas de las variables involucradas son conteo de contribuyentes activos, flujo de trabajo elegido, acceso de confirmación y posiblemente el método de contribución externa.
La primera variable es el conteo de contribuyentes activos: ¿cuántos usuarios están contribuyendo activamente al código de un proyecto y con qué frecuencia? En muchos casos, tendrá dos o tres desarrolladores con algunos commits por día o posiblemente menos para proyectos un tanto inactivos. Para empresas o proyectos más grandes, la cantidad de desarrolladores podría ser de miles, con cientos o miles de compromisos cada día. Esto es importante porque con más y más desarrolladores, se encontrará con más problemas para asegurarse de que su código se aplique de forma limpia o se pueda fusionar fácilmente. Los cambios que envíe pueden quedar obsoletos o severamente interrumpidos por el trabajo que se fusionó mientras estaba trabajando o mientras los cambios estaban esperando ser aprobados o aplicados. ¿Cómo puede mantener su código constantemente actualizado y sus confirmaciones válidas?
La siguiente variable es el flujo de trabajo en uso para el proyecto. ¿Está centralizado, con cada desarrollador teniendo el mismo acceso de escritura a la línea de código principal? ¿El proyecto tiene un mantenedor o un gerente de integración que verifica todos los parches? ¿Están todos los parches revisados por pares y aprobados? ¿Está usted involucrado en ese proceso? ¿Hay un sistema de tenientes en su lugar, y tiene que enviar su trabajo primero?
El siguiente problema es su acceso de confirmación. El flujo de trabajo requerido para contribuir a un proyecto es muy diferente si usted tiene acceso de escritura al proyecto que si no lo tiene. Si no tiene acceso de escritura, ¿cómo prefiere el proyecto aceptar el trabajo contribuido? ¿Incluso tiene una política? ¿Cuánto trabajo estás contribuyendo a la vez? ¿Con qué frecuencia contribuye?
Todas estas preguntas pueden afectar la forma en que se contribuye de manera efectiva a un proyecto y los flujos de trabajo preferidos o disponibles para usted. Cubriremos aspectos de cada uno de éstos en una serie de casos de uso, pasando de simples a más complejos; debería poder construir los flujos de trabajo específicos que necesita en la práctica a partir de estos ejemplos.
Pautas de confirmación
Antes de comenzar a buscar casos de uso específicos, aquí hay una nota rápida sobre los mensajes de confirmación.
Tener una buena guía para crear compromisos y apegarse a ella hace que trabajar con Git y colaborar con otros sea mucho más fácil.
El proyecto Git proporciona un documento que presenta una serie de buenos consejos para crear compromisos a partir de los cuales enviar parches: puede leerlos en el código fuente de Git en el archivo Documentation / SubmittingPatches.
En primer lugar, no desea enviar ningún error de espacios en blanco.
Git proporciona una manera fácil de verificar esto: antes de comprometerse, ejecute git diff --check, que identifica posibles errores de espacio en blanco y los enumera por usted.
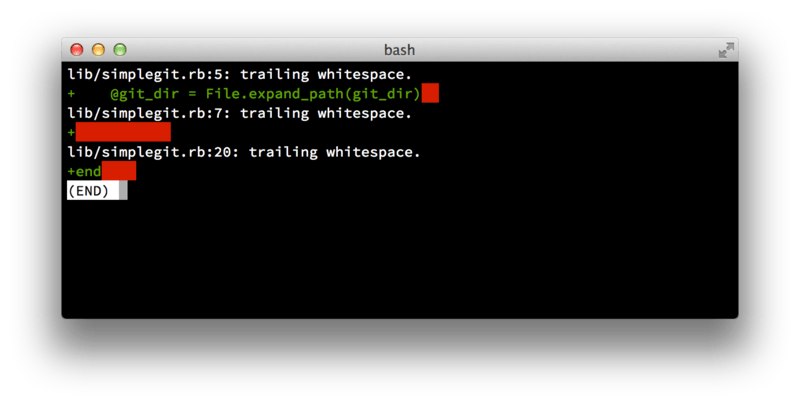
git diff --check.Si ejecuta ese comando antes de confirmar, puede ver si está a punto de cometer errores de espacio en blanco que pueden molestar a otros desarrolladores.
A continuación, intente hacer de cada commit un conjunto de cambios lógicamente separado.
Si puede, trate de hacer que sus cambios sean digeribles: no codifique durante un fin de semana entero en cinco asuntos diferentes para luego envíarlos todos como un compromiso masivo el lunes.
Incluso si no confirma durante el fin de semana, utilice el área de etapas el lunes para dividir su trabajo en al menos una confirmación por cuestión, con un mensaje útil por confirmación.
Si algunos de los cambios modifican el mismo archivo, intente utilizar git add --patch para representar parcialmente los archivos (se detalla en << _ interactive_staging >>).
La instantánea del proyecto en la punta de la rama es idéntica, ya sea que realice una confirmación o cinco, siempre que todos los cambios se agreguen en algún momento, así que trate de facilitar las cosas a sus compañeros desarrolladores cuando tengan que revisar sus cambios.
Este enfoque también hace que sea más fácil retirar o revertir uno de los conjuntos de cambios si lo necesita más adelante.
<< _ rewriting_history >> describe una serie de trucos útiles de Git para reescribir el historial y organizar de forma interactiva los archivos: use estas herramientas para crear un historial limpio y comprensible antes de enviar el trabajo a otra persona.
