
-
1. Per Iniziare
- 1.1 Il Controllo di Versione
- 1.2 Una Breve Storia di Git
- 1.3 Cos’é Git?
- 1.4 La riga di comando
- 1.5 Installing Git
- 1.6 First-Time Git Setup
- 1.7 Chiedere aiuto
- 1.8 Sommario
-
2. Git Basics
- 2.1 Getting a Git Repository
- 2.2 Recording Changes to the Repository
- 2.3 Viewing the Commit History
- 2.4 Undoing Things
- 2.5 Working with Remotes
- 2.6 Tagging
- 2.7 Git Aliases
- 2.8 Sommario
-
3. Git Branching
- 3.1 Branches in a Nutshell
- 3.2 Basic Branching and Merging
- 3.3 Branch Management
- 3.4 Branching Workflows
- 3.5 Remote Branches
- 3.6 Rebasing
- 3.7 Summary
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
- 5.1 Distributed Workflows
- 5.2 Contributing to a Project
- 5.3 Maintaining a Project
- 5.4 Summary
-
6. GitHub
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Git Internals
- 10.1 Plumbing and Porcelain
- 10.2 Git Objects
- 10.3 Git References
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Environment Variables
- 10.9 Summary
-
A1. Appendice A: Git in altri contesti
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Riassunto
-
A2. Appendice B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendice C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
3.6 Git Branching - Rebasing
Rebasing
In git, ci sono due metodi principali per integrare i cambiamenti di un branch in un altro: il merge e il rebase.
In questa sezione imparerai cos’è il rebasing, come farlo, perché è uno strumento così formidabile, e in quali casi non vorrai usarlo.
Il Rebase semplice
Se torni al precedente esempio Basic Merging, puoi notare che il tuo lavoro diverge e sono stati fatti dei commit in entrambi i branch.
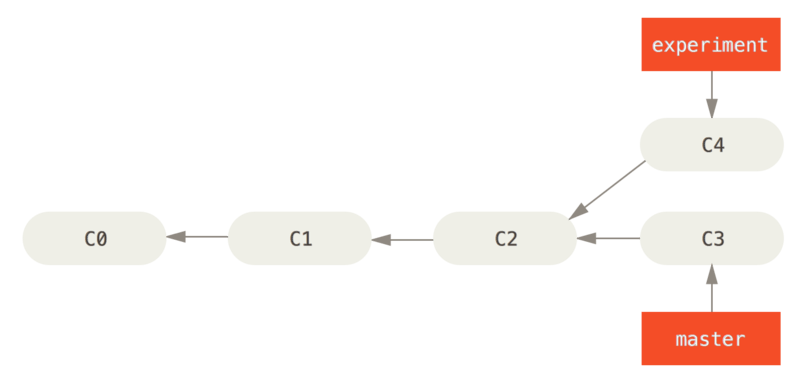
Il modo più semplice di integrare dei branch, come abbiamo già discusso, il comando merge.
Esso esegue l’unione a tre vie fra gli ultimi due branch snapshot (C3 e C4) e il più recente predecessore comune dei due (C2), creando un nuovo snapshot (e commit).
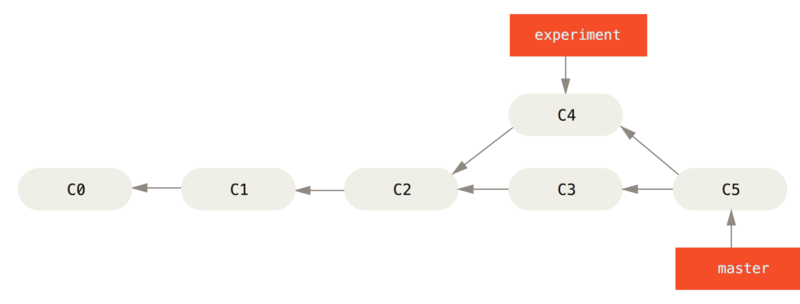
Ma c’è un altro modo: puoi prendere le modifiche introdotte in C4 e riapplicarle in cima a C3.
In Git, questo è chiamato rebasing.
Con il comando rebase, puoi prendere tutti i commit di un branch e replicarli su un altro.
Consideriamo il seguente esempio:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged commandFunziona andando all’antenato comune dei due rami (quello su cui ti trovi e quello su cui stai ribasando), ottenendo le differenze introdotte da ogni commit del branch in cui ti trovi, salvando le differenze in file temporanei, reimpostando il branch corrente sullo stesso commit del branch su cui stai ribasando e infine applicando ogni modifica una alla volta.
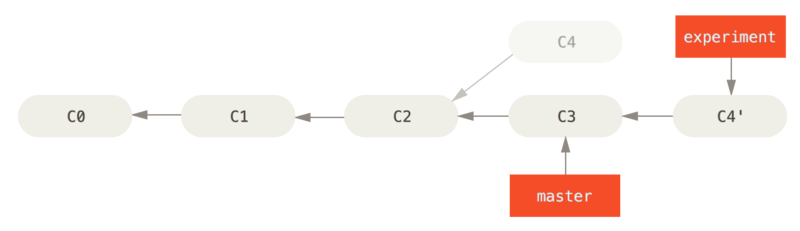
C4 su C3
A questo punto, puoi tornare sul branch master ed eseguire un merge fast-forward.
$ git checkout master
$ git merge experiment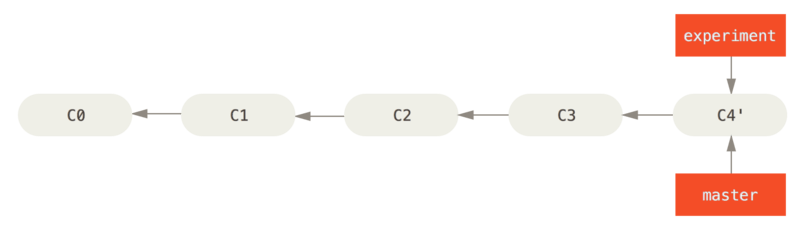
Adesso, lo snapshot punta a C4' esattamente come nell’esempio del merge si puntava a C5.
Non c’è differenza nel prodotto del’integrazione, ma il rebase crea uno storico più chiaro.
Se esamini il log del branch ribasato, apparirà con uno storico lineare: sembrerà che tutto il lavoro sia avvenuto in serie, anche se originariamente era in parallelo.
Spesso, lo si fa per assicurarti che i commit vengano applicati in modo chiaro su un branch remoto - magari di un progetto a cui si contribuisce ma non si gestisce.
In questo caso, lavoreresti in un branch e si ribaserà sopra origin/master quando si è pronti ad inviare le modifiche al progetto principale.
In questo modo, il maintainer non dovrà fare alcun lavoro di integrazione, semplicemente un fast-forward o un apply.
Nota che il commit punta lo snapshot con il quale ai concluso, comunque l’ultimo dei commit ribasati per il rebase o il commit di merge nel caso di merge, è lo stesso snapshot - solo lo storico è differente. Il rebase replica i cambiamenti di una flusso di lavoro in un altro nell’ordine in cui sono stati introdotti, mentre il merge prende le estremità e le unisce.
Rebase più interessanti
Puoi anche eseguire il rebase su un branch diverso dal branch di destinazione del rebase.
Prendi uno storico come Lo storico con un topic che si dirama da un altro branch, ad esempio.
Hai creato un branch a tema (server) per aggiungere al tuo progetto delle funzionalità server-side, e hai fatto dei commit.
Quindi, hai creato un branch per apportare le modifiche lato client (client) e hai eseguito il commit alcune volte.
Alla fine, sei tornato al branch server e hai eseguito altri commit.
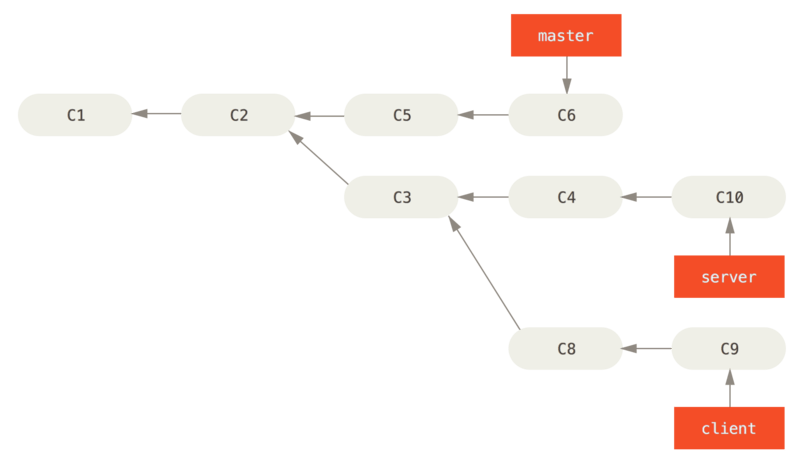
Supponiamo che tu decida di voler unire le modifiche lato client nel branch principale per una release, ma di voler tenere da parte le modifiche lato server fino a quando non vengono testate ulteriormente.
Puoi prendere le modifiche del client che non sono sul server (C8 e C9) e riprodurle sul branch principale usando l’opzione --onto di git rebase:
$ git rebase --onto master server clientQuesto fondamentalmente dice: "Controlla il branch client, trova le patch dal predecessore comune dei branch client e server, e poi riproducili su master".
È un po' complesso, ma il risultato è piuttosto interessante.
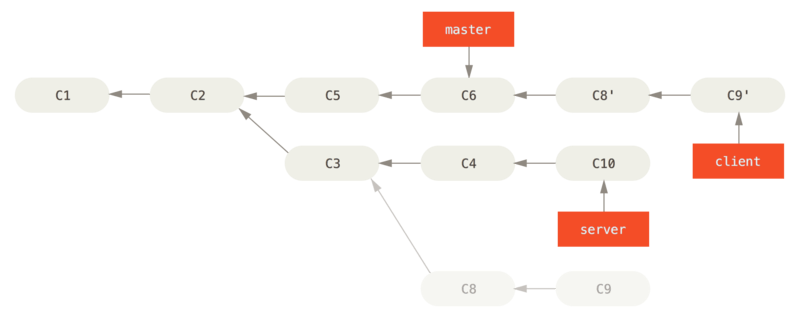
Adesso puoi aggiornare il tuo branch master (vedi Aggiornamento del branch principale per includere le modifiche del branch client):
$ git checkout master
$ git merge client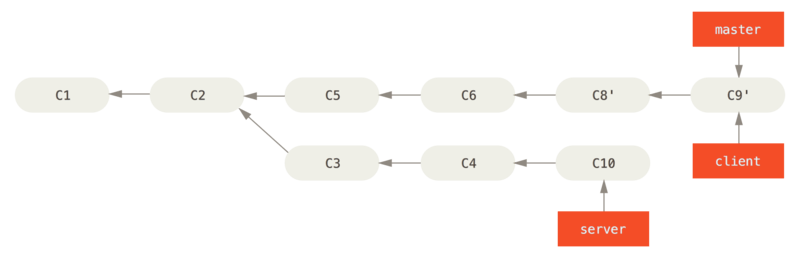
Supponiamo che tu decida di scaricare il branch server nel tuo.
Puoi ribasare il branch del server sul branch principale senza dover prima effettuare il checkout eseguendo git rebase [basebranch] [topicbranch] - che esegue il checkout del ramo dell’argomento (in questo caso, server) per te e lo riproduce sul branch di base ("master"):
$ git rebase master serverQuesto riproduce il lavoro del branch server sul branch master, come mostrato in Rebase del tuo branch server sul branch principale.

server sul branch principaleAdesso, puoi aggiornare il branch principale (master):
$ git checkout master
$ git merge serverPuoi rimuovere i branch client e` server` perché tutto il lavoro è integrato e non ne hai più bisogno, lasciando lo storico per l’intero processo come in Final commit history:
$ git branch -d client
$ git branch -d server
I pericoli del rebase
Ahh, ma la bellezza del rebase non è priva di inconvenienti, che possono essere riassunti in una sola riga:
Non ribasare i commit che esistono al di fuori del tuo repository.
Se userai questa regola, tutto andrà bene. Se non lo farai, le persone ti odieranno, e ti scontrerai con amici e familiari.
Quando ribasate qualcosa, abbandonate i commit esistenti e ne create di nuovi simili ma diversi.
Se esegui il push di commit su un repository remoto ed altri ne useguono il pull proseguendo il lavoro, e poi sovrascrivi quei commit con git rebase e ne riesegui il push, i tuoi collaboratori dovranno effettuare nuovamente il merge del loro lavoro e le cose si complicheranno quando tu proverai a eseguire il pull del loro lavoro nel tuo.
Diamo un’occhiata a un esempio di come il lavoro di rebase che hai reso pubblico può causare problemi. Supponiamo di clonare da un server centrale e poi di lavorare su quello. Lo storico dei commit ha questo aspetto:
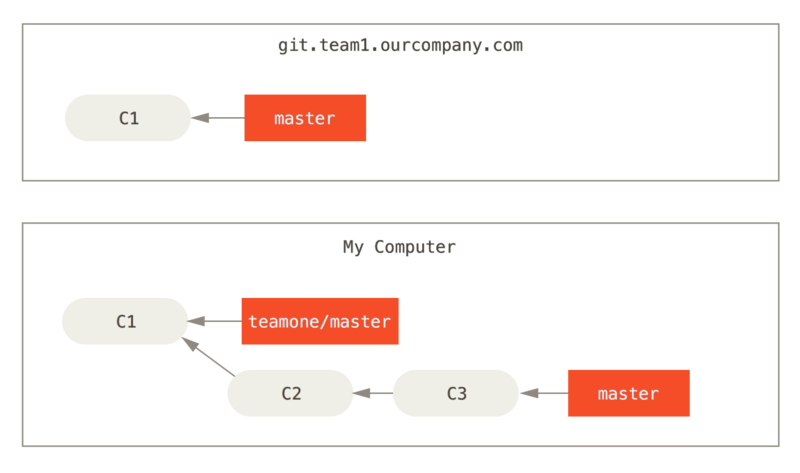
Ora, qualcun altro esegue del lavoro che include un merge ed esegue il push di quel lavoro sul server centrale. Esegui il fetch ed unisci il nuovo branch remoto nel tuo lavoro, rendendo la tua cronologia simile a questa:
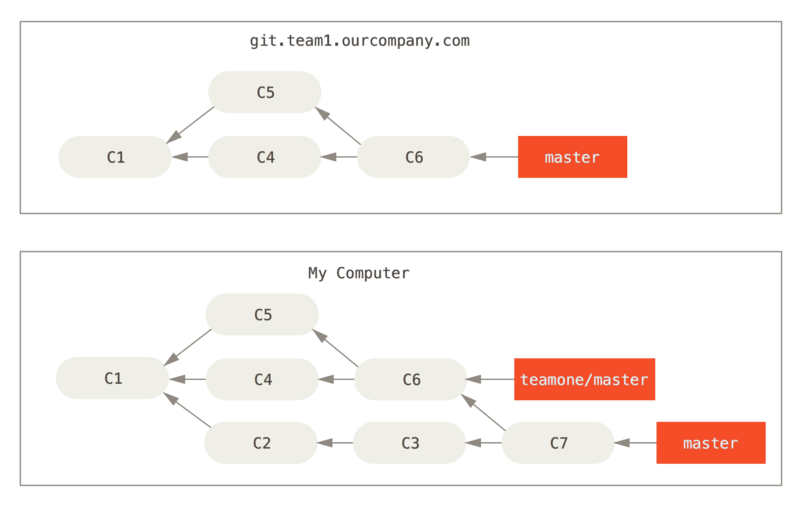
Successivamente, la persona che ha eseguito il push del lavoro congiunto decide invece di ribasare il proprio lavoro; esegue un git push --force per sovrascrivere la cronologia sul server.
Quindi esegui il fetch da quel server, scaricando i nuovi commit.
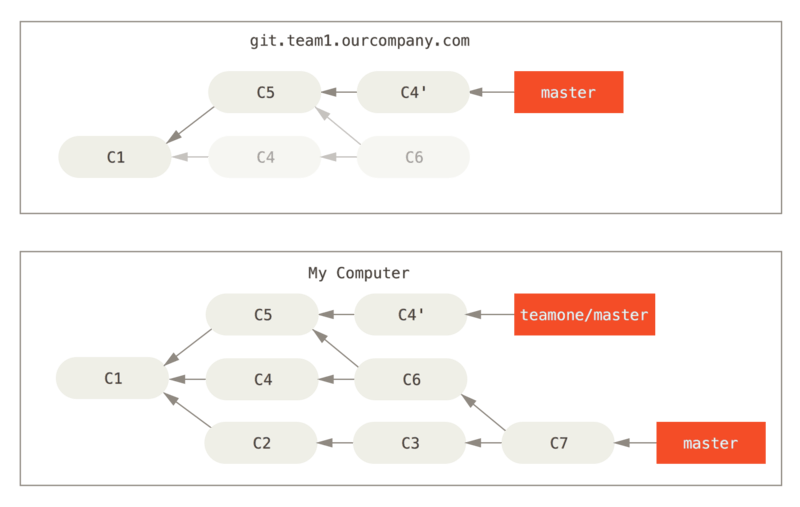
Ora siete entrambi in un pasticcio.
Se esegui un git pull, creerai un commit di unione che include entrambe le righe di cronologia e il tuo repository sarà simile a questo:
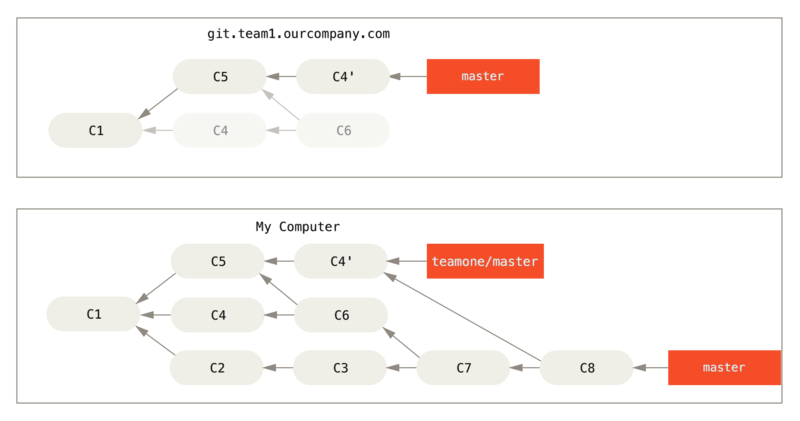
Se esegui un git log quando la tua cronologia ha questo aspetto, vedrai due commit con lo stesso autore, data e messaggio, il che creerà confusione.
Inoltre, se esegui il push di questa cronologia sul server, reintrodurrai tutti quei commit ribasati sul server centrale, il che può confondere ulteriormente le persone.
È abbastanza lecito presumere che l’altro sviluppatore non voglia che "C4" e "C6" siano nello storico; ecco perché ha ribasato precedentemente.
Ribasa quando si ribasa
Se ti trovi in una situazione come questa, Git ha qualche ulteriore magia che potrebbe aiutarti. Se qualcuno del tuo team impone modifiche che sovrascrivono il lavoro su cui hai basato il tuo, la tua sfida è capire cosa è tuo e cosa hanno riscritto.
Si scopre che oltre al checksum SHA del commit, Git calcola anche un checksum basato solo sulla patch introdotta con il commit. Questo è chiamato “patch-id”.
Se scarichi il lavoro che è stato riscritto e lo ribasi in cima ai nuovi commit del tuo collega, Git di solito capisce cosa è tuo e può applicarlo di nuovo in cima al nuovo branch.
Ad esempio, nello scenario precedente, se invece di fare un merge quando siamo a Qualcuno esegue il push dei commit ribasati, abbandonando i