
-
1. Inicio - Sobre el Control de Versiones
-
2. Fundamentos de Git
-
3. Ramificaciones en Git
-
4. Git en el Servidor
- 4.1 Los Protocolos
- 4.2 Configurando Git en un servidor
- 4.3 Generando tu clave pública SSH
- 4.4 Configurando el servidor
- 4.5 El demonio Git
- 4.6 HTTP Inteligente
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Git en un alojamiento externo
- 4.10 Resumen
-
5. Git en entornos distribuidos
-
6. GitHub
-
7. Herramientas de Git
- 7.1 Revisión por selección
- 7.2 Organización interactiva
- 7.3 Guardado rápido y Limpieza
- 7.4 Firmando tu trabajo
- 7.5 Buscando
- 7.6 Reescribiendo la Historia
- 7.7 Reiniciar Desmitificado
- 7.8 Fusión Avanzada
- 7.9 Rerere
- 7.10 Haciendo debug con Git
- 7.11 Submódulos
- 7.12 Agrupaciones
- 7.13 Replace
- 7.14 Almacenamiento de credenciales
- 7.15 Resumen
-
8. Personalización de Git
-
9. Git y Otros Sistemas
- 9.1 Git como Cliente
- 9.2 Migración a Git
- 9.3 Resumen
-
10. Los entresijos internos de Git
-
A1. Apéndice A: Git en otros entornos
- A1.1 Interfaces gráficas
- A1.2 Git en Visual Studio
- A1.3 Git en Eclipse
- A1.4 Git con Bash
- A1.5 Git en Zsh
- A1.6 Git en Powershell
- A1.7 Resumen
-
A2. Apéndice B: Integrando Git en tus Aplicaciones
- A2.1 Git mediante Línea de Comandos
- A2.2 Libgit2
- A2.3 JGit
-
A3. Apéndice C: Comandos de Git
- A3.1 Configuración
- A3.2 Obtener y Crear Proyectos
- A3.3 Seguimiento Básico
- A3.4 Ramificar y Fusionar
- A3.5 Compartir y Actualizar Proyectos
- A3.6 Inspección y Comparación
- A3.7 Depuración
- A3.8 Parcheo
- A3.9 Correo Electrónico
- A3.10 Sistemas Externos
- A3.11 Administración
- A3.12 Comandos de Fontanería
5.3 Git en entornos distribuidos - Manteniendo un proyecto
Manteniendo un proyecto
Además de saber cómo contribuir de manera efectiva a un proyecto, probablemente necesitarás saber cómo mantenerlo.
Esto puede comprender desde aceptar y aplicar parches generados vía format-patch enviados por e-mail, hasta integrar cambios en ramas remotas para repositorios que has añadido como remotos a tu proyecto.
Tanto si mantienes un repositorio canónico como si quieres ayudar verificando o aprobando parches, necesitas conocer cómo aceptar trabajo de otros colaboradores de la forma más clara y sostenible posible a largo plazo.
Trabajando en ramas puntuales
Cuando estás pensando en integrar nuevo trabajo, generalmente es una buena idea probarlo en una rama puntual (topic branch) - una rama temporal específicamente creada para probar ese nuevo trabajo.
De esta forma, es fácil ajustar un parche individualmente y abandonarlo si no funciona hasta que tengas tiempo de retomarlo.
Si creas una rama simple con un nombre relacionado con el trabajo que vas a probar, como ruby_client o algo igualmente descriptivo, puedes recordarlo fácilmente si tienes que abandonarlo y retomarlo posteriormente.
El responsable del mantenimiento del proyecto Git también tiende a usar una nomenclatura con este formato – como sc/ruby_client, donde sc es la abreviatura de la persona que envió el trabajo.
Como recordarás, puedes crear la rama a partir de la rama master de la siguiente forma:
$ git branch sc/ruby_client masterO, si quieres cambiar inmediatamente a la nueva rama, puedes usar la opción checkout -b:
$ git checkout -b sc/ruby_client masterAhora estás listo para añadir el trabajo recibido en esta rama puntual y decidir si quieres incorporarlo en tus ramas de largo recorrido.
Aplicando parches recibidos por e-mail
Si recibes por e-mail un parche que necesitas integrar en tu proyecto, deberías aplicarlo en tu rama puntual para evaluarlo.
Hay dos formas de aplicar un parche enviado por e-mail: con git apply o git am.
Aplicando un parche con apply
Si recibiste el parche de alguien que lo generó con git diff o con el comando Unix diff (lo cual no se recomienda; consulta la siguiente sección), puedes aplicarlo con el comando git apply.
Suponiendo que guardaste el parche en /tmp/patch-ruby-client.patch, puedes aplicarlo de esta forma:
$ git apply /tmp/patch-ruby-client.patchEsto modifica los archivos en tu directorio de trabajo.
Es casi idéntico a ejecutar un comando patch -p1 para aplicar el parche, aunque es más paranoico y acepta menos coincidencias aproximadas que patch.
También puede manejar archivos nuevos, borrados y renombrados si están descritos en formato git diff mientras que patch no puede hacerlo.
Por último, git apply sigue un modelo “aplica todo o aborta todo”, donde se aplica todo o nada, mientras que patch puede aplicar parches parcialemente, dejando tu directorio de trabajo en un estado inconsistente.
git apply es en general mucho más conservador que patch.
No creará un commit por ti – tras ejecutarlo, debes preparar (stage) y confirmar (commit) manualmente los cambios introducidos.
También puedes usar git apply para comprobar si un parche se aplica de forma limpia antes de aplicarlo realmente – puedes ejecutar git apply --check indicando el parche:
$ git apply --check 0001-seeing-if-this-helps-the-gem.patch
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not applySi no obtienes salida, entonces el parche debería aplicarse limpiamente. Este comando también devuelve un estado distinto de cero si la comprobación falla, por lo que puedes usarlo en scripts.
Aplicando un parche con am
Si el colaborador es usuario de Git y conoce lo suficiente como para usar el comando format-patch para generar el parche, entonces tu trabajo es más sencillo, puesto que el parche ya contiene información del autor y un mensaje de commit.
Si puedes, anima a tus colaboradores a usar format-patch en lugar de diff para generar parches.
Sólo deberías usar git apply para parches antiguos y cosas similares.
Para aplicar un parche generado con format-patch, usa git am.
Técnicamente, git am se construyó para leer de un archivo mbox (buzón de correo). Es un formato de texto plano simple para almacenar uno o más mensajes de correo en un archivo de texto.
Es algo parecido a esto:
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20Esto es el comienzo de la salida del comando format-patch que viste en la sección anterior.
También es un formato mbox válido.
Si alguien te ha enviado el parche por e-mail usando git send-email y lo has descargado en formato mbox, entonces puedes pasar ese archivo a git am y comenzará a aplicar todos los parches que encuentre.
Si usas un cliente de correo que puede guardar varios e-mails en formato mbox, podrías guardar conjuntos completos de parches en un único archivo y a continuación usar git am para aplicarlos de uno en uno.
Sin embargo, si alguien subió a un sistema de gestión de incidencias o algo parecido un parche generado con format-patch, podrías guardar localmente el archivo y posteriormente pasarlo a git am para aplicarlo:
$ git am 0001-limit-log-function.patch
Applying: add limit to log functionPuedes ver que aplicó el parche limpiamente y creó automáticamente un nuevo commit.
La información del autor se toma de las cabeceras From y Date del e-mail, y el mensaje del commit sale del Subject y el cuerpo del e-mail (antes del parche).
Por ejemplo, si se aplicó este parche desde el archivo mbox del ejemplo anterior, el commit generado sería algo como esto:
$ git log --pretty=fuller -1 commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0 Author: Jessica Smith <jessica@example.com> AuthorDate: Sun Apr 6 10:17:23 2008 -0700 Commit: Scott Chacon <schacon@gmail.com> CommitDate: Thu Apr 9 09:19:06 2009 -0700 add limit to log function Limit log functionality to the first 20
El campo Commit indica la persona que aplicó el parche y cuándo lo aplicó.
El campo Author es la persona que creó originalmente el parche y cuándo fué creado.
Pero es posible que el parche no se aplique limpiamente.
Quizás tu rama principal es muy diferente de la rama a partir de la cual se creó el parche, o el parche depende de otro parche que aún no has aplicado.
En ese caso, el proceso git am fallará y te preguntará qué hacer:
$ git am 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Patch failed at 0001.
When you have resolved this problem run "git am --resolved".
If you would prefer to skip this patch, instead run "git am --skip".
To restore the original branch and stop patching run "git am --abort".Este comando marca los conflictos en cualquier archivo para el cual detecte problemas, como si fuera una operación merge o rebase.
Estos problemas se solucionan de la misma forma - edita el archivo para resolver el conflicto, prepara (stage) el nuevo archivo y por último ejecuta git am --resolved para continuar con el siguiente parche:
$ (fix the file)
$ git add ticgit.gemspec
$ git am --resolved
Applying: seeing if this helps the gemSi quieres que Git intente resolver el conflicto de forma un poco más inteligente, puedes indicar la opción -3 para que Git intente hacer un merge a tres bandas.
Esta opción no está activa por defecto, ya que no funciona si el commit en que el parche está basado no está en tu repositorio.
Si tienes ese commit – si el parche partió de un commit público – entonces la opción -3 es normalmente mucho más inteligente a la hora de aplicar un parche conflictivo:
$ git am -3 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
No changes -- Patch already applied.En este caso, el parche ya ha sido aplicado.
Sin la opción -3, aparecería un conflicto.
Si estás aplicando varios parches a partir de un archivo mbox, también puedes ejecutar el comando am en modo interactivo, el cual se detiene en cada parche para preguntar si quieres aplicarlo:
$ git am -3 -i mbox
Commit Body is:
--------------------------
seeing if this helps the gem
--------------------------
Apply? [y]es/[n]o/[e]dit/[v]iew patch/[a]ccept allEsto está bien si tienes guardados varios parches, ya que puedes revisar el parche previamente y no aplicarlo si ya lo has hecho.
Una vez aplicados y confirmados todos los parches de tu rama puntual, puedes decidir cómo y cuándo integrarlos en una rama de largo recorrido.
Recuperando ramas remotas
Si recibes una contribución de un usuario de Git que configuró su propio repositorio, realizó cambios en él y envió la URL del repositorio junto con el nombre de la rama remota donde están los cambios, puedes añadirlo como una rama remota y hacer integraciones (merges) de forma local.
Por ejemplo, si Jessica te envía un e-mail diciendo que tiene una nueva funcionalidad muy interesante en la rama ruby-client de su repositorio, puedes probarla añadiendo el repositorio remoto y recuperando localmente dicha rama:
$ git remote add jessica git://github.com/jessica/myproject.git
$ git fetch jessica
$ git checkout -b rubyclient jessica/ruby-clientSi más tarde te envía otro e-mail con una nueva funcionalidad en otra rama, puedes recuperarla (fetch y check out) directamente porque ya tienes el repositorio remoto configurado.
Esto es más útil cuando trabajas regularmente con una persona. Sin embargo, si alguien sólo envía un parche de forma ocasional, aceptarlo vía e-mail podría llevar menos tiempo que obligar a todo el mundo a ejecutar su propio servidor y tener que añadir y eliminar repositorios remotos continuamente para obtener unos cuantos parches. Además, probablemente no quieras tener cientos de repositorios remotos, uno por cada persona que envía uno o dos parches. En cualquier caso, los scripts y los servicios alojados pueden facilitar todo esto — depende en gran medida de cómo desarrollan el trabajo tanto tus colaboradores como tú mismo —
Otra ventaja de esta opción es que además puedes obtener un historial de commits.
Aunque pueden surgir los problemas habituales durante la integración (merge), al menos sabes en qué punto de tu historial se basa su trabajo. Por defecto, se realiza una integración a tres bandas, en lugar de indicar un -3 y esperar que el parche se generará a partir de un commit público al que tengas acceso.
Si no trabajas regularmente con alguien pero aún así quieres obtener sus contribuciones de esta manera, puedes pasar la URL del repositorio remoto al comando git pull.
Esto recupera los cambios de forma puntual (pull) sin guardar la URL como una referencia remota:
$ git pull https://github.com/onetimeguy/project
From https://github.com/onetimeguy/project
* branch HEAD -> FETCH_HEAD
Merge made by recursive.Decidiendo qué introducir
Ahora tienes una rama puntual con trabajo de los colaboradores. En este punto, puedes decidir qué quieres hacer con ella. Esta sección repasa un par de comandos para que puedas ver cómo se usan para revisar exactamente qué se va a introducir si integras los cambios en tu rama principal.
A menudo es muy útil obtener una lista de todos los commits de una rama que no están en tu rama principal.
Puedes excluir de dicha lista los commits de tu rama principal anteponiendo la opción --not al nombre de la rama.
El efecto de esto es el mismo que el formato master..contrib que usamos anteriormente.
Por ejemplo, si un colaborador te envía dos parches y creas una rama llamada contrib para aplicar los parches, puedes ejecutar esto:
$ git log contrib --not master
commit 5b6235bd297351589efc4d73316f0a68d484f118
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Oct 24 09:53:59 2008 -0700
seeing if this helps the gem
commit 7482e0d16d04bea79d0dba8988cc78df655f16a0
Author: Scott Chacon <schacon@gmail.com>
Date: Mon Oct 22 19:38:36 2008 -0700
updated the gemspec to hopefully work betterPara ver qué cambios introduce cada commit, recuerda que puedes indicar la opción -p a git log, y añadirá las diferencias introducidas en cada commit.
Para tener una visión completa de qué ocurriría si integraras esta rama puntual en otra rama, podrías usar un sencillo truco para obtener los resultados correctos. Podrías pensar en ejecutar esto:
$ git diff masterEste comando te da las diferencias, pero los resultados podrían ser confusos.
Si tu rama master ha avanzado desde que creaste la rama puntual, entonces obtendrás resultados aparentemente extraños.
Esto ocurre porque Git compara directamente las instantáneas del último commit de la rama puntual en la que estás con la instantánea del último commit de la rama master.
Por ejemplo, si has añadido una línea a un archivo en la rama master, al hacer una comparación directa de las instantáneas parecerá que la rama puntual va a eliminar esa línea.
Si master es un ancestro de tu rama puntual, esto no supone un problema; pero si los dos historiales divergen, al hacer una comparación directa parecerá que estás añadiendo todos los cambios nuevos en tu rama puntual y eliminándolos de la rama master.
Lo que realmente necesitas ver son los cambios añadidos en tu rama puntual – el trabajo que introducirás si integras esta rama en la master.
Para conseguir esto, Git compara el último commit de tu rama puntual con el primer ancestro en común respecto a la rama master.
Técnicamente puedes hacer esto averiguando explícitamente el ancestro común y ejecutando el diff sobre dicho ancestro:
$ git merge-base contrib master
36c7dba2c95e6bbb78dfa822519ecfec6e1ca649
$ git diff 36c7dbSin embargo, eso no es lo más conveniente, así que Git ofrece un atajo para hacer eso mismo: la sintaxis del triple-punto.
En el contexto del comando diff, puedes poner tres puntos tras el nombre de una rama para hacer un diff entre el último commit de la rama en la que estás y su ancestro común con otra rama:
$ git diff master...contribEste comando sólo muestra el trabajo introducido en tu rama puntual actual desde su ancestro común con la rama master.
Es una sintaxis muy útil a recordar.
Integrando el trabajo de los colaboradores
Cuando todo el trabajo de tu rama puntual está listo para ser integrado en una rama de largo recorrido, la cuestión es cómo hacerlo. Es más, ¿qué flujo de trabajo general quieres seguir para mantener el proyecto? Tienes varias opciones y vamos a ver algunas de ellas.
Integrando flujos de trabajo
Un flujo de trabajo sencillo integra tu trabajo en tu rama master.
En este escenario, tienes una rama master que contiene básicamente código estable.
Cuando tienes trabajo propio en una rama puntual o trabajo aportado por algún colaborador que ya has verificado, lo integras en tu rama master, borras la rama puntual y continúas el proceso.
Si tenemos un repositorio con trabajo en dos ramas llamadas ruby_client y php_client, tal y como se muestra en Historial con varias ramas puntuales. e integramos primero ruby_client y luego php_client, entonces tu historial terminará con este aspecto Tras integrar una rama puntual..
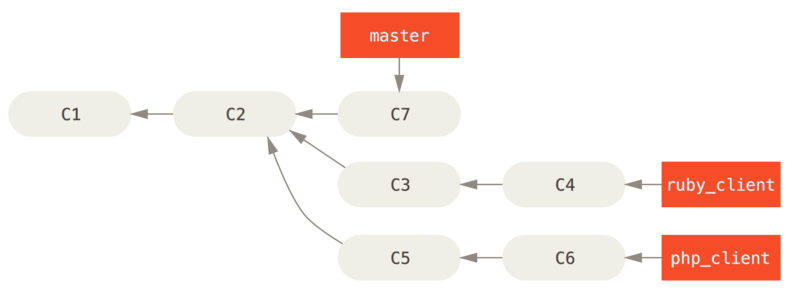
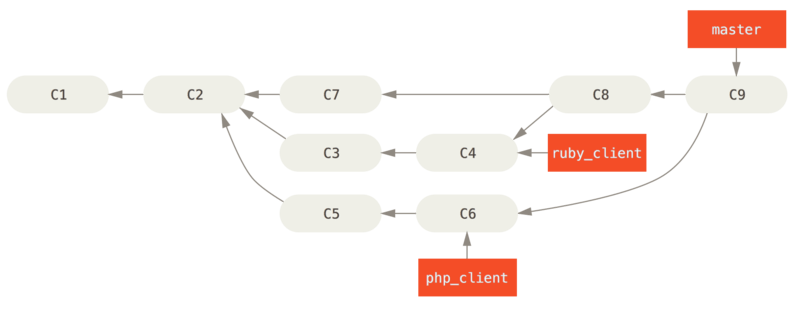
Este es probablemente el flujo de trabajo más simple y puede llegar a causar problemas si estás tratando con proyectos de mayor envergadura o más estables, donde hay que ser realmente cuidadoso al introducir cambios.
Si tienes un proyecto más importante, podrías preferir usar un ciclo de integración en dos fases.
En este escenario, tienes dos ramas de largo recorrido, master y develop, y decides que la rama master sólo se actualiza cuando se llega a una versión muy estable y todo el código nuevo está integrado en la rama develop.
Ambas ramas se envían habitualmente al repositorio público.
Cada vez que tengas una nueva rama puntual para integrar en (Antes de integrar una rama puntual.), primero la fusionas con la rama develop (Tras integrar una rama puntual.); luego, tras etiquetar la versión, avanzas la rama master hasta el punto donde se encuentre la ahora estable rama develop (Tras el lanzamiento de una rama puntual.).
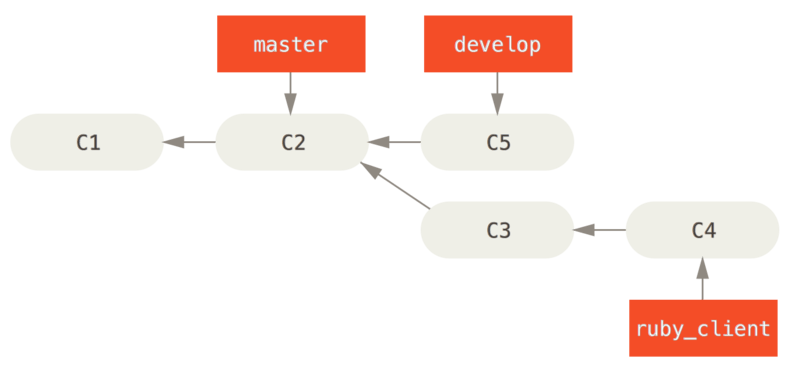
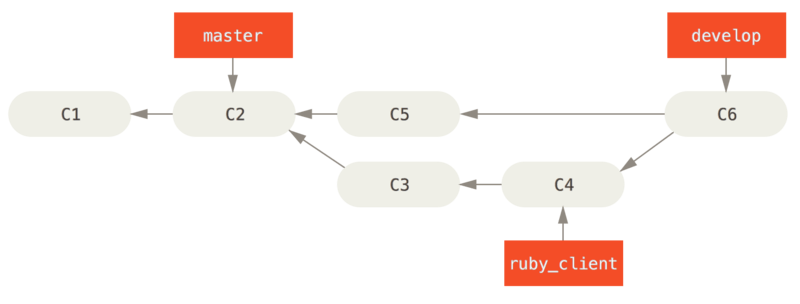
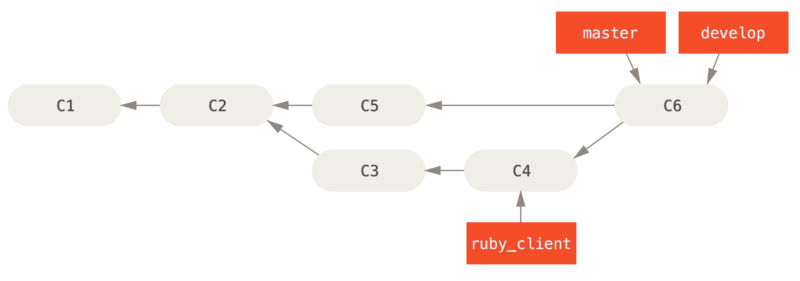
De esta forma, cuando alguien clone el repositorio de tu proyecto, puede recuperar la rama master para construir la última versión estable y mantenerla actualizada fácilmente, o bien puede recuperar la rama develop, que es la que tiene los últimos desarrollos.
Puedes ir un paso más allá y crear una rama de integración integrate, donde integres todo el trabajo.
Entonces, cuando el código de esa rama sea estable y pase las pruebas, lo puedes integrar en una rama de desarrollo; y cuando se demuestre que efectivamente permanece estable durante un tiempo, avanzas la rama master.
Flujos de trabajo con grandes integraciones
El proyecto Git tiene cuatro ramas de largo recorrido: master, next, y pu (proposed updates, actualizaciones propuestas) para trabajos nuevos, y maint para trabajos de mantenimiento de versiones anteriores.
Cuando los colaboradores introducen nuevos trabajos, se recopilan en ramas puntuales en el repositorio del responsable de mantenimiento, de manera similar a la que se ha descrito (ver Gestionando un conjunto complejo de ramas puntuales paralelas.).
En este punto, los nuevos trabajos se evalúan para decidir si son seguros y si están listos para los usuarios o si por el contrario necesitan más trabajo.
Si son seguros, se integran en la rama next, y se envía dicha rama al repositorio público para que todo el mundo pueda probar las nuevas funcionalidades ya integradas.
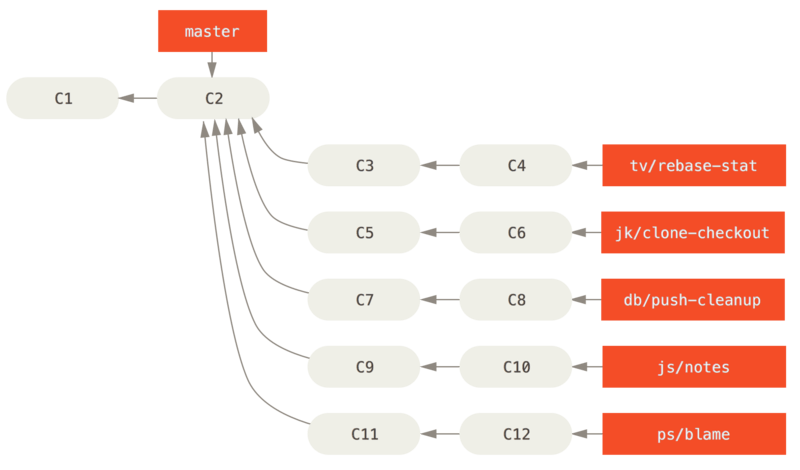
Si las nuevas funcionalidades necesitan más trabajo, se integran en la rama pu.
Cuando se decide que estas funcionalidades son totalmente estables, se integran de nuevo en la rama master, construyéndolas a partir de las funcionalidades en la rama next que aún no habían pasado a la rama master.
Esto significa que la rama master casi siempre avanza, next se reorganiza ocasionalmente y pu se reorganiza mucho más a menudo:
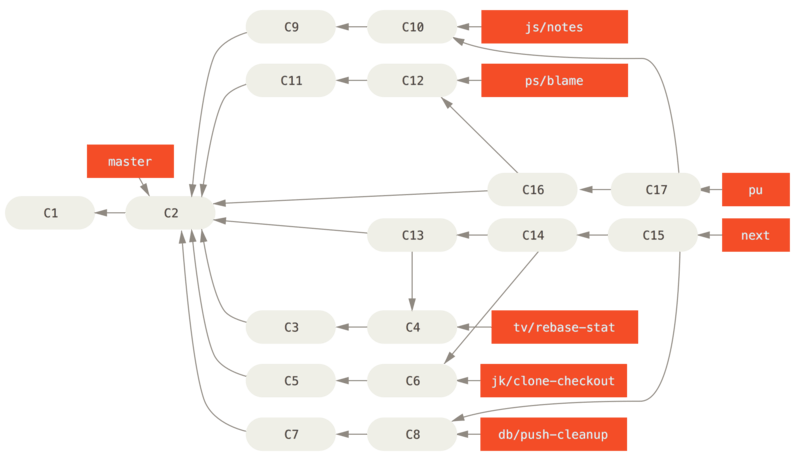
Cuando una rama puntual se ha integrado en la rama master, se elimina del repositorio.
El proyecto Git también tiene una rama maint creada a partir de la última versión para ofrecer parches, en caso de que fuera necesaria una versión de mantenimiento.
Así, cuando clonas el repositorio de Git, tienes cuatro ramas que puedes recuperar para evaluar el proyecto en diferentes etapas de desarrollo, dependiendo de si quieres tener una versión muy avanzada o de cómo quieras contribuir. De esta forma, el responsable de mantenimiento tiene un flujo de trabajo estructurado para ayudarle a aprobar las nuevas contribuciones.
Flujos de trabajo reorganizando o entresacando
Otros responsables de mantenimiento prefieren reorganizar o entresacar el nuevo trabajo en su propia rama master, en lugar de integrarlo, para mantener un historial prácticamente lineal.
Cuando tienes trabajo en una rama puntual y has decidido que quieres integrarlo, te posicionas en esa rama y ejecutas el comando rebase para reconstruir los cambios en tu rama master (o develop, y así sucesivamente).
Si ese proceso funciona bien, puedes avanzar tu rama master, consiguiendo un historial lineal en tu proyecto.
Otra forma de mover trabajo de una rama a otra es entresacarlo (cherry-pick).
En Git, "entresacar" es como hacer un rebase para un único commit.
Toma el parche introducido en un commit e intenta reaplicarlo en la rama en la que estás actualmente.
Esto es útil si tienes varios commits en una rama puntual y sólo quieres integrar uno de ellos, o si sólo tienes un commit en una rama puntual y prefieres entresacarlo en lugar de hacer una reorganización (rebase).
Por ejemplo, imagina que tienes un proyecto como éste:
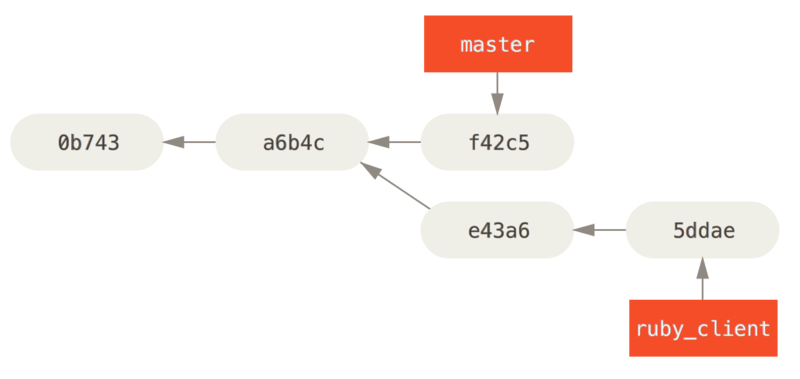
Si sólo deseas integrar el commit e43a6 en tu rama master, puedes ejecutar
$ git cherry-pick e43a6fd3e94888d76779ad79fb568ed180e5fcdf
Finished one cherry-pick.
[master]: created a0a41a9: "More friendly message when locking the index fails."
3 files changed, 17 insertions(+), 3 deletions(-)Esto introduce el mismo cambio introducido en e43a6, pero genera un nuevo valor SHA-1 de confirmación, ya que la fecha en que se ha aplicado es distinta.
Ahora tu historial queda así:
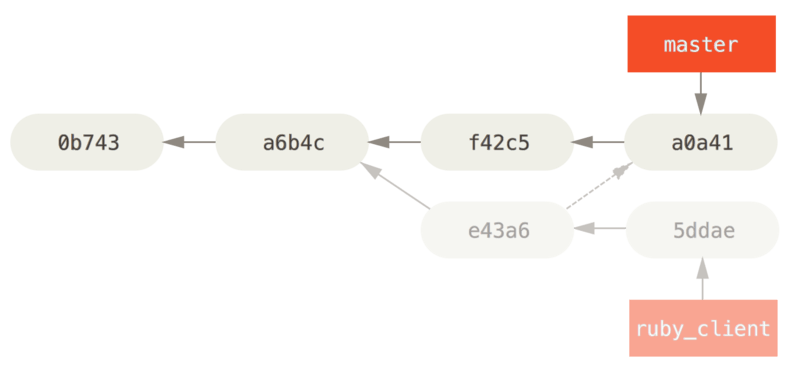
En este momento ya puedes eliminar tu rama puntual y descartar los commits que no quieres integrar.
Rerere
Git dispone de una utilidad llamada “rerere” que puede resultar útil si estás haciendo muchas integraciones y reorganizaciones, o si mantienes una rama puntual de largo recorrido.
Rerere significa “reuse recorded resolution” (reutilizar resolución grabada) – es una forma de simplificar la resolución de conflictos. Cuando “rerere” está activo, Git mantendrá un conjunto de imágenes anteriores y posteriores a las integraciones correctas, de forma que si detecta que hay un conflicto que parece exactamente igual a otro ya corregido previamente, usará esa misma corrección sin causarte molestias.
Esta funcionalidad consta de dos partes: un parámetro de configuración y un comando.
El parámetro de configuración es rerere.enabled y es bastante útil ponerlo en tu configuración global:
$ git config --global rerere.enabled trueAhora, cuando hagas una integración que resuelva conflictos, la resolución se grabará en la caché por si la necesitas en un futuro.
Si fuera necesario, puedes interactuar con la caché de “rerere” usando el comando git rerere.
Cuando se invoca sin ningún parámetro adicional, Git comprueba su base de datos de resoluciones en busca de coincidencias con cualquier conflicto durante la integración actual e intenta resolverlo (aunque se hace automáticamente en caso de que rerere.enabled sea true).
También existen subcomandos para ver qué se grabará, para eliminar de la caché una resolución específica y para limpiar completamante la caché. Veremos más detalles sobre “rerere” en Rerere.
Etiquetando tus versiones
Cuando decides lanzar una versión, probablemente quieras etiquetarla para poder generarla más adelante en cualquier momento. Puedes crear una nueva etiqueta siguiendo los pasos descritos en [ch02-git-basics]. Si decides firmar la etiqueta como responsable de mantenimiento, el etiquetado sería algo así:
$ git tag -s v1.5 -m 'my signed 1.5 tag'
You need a passphrase to unlock the secret key for
user: "Scott Chacon <schacon@gmail.com>"
1024-bit DSA key, ID F721C45A, created 2009-02-09Si firmas tus etiquetas podrías tener problemas a la hora de distribuir la clave PGP pública usada para firmarlas.
El responsable de mantenimiento del proyecto Git ha conseguido solucionar este problema incluyendo su clave pública como un objeto binario en el repositorio, añadiendo a continuación una etiqueta que apunta directamente a dicho contenido.
Para hacer esto, puedes averiguar qué clave necesitas lanzando el comando gpg --list-keys:
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 1024D/F721C45A 2009-02-09 [expires: 2010-02-09]
uid Scott Chacon <schacon@gmail.com>
sub 2048g/45D02282 2009-02-09 [expires: 2010-02-09]Ahora ya puedes importar directamente la clave en la base de datos de Git, exportándola y redirigiéndola a través del comando git hash-object, que escribe en Git un nuevo objeto binario con esos contenidos y devuelve la firma SHA-1 de dicho objeto.
$ gpg -a --export F721C45A | git hash-object -w --stdin
659ef797d181633c87ec71ac3f9ba29fe5775b92Una vez que tienes los contenidos de tu clave en Git, puedes crear una etiqueta que apunte directamente a dicha clave indicando el nuevo valor SHA-1 que devolvió el comando hash-object:
$ git tag -a maintainer-pgp-pub 659ef797d181633c87ec71ac3f9ba29fe5775b92Si ejecutas git push --tags, la etiqueta maintainer-pgp-pub será compartida con todo el mundo.
Si alguien quisiera verificar una etiqueta, puede importar tu clave PGP recuperando directamente el objeto binario de la base de datos e importándolo en GPG:
$ git show maintainer-pgp-pub | gpg --importEsa clave se puede usar para verificar todas tus etiquetas firmadas.
Además, si incluyes instrucciones en el mensaje de la etiqueta, el comando git show <tag> permitirá que el usuario final obtenga instrucciones más específicas sobre el proceso de verificación de etiquetas.
Generando un número de compilación
Como Git no genera una serie de números monótonamente creciente como v123 o similar con cada commit, si quieres tener un nombre más comprensible para un commit, puedes ejecutar el comando git describe sobre dicho commit.
Git devolverá el nombre de la etiqueta más próxima junto con el número de commits sobre esa etiqueta y una parte del valor SHA-1 del commit que estás describiendo:
$ git describe master
v1.6.2-rc1-20-g8c5b85cDe esta forma, puedes exportar una instantánea o generar un nombre comprensible para cualquier persona.
De hecho, si construyes Git a partir del código fuente clonado del repositorio Git, git --version devuelve algo parecido a esto.
Si estás describiendo un commit que has etiquetado directamente, te dará el nombre de la etiqueta.
El comando git describe da preferencia a etiquetas anotadas (etiquetas creadas con las opciones -a o -s), por lo que las etiquetas de versión deberían crearse de esta forma si estás usando git describe, para garantizar que el commit es nombrado adecuadamente cuando se describe.
También puedes usar esta descripción como objetivo de un comando checkout o show, aunque depende de la parte final del valor SHA-1 abreviado, por lo que podría no ser válida para siempre.
Por ejemplo, recientemente el núcleo de Linux pasó de 8 a 10 caracteres para asegurar la unicidad del objeto SHA-1, por lo que los nombres antiguos devueltos por git describe fueron invalidados.
Preparando una versión
Ahora quieres lanzar una versión.
Una cosa que querrás hacer será crear un archivo con la última instantánea del código para esas pobres almas que no usan Git.
El comando para hacerlo es git archive:
$ git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
$ ls *.tar.gz
v1.6.2-rc1-20-g8c5b85c.tar.gzSi alguien abre el archivo tar, obtiene la última instantánea de tu proyecto bajo un directorio project.
También puedes crear un archivo zip de la misma manera, pero añadiendo la opción --format=zip a git archive:
$ git archive master --prefix='project/' --format=zip > `git describe master`.zipAhora tienes tanto un archivo tar como zip con la nueva versión de tu proyecto, listos para subirlos a tu sitio web o para enviarlos por e-mail.
El registro resumido
Es el momento de enviar un mensaje a tu lista de correo informando sobre el estado de tu proyecto.
Una buena opción para obtener rápidamente una especie de lista con los cambios introducidos en tu proyecto desde la última versión o e-mail es usar el comando git shortlog.
Dicho comando resume todos los commits en el rango que se le indique; por ejemplo, el siguiente comando devuelve un resumen de todos los commits desde tu última versión, suponiendo que fuera la v1.0.1:
$ git shortlog --no-merges master --not v1.0.1
Chris Wanstrath (8):
Add support for annotated tags to Grit::Tag
Add packed-refs annotated tag support.
Add Grit::Commit#to_patch
Update version and History.txt
Remove stray `puts`
Make ls_tree ignore nils
Tom Preston-Werner (4):
fix dates in history
dynamic version method
Version bump to 1.0.2
Regenerated gemspec for version 1.0.2Consigues un resumen limpio de todos los commits desde la versión v1.0.1, agrupados por autor, que puedes enviar por correo electrónico a tu lista.