Lo último a tener en cuenta es el mensaje de compromiso. Tener el hábito de crear mensajes de compromiso de calidad hace que usar y colaborar con Git sea mucho más fácil. Como regla general, sus mensajes deben comenzar con una sola línea que no supere los 50 caracteres y que describa el conjunto de cambios de forma concisa, seguido de una línea en blanco, seguida de una explicación más detallada. El proyecto Git requiere que la explicación más detallada incluya su motivación para el cambio y contraste su implementación con el comportamiento anterior: esta es una buena guía a seguir. También es una buena idea usar el tiempo presente imperativo en estos mensajes. En otras palabras, use comandos. En lugar de ‘` agregué pruebas para ’ o ‘` Añadir pruebas para ', use `` Agregar pruebas para '’. Aquí hay una plantilla escrita originalmente por Tim Pope:
Resumen de cambios cortos (50 caracteres o menos)
Texto explicativo más detallado, si es necesario. Ajustarlo a
aproximadamente 72 caracteres más o menos. En algunos contextos, la primera
línea se trata como el tema de un correo electrónico y el resto de
el texto como el cuerpo. La línea en blanco que separa el
resumen del cuerpo es crítica (a menos que omita el cuerpo
enteramente); herramientas como ``rebase'' pueden confundirse si ejecuta
los dos juntos.
Otros párrafos vienen después de las líneas en blanco.
- Los puntos de viñetas también están bien
- Típicamente se usa un guión o asterisco para la viñeta,
precedido por un solo espacio, con líneas en blanco
entre viñetas, pero las convenciones varían aquíSi todos sus mensajes de confirmación se ven así, las cosas serán mucho más fáciles para usted y para los desarrolladores con los que trabaja.
El proyecto Git tiene mensajes de confirmación bien formateados. Intente ejecutar git log --no-merges allí para ver cómo se ve un historial de commit de proyecto muy bien formateado.
En los siguientes ejemplos y en la mayor parte de este libro, en aras de la brevedad, no verá mensajes con un formato agradable como éste; en cambio, usamos la opción -m para` git commit`.
Haz lo que decimos, no como lo hacemos.
Pequeño equipo privado
La configuración más simple que es probable encuentre, es un proyecto privado con uno o dos desarrolladores más. ‘` Privado '’, en este contexto, significa fuente cerrada, no accesible para el mundo exterior. Usted y los demás desarrolladores son los únicos que tienen acceso de inserción al repositorio.
En este entorno, puede seguir un flujo de trabajo similar a lo que podría hacer al usar Subversion u otro sistema centralizado.
Aún obtiene las ventajas de cosas como el compromiso fuera de línea y una bifurcación y fusión mucho más simples, pero el flujo de trabajo puede ser muy similar; la principal diferencia es que las fusiones ocurren en el lado del cliente en lugar del servidor en el momento de la confirmación.
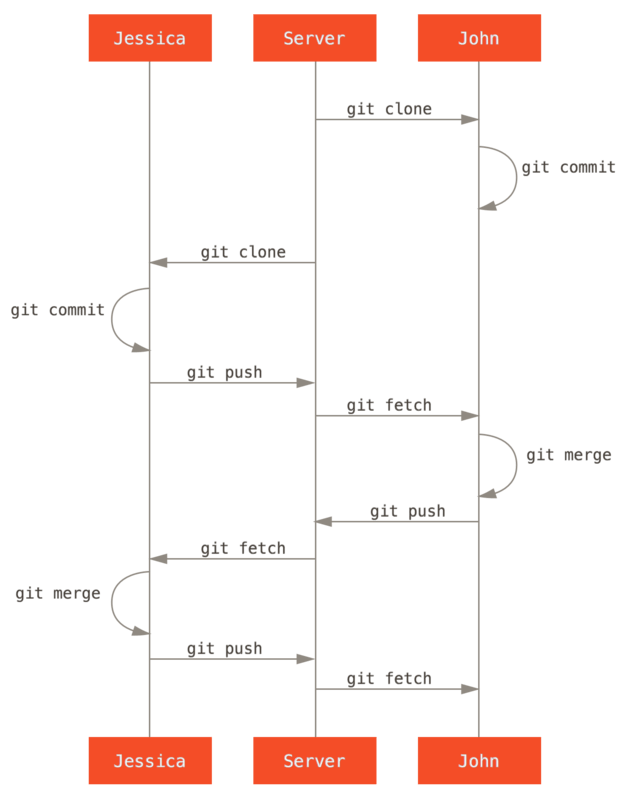
Veamos cómo se vería cuando dos desarrolladores comiencen a trabajar juntos con un repositorio compartido.
El primer desarrollador, John, clona el repositorio, hace un cambio y se compromete localmente.
(Los mensajes de protocolo se han reemplazado con ... en estos ejemplos para acortarlos un poco).
# John's Machine
$ git clone john@githost:simplegit.git
Initialized empty Git repository in /home/john/simplegit/.git/
...
$ cd simplegit/
$ vim lib/simplegit.rb
$ git commit -am 'removed invalid default value'
[master 738ee87] removed invalid default value
1 files changed, 1 insertions(+), 1 deletions(-)El segundo desarrollador, Jessica, hace lo mismo: clona el repositorio y comete un cambio:
# Jessica's Machine
$ git clone jessica@githost:simplegit.git
Initialized empty Git repository in /home/jessica/simplegit/.git/
...
$ cd simplegit/
$ vim TODO
$ git commit -am 'add reset task'
[master fbff5bc] add reset task
1 files changed, 1 insertions(+), 0 deletions(-)Ahora, Jessica lleva su trabajo al servidor:
# Jessica's Machine
$ git push origin master
...
To jessica@githost:simplegit.git
1edee6b..fbff5bc master -> masterJohn intenta impulsar su cambio, también:
# John's Machine
$ git push origin master
To john@githost:simplegit.git
! [rejected] master -> master (non-fast forward)
error: failed to push some refs to 'john@githost:simplegit.git'John no puede presionar porque Jessica ha presionado mientras tanto. Esto es especialmente importante de entender si está acostumbrado a Subversion, porque notará que los dos desarrolladores no editaron el mismo archivo. Aunque Subversion realiza automáticamente una fusión de este tipo en el servidor si se editan diferentes archivos, en Git debe fusionar los commit localmente. John tiene que buscar los cambios de Jessica y fusionarlos antes de que se le permita presionar:
$ git fetch origin
...
From john@githost:simplegit
+ 049d078...fbff5bc master -> origin/masterEn este punto, el repositorio local de John se ve así:
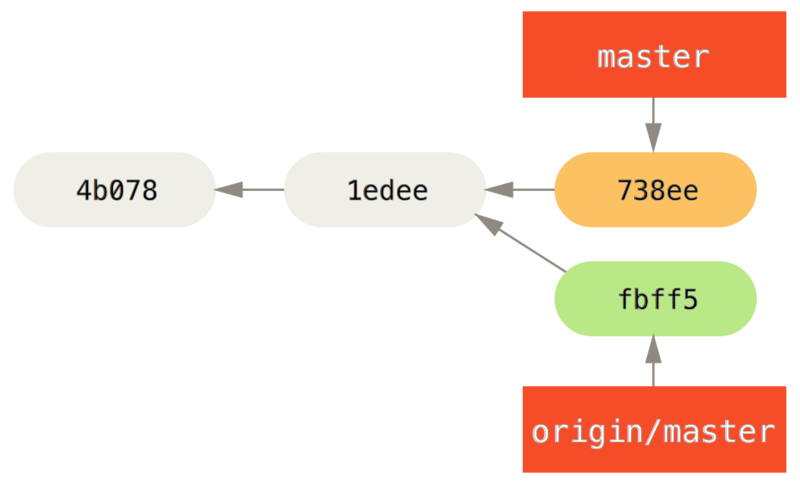
John tiene una referencia a los cambios que Jessica elevó, pero tiene que fusionarlos en su propio trabajo antes de que se le permita presionar:
$ git merge origin/master
Merge made by recursive.
TODO | 1 +
1 files changed, 1 insertions(+), 0 deletions(-)La fusión funciona sin problemas: el historial de compromisos de John ahora se ve así:
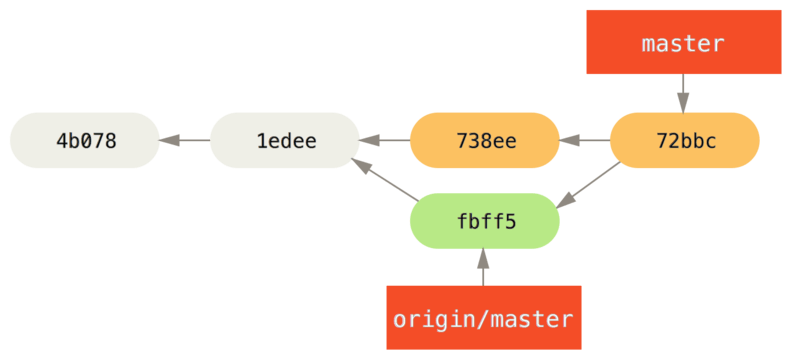
origin/master.Ahora, John puede probar su código para asegurarse de que todavía funciona correctamente, y luego puede enviar su nuevo trabajo combinado al servidor:
$ git push origin master
...
To john@githost:simplegit.git
fbff5bc..72bbc59 master -> masterFinalmente, el historial de compromisos de John se ve así:
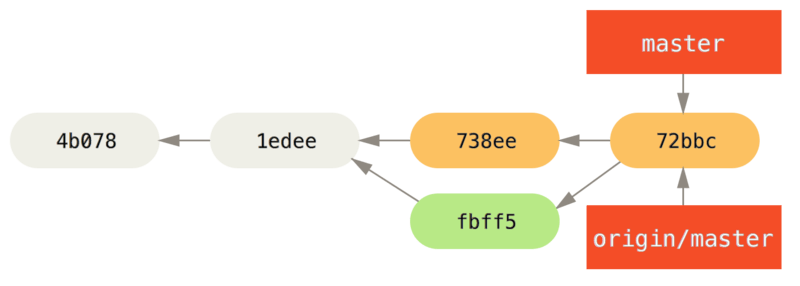
origin server.Mientras tanto, Jessica ha estado trabajando en una rama temática.
Ella creó una rama temática llamada issue54 y realizó tres commits en esa rama.
Todavía no ha revisado los cambios de John, por lo que su historial de commit se ve así:
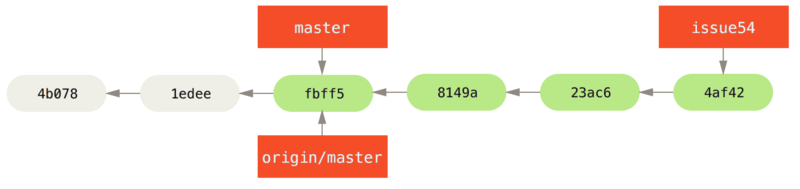
Jessica quiere sincronizar con John, así que busca:
# Jessica's Machine
$ git fetch origin
...
From jessica@githost:simplegit
fbff5bc..72bbc59 master -> origin/masterEso reduce el trabajo que John ha impulsado mientras tanto. La historia de Jessica ahora se ve así:
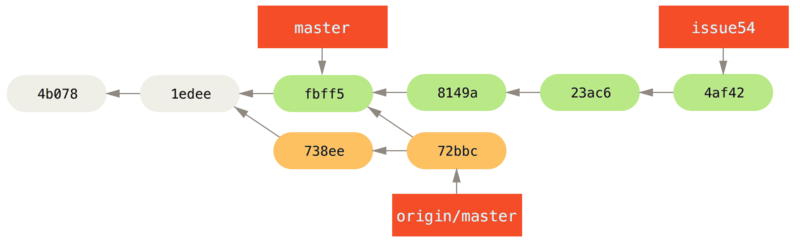
Jessica cree que su rama temática está lista, pero quiere saber qué tiene que fusionar en su trabajo para poder impulsarla.
Ella ejecuta git log para descubrir:
$ git log --no-merges issue54..origin/master
commit 738ee872852dfaa9d6634e0dea7a324040193016
Author: John Smith <jsmith@example.com>
Date: Fri May 29 16:01:27 2009 -0700
removed invalid default valueLa sintaxis issue54..origin / master es un filtro de registro que le pide a Git que sólo muestre la lista de confirmaciones que están en la última rama (en este caso` origen / maestro`) que no están en la primera rama (en este case issue54). Repasaremos esta sintaxis en detalle en << _ commit_ranges >>.
Por ahora, podemos ver en el resultado que hay un compromiso único que John ha realizado en el que Jessica no se ha fusionado. Si fusiona origen / maestro, esa es la única confirmación que modificará su trabajo local.
Ahora, Jessica puede fusionar su trabajo temático en su rama principal, fusionar el trabajo de John (origin / master) en su rama` master`, y luego volver al servidor nuevamente.
Primero, vuelve a su rama principal para integrar todo este trabajo:
$ git checkout master
Switched to branch 'master'
Your branch is behind 'origin/master' by 2 commits, and can be fast-forwarded.Ella puede fusionar ya sea origin / master o` issue54` primero - ambos están en sentido ascendente, por lo que el orden no importa.
La instantánea final debe ser idéntica sin importar qué orden ella elija; sólo la historia será ligeramente diferente.
Ella elige fusionarse en issue54 primero:
$ git merge issue54
Updating fbff5bc..4af4298
Fast forward
README | 1 +
lib/simplegit.rb | 6 +++++-
2 files changed, 6 insertions(+), 1 deletions(-)No hay problemas como pueden ver, fue un simple avance rápido.
Ahora Jessica se fusiona en el trabajo de John (origin / master):
$ git merge origin/master
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)Todo se funde limpiamente, y la historia de Jessica se ve así:
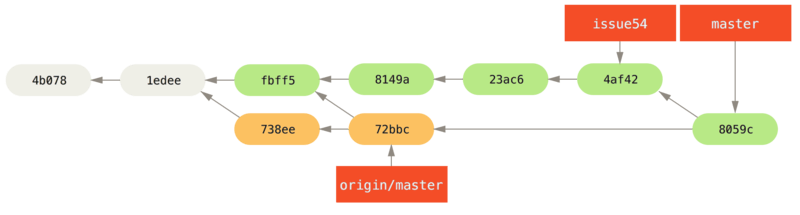
Ahora origin / master es accesible desde la rama` master` de Jessica, por lo que debería poder presionar con éxito (suponiendo que John no haya pulsado nuevamente mientras tanto):
$ git push origin master
...
To jessica@githost:simplegit.git
72bbc59..8059c15 master -> masterCada desarrollador se ha comprometido algunas veces y se ha fusionado el trabajo de cada uno con éxito.
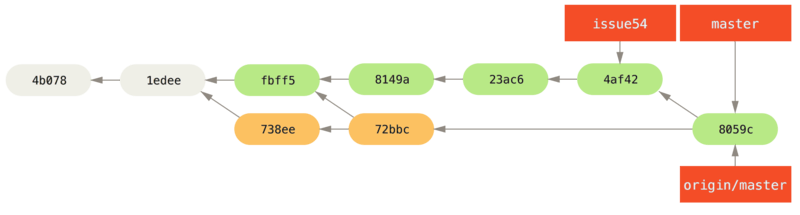
Ese es uno de los flujos de trabajo más simples.
Trabajas por un tiempo, generalmente en una rama temática, y te unes a tu rama principal cuando está lista para integrarse.
Cuando desee compartir ese trabajo, hágalo en su propia rama principal, luego busque y combine origin / master si ha cambiado, y finalmente presione en la rama` master` del servidor.
La secuencia general es algo como esto:
Equipo privado administrado
En este próximo escenario, observará los roles de los contribuyentes en un grupo privado más grande. Aprenderá cómo trabajar en un entorno en el que los grupos pequeños colaboran en las funciones y luego esas contribuciones en equipo estarán integradas por otra parte.
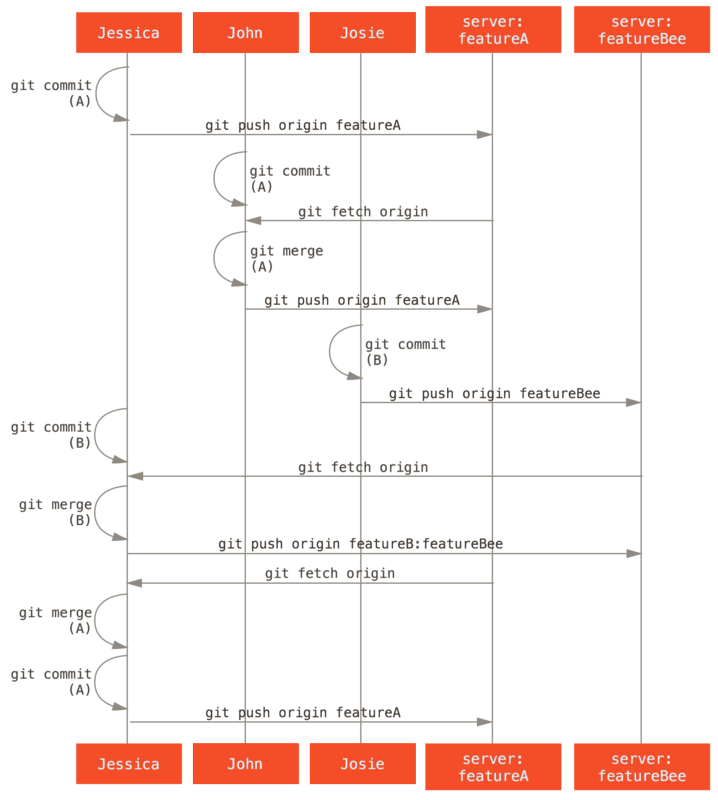
Digamos que John y Jessica están trabajando juntos en una característica, mientras que Jessica y Josie están trabajando en una segunda.
En este caso, la compañía está utilizando un tipo de flujo de trabajo de integración-gerente donde el trabajo de los grupos individuales está integrado sólo por ciertos ingenieros, y la rama maestra del repositorio principal sólo puede ser actualizada por esos ingenieros.
En este escenario, todo el trabajo se realiza en ramas basadas en equipos y luego los integradores lo agrupan.
Sigamos el flujo de trabajo de Jessica mientras trabaja en sus dos funciones, colaborando en paralelo con dos desarrolladores diferentes en este entorno.
Suponiendo que ya haya clonado su repositorio, ella decide trabajar primero en featureA.
Ella crea una nueva rama para la característica y hace algo de trabajo allí:
# Jessica's Machine
$ git checkout -b featureA
Switched to a new branch 'featureA'
$ vim lib/simplegit.rb
$ git commit -am 'add limit to log function'
[featureA 3300904] add limit to log function
1 files changed, 1 insertions(+), 1 deletions(-)En este punto, ella necesita compartir su trabajo con John, por lo que empuja a su rama featureA a comprometerse con el servidor.
Jessica no tiene acceso de inserción a la rama maestra, solo los integradores lo hacen, por lo que debe enviar a otra rama para colaborar con John:
$ git push -u origin featureA
...
To jessica@githost:simplegit.git
* [new branch] featureA -> featureAJessica le envía un correo electrónico a John para decirle que ha enviado algo de trabajo a una rama llamada featureA y ahora puede verlo.
Mientras espera los comentarios de John, Jessica decide comenzar a trabajar en featureB con Josie.
Para comenzar, inicia una nueva rama de características, basándose en la rama master del servidor:
# Jessica's Machine
$ git fetch origin
$ git checkout -b featureB origin/master
Switched to a new branch 'featureB'Ahora, Jessica hace un par de commits en la rama featureB:
$ vim lib/simplegit.rb
$ git commit -am 'made the ls-tree function recursive'
[featureB e5b0fdc] made the ls-tree function recursive
1 files changed, 1 insertions(+), 1 deletions(-)
$ vim lib/simplegit.rb
$ git commit -am 'add ls-files'
[featureB 8512791] add ls-files
1 files changed, 5 insertions(+), 0 deletions(-)El repositorio de Jessica se ve así:
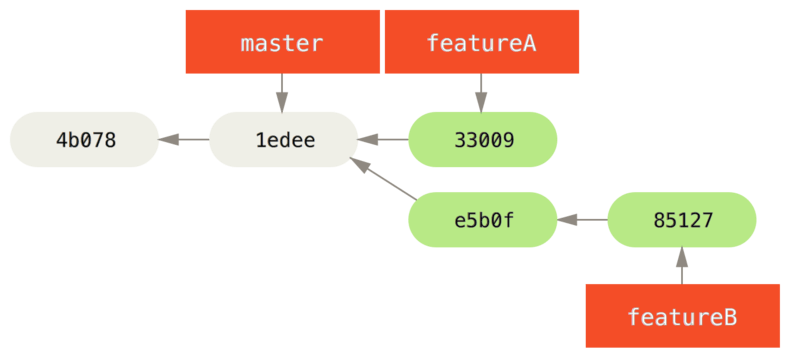
Está lista para impulsar su trabajo, pero recibe un correo electrónico de Josie que indica que una rama con algunos trabajos iniciales ya fue enviada al servidor como featureBee.
Jessica primero necesita fusionar esos cambios con los suyos antes de poder presionar al servidor.
Luego puede buscar los cambios de Josie con git fetch:
$ git fetch origin
...
From jessica@githost:simplegit
* [new branch] featureBee -> origin/featureBeeJessica ahora puede fusionar esto en el trabajo que hizo con git merge:
$ git merge origin/featureBee
Auto-merging lib/simplegit.rb
Merge made by recursive.
lib/simplegit.rb | 4 ++++
1 files changed, 4 insertions(+), 0 deletions(-)Existe un pequeño problema: necesita insertar el trabajo combinado su rama featureB con la rama` featureBee` del servidor.
Ella puede hacerlo especificando la rama local seguida de dos puntos (:) seguido de la rama remota al comando git push:
$ git push -u origin featureB:featureBee
...
To jessica@githost:simplegit.git
fba9af8..cd685d1 featureB -> featureBeeEsto se llama refspec.
Ver << _ refspec >> para una discusión más detallada de las referencias de Git y diferentes cosas que puedes hacer con ellas.
También observe la bandera -u; esto es la abreviatura de --set-upstream, que configura las ramas para empujar y tirar más fácilmente en el futuro.
Luego, John envía un correo electrónico a Jessica para decirle que ha enviado algunos cambios a la rama featureA y le pide que los verifique.
Ella ejecuta un git fetch para bajar esos cambios:
$ git fetch origin
...
From jessica@githost:simplegit
3300904..aad881d featureA -> origin/featureALuego, ella puede ver qué se ha cambiado con git log:
$ git log featureA..origin/featureA
commit aad881d154acdaeb2b6b18ea0e827ed8a6d671e6
Author: John Smith <jsmith@example.com>
Date: Fri May 29 19:57:33 2009 -0700
changed log output to 30 from 25Finalmente, fusiona el trabajo de John en su propia rama featureA:
$ git checkout featureA
Switched to branch 'featureA'
$ git merge origin/featureA
Updating 3300904..aad881d
Fast forward
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)Jessica quiere modificar algo, por lo que se compromete de nuevo y luego lo envía de vuelta al servidor:
$ git commit -am 'small tweak'
[featureA 774b3ed] small tweak
1 files changed, 1 insertions(+), 1 deletions(-)
$ git push
...
To jessica@githost:simplegit.git
3300904..774b3ed featureA -> featureAEl historial de compromiso de Jessica ahora se ve así:
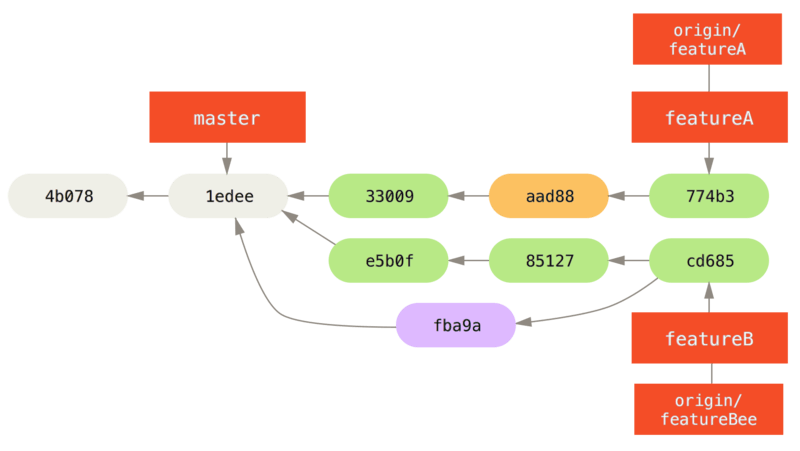
Jessica, Josie y John informan a los integradores que las ramas featureA y` featureBee` en el servidor están listas para su integración en la línea principal.
Después de que los integradores fusionen estas ramas en la línea principal, una búsqueda reducirá la nueva confirmación de fusión, haciendo que el historial se vea así:
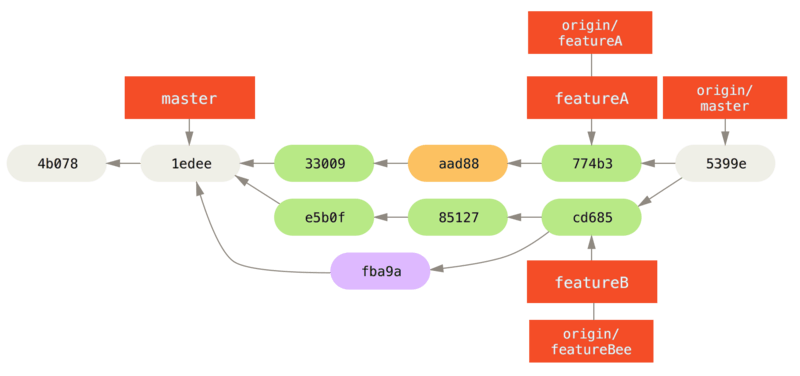
Muchos grupos cambian a Git debido a esta capacidad de tener varios equipos trabajando en paralelo, fusionando las diferentes líneas de trabajo al final del proceso. La capacidad de los subgrupos más pequeños de un equipo para colaborar a través de ramas remotas, sin necesariamente tener que involucrar o impedir a todo el equipo, es un gran beneficio de Git. La secuencia del flujo de trabajo que vió aquí es algo como esto:
Proyecto público bifurcado
Contribuir a proyectos públicos es un poco diferente. Como no tiene los permisos para actualizar directamente las ramas en el proyecto, debe obtener el trabajo de otra manera. Este primer ejemplo describe la contribución mediante bifurcación en hosts Git que admiten bifurcación fácil. Muchos sitios de alojamiento admiten esto (incluidos GitHub, BitBucket, Google Code, repo.or.cz entre otros), y muchos mantenedores de proyectos esperan este estilo de contribución. La siguiente sección trata de proyectos que prefieren aceptar parches contribuidos por correo electrónico.
En primer lugar, es probable que desee clonar el repositorio principal, crear una rama de tema para el parche o la serie de parches en que planea contribuir y hacer su trabajo allí. La secuencia se ve básicamente así:
$ git clone (url)
$ cd project
$ git checkout -b featureA
# (work)
$ git commit
# (work)
$ git commit|
Nota
|
Puede usar |
Cuando finalice el trabajo en la rama y esté listo para contribuir con los mantenedores, vaya a la página original del proyecto y haga clic en el botón ‘` Tenedor '’, creando su propio tenedor escribible del proyecto.
Luego debe agregar esta nueva URL de repositorio como segundo control remoto, en este caso llamado myfork:
$ git remote add myfork (url)Entonces necesitas impulsar tu trabajo hasta esa nua URL. Es más fácil impulsar la rama de tema en la que está trabajando hasta su repositorio, en lugar de fusionarse con su rama principal y aumentarla. La razón es que si el trabajo no se acepta o se selecciona con una cereza, no es necesario rebobinar la rama maestra. Si los mantenedores se fusionan, redimensionan o seleccionan su trabajo, eventualmente lo recuperará a través de su repositorio de todas maneras:
$ git push -u myfork featureA
Cuando su trabajo ha sido empujado hacia su tenedor, debe notificar al mantenedor.
Esto a menudo se denomina solicitud de extracción, y puede generarlo a través del sitio web: GitHub tiene su propio mecanismo de solicitud de extracción que veremos en << _ github >> o puede ejecutar el comando git request-pull y envíar por correo electrónico la salida al mantenedor del proyecto de forma manual.
El comando request-pull toma la rama base en la que desea que se saque su rama de tema y la URL del repositorio de Git de la que desea que extraigan, y genera un resumen de todos los cambios que está solicitando.
Por ejemplo, si Jessica quiere enviar a John una solicitud de extracción, y ella ha hecho dos commits en la rama de temas que acaba de subir, puede ejecutar esto:
$ git request-pull origin/master myfork
The following changes since commit 1edee6b1d61823a2de3b09c160d7080b8d1b3a40:
John Smith (1):
added a new function
are available in the git repository at:
git://githost/simplegit.git featureA
Jessica Smith (2):
add limit to log function
change log output to 30 from 25
lib/simplegit.rb | 10 +++++++++-
1 files changed, 9 insertions(+), 1 deletions(-)La salida se puede enviar al mantenedor, le dice de dónde se ramificó el trabajo, resume los compromisos y dice de dónde sacar este trabajo.
En un proyecto para el cual no eres el mantenedor, generalmente es más fácil tener una rama como master siempre rastreando` origin / master` y hacer tu trabajo en ramas de tema que puedes descartar fácilmente si son rechazadas.
Tener temas de trabajo aislados en las ramas temáticas también facilita la tarea de volver a establecer una base de trabajo si la punta del repositorio principal se ha movido mientras tanto y sus confirmaciones ya no se aplican limpiamente.
Por ejemplo, si desea enviar un segundo tema de trabajo al proyecto, no continúe trabajando en la rama de tema que acaba de crear: vuelva a comenzar desde la rama master del repositorio principal:
$ git checkout -b featureB origin/master
# (work)
$ git commit
$ git push myfork featureB
# (email maintainer)
$ git fetch originAhora, cada uno de sus temas está contenido dentro de un silo, similar a una fila de parches, que puede volver a escribir, volver a establecer y modificar sin que los temas interfieran o se interrelacionen entre sí, de la siguiente manera:
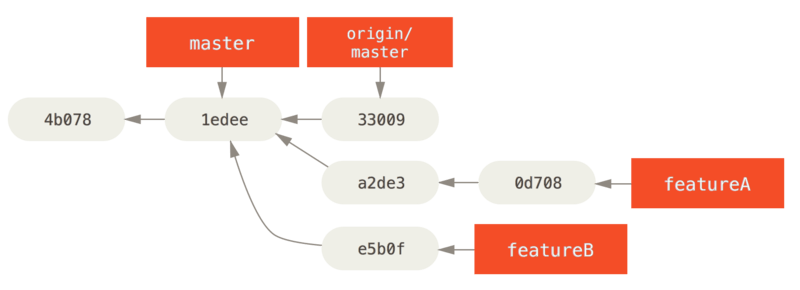
featureB work.Digamos que el mantenedor del proyecto ha sacado otros parches y ha probado su primera rama, pero ya no se fusiona de manera limpia. En este caso, puede tratar de volver a establecer la base de esa rama sobre origin / master, resolver los conflictos del mantenedor y luego volver a enviar los cambios:
$ git checkout featureA
$ git rebase origin/master
$ git push -f myfork featureAEsto reescribe tu historial para que ahora parezca << psp_b >>.
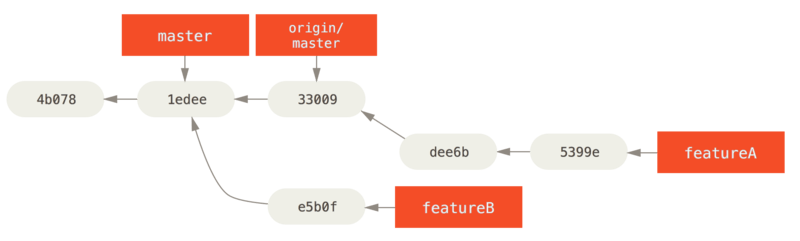
featureA work.Debido a que rebasaste la rama, debes especificar el -f en tu comando push para poder reemplazar la rama` featureA` en el servidor con una confirmación que no sea un descendiente de ella.
Una alternativa sería llevar este nuevo trabajo a una rama diferente en el servidor (tal vez llamada featureAv2).
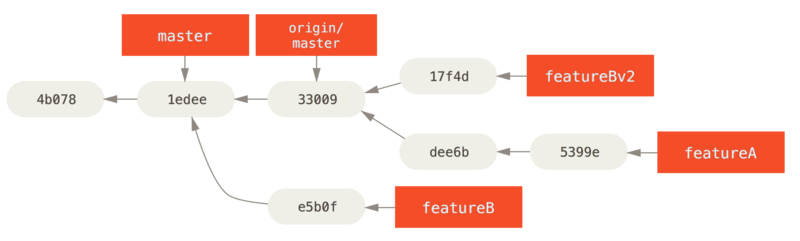
Veamos un escenario más posible: el mantenedor ha observado el trabajo en su segunda rama y le gusta el concepto, pero le gustaría que cambie un detalle de implementación.
También aprovechará esta oportunidad para mover el trabajo basado en la rama maestra 'actual del proyecto.
Usted inicia una nueva rama basada en la rama actual de 'origen / maestro', aplasta los cambios `featureB allí, resuelve cualquier conflicto, hace que la implementación cambie, y luego lo empuja hacia arriba como una nueva rama:
$ git checkout -b featureBv2 origin/master
$ git merge --no-commit --squash featureB
# (change implementation)
$ git commit
$ git push myfork featureBv2La opción --squash toma todo el trabajo en la rama fusionada y lo aplasta en una confirmación sin fusión en la parte superior de la rama en la que se encuentra.
La opción --no-commit le dice a Git que no registre automáticamente una confirmación.
Esto le permite introducir todos los cambios desde otra rama y luego realizar más cambios antes de registrar la nueva confirmación.
Ahora puede enviar al mantenedor un mensaje de que ha realizado los cambios solicitados y puede encontrar esos cambios en su rama featureBv2.
featureBv2 work.Proyecto público a través de correo electrónico
Muchos proyectos han establecido procedimientos para aceptar parches: deberá verificar las reglas específicas para cada proyecto, ya que serán diferentes. Dado que hay varios proyectos antiguos y más grandes que aceptan parches a través de una lista de correo electrónico para desarrolladores, veremos un ejemplo de eso ahora.
El flujo de trabajo es similar al caso de uso anterior: crea ramas de tema para cada serie de parches en las que trabaja. La diferencia es cómo los envía al proyecto. En lugar de bifurcar el proyecto y avanzar hacia su propia versión de escritura, genera versiones de correo electrónico de cada serie de commit y las envía por correo electrónico a la lista de correo de desarrolladores:
$ git checkout -b topicA
# (work)
$ git commit
# (work)
$ git commit
Ahora tiene dos confirmaciones que desea enviar a la lista de correo.
Utiliza git format-patch para generar los archivos con formato mbox que puedes enviar por correo electrónico a la lista: convierte cada confirmación en un mensaje de correo electrónico con la primera línea del mensaje de confirmación como tema y el resto de el mensaje más el parche que introduce el compromiso como el cuerpo.
Lo bueno de esto es que la aplicación de un parche de un correo electrónico generado con format-patch conserva toda la información de compromiso correctamente.
$ git format-patch -M origin/master
0001-add-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patchEl comando format-patch imprime los nombres de los archivos de parche que crea.
El modificador -M le dice a Git que busque cambios de nombre.
Los archivos terminan pareciéndose a esto:
$ cat 0001-add-limit-to-log-function.patch
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20
---
lib/simplegit.rb | 2 +-
1 files changed, 1 insertions(+), 1 deletions(-)
diff --git a/lib/simplegit.rb b/lib/simplegit.rb
index 76f47bc..f9815f1 100644
--- a/lib/simplegit.rb
+++ b/lib/simplegit.rb
@@ -14,7 +14,7 @@ class SimpleGit
end
def log(treeish = 'master')
- command("git log #{treeish}")
+ command("git log -n 20 #{treeish}")
end
def ls_tree(treeish = 'master')
--
2.1.0También puede editar estos archivos de parche para agregar más información para la lista de correo electrónico que no desea mostrar en el mensaje de confirmación.
Si agrega texto entre la línea --- y el comienzo del parche (la línea diff - git), los desarrolladores pueden leerlo; pero aplicar el parche lo excluye.
Para enviarlo por correo electrónico a una lista de correo, puede pegar el archivo en su programa de correo electrónico o enviarlo a través de un programa de línea de comandos.
Pegar el texto a menudo causa problemas de formateo, especialmente con clientes ‘` más inteligentes '’ que no conservan líneas nuevas y otros espacios en blanco de manera apropiada.
Afortunadamente, Git proporciona una herramienta para ayudarlo a enviar parches con formato correcto a través de IMAP, que puede ser más fácil para usted.
Demostraremos cómo enviar un parche a través de Gmail, que es el agente de correo electrónico que mejor conocemos; puede leer instrucciones detalladas para una cantidad de programas de correo al final del archivo Documentation / SubmittingPatches antes mencionado en el código fuente de Git.
Primero, necesitas configurar la sección imap en tu archivo ~ / .gitconfig.
Puede establecer cada valor por separado con una serie de comandos git config, o puede agregarlos manualmente, pero al final su archivo de configuración debería verse más o menos así:
[imap]
folder = "[Gmail]/Drafts"
host = imaps://imap.gmail.com
user = user@gmail.com
pass = p4ssw0rd
port = 993
sslverify = falseSi su servidor IMAP no usa SSL, las dos últimas líneas probablemente no sean necesarias, y el valor del host será imap: // en lugar de imaps: //.
Cuando esté configurado, puede usar git send-email para colocar la serie de parches en la carpeta Borradores del servidor IMAP especificado:
$ git send-email *.patch
0001-added-limit-to-log-function.patch
0002-changed-log-output-to-30-from-25.patch
Who should the emails appear to be from? [Jessica Smith <jessica@example.com>]
Emails will be sent from: Jessica Smith <jessica@example.com>
Who should the emails be sent to? jessica@example.com
Message-ID to be used as In-Reply-To for the first email? yEntonces, Git escupe un montón de información de registro que se ve algo así para cada parche que está enviando:
(mbox) Adding cc: Jessica Smith <jessica@example.com> from
\line 'From: Jessica Smith <jessica@example.com>'
OK. Log says:
Sendmail: /usr/sbin/sendmail -i jessica@example.com
From: Jessica Smith <jessica@example.com>
To: jessica@example.com
Subject: [PATCH 1/2] added limit to log function
Date: Sat, 30 May 2009 13:29:15 -0700
Message-Id: <1243715356-61726-1-git-send-email-jessica@example.com>
X-Mailer: git-send-email 1.6.2.rc1.20.g8c5b.dirty
In-Reply-To: <y>
References: <y>
Result: OKEn este punto, debe poder ir a la carpeta Borradores, cambiar el campo “A”(To) a la lista de correo a la que le envía el parche, posiblemente CC al responsable de esa sección y enviarlo.
Resumen
Esta sección ha cubierto una cantidad de flujos de trabajo comunes para tratar con varios tipos muy diferentes de proyectos de Git que probablemente encuentre, e introdujo algunas herramientas nuevas para ayudarlo a administrar este proceso. A continuación, verá cómo trabajar la otra cara de la moneda: mantener un proyecto de Git. Aprenderá cómo ser un dictador benevolente o un gerente de integración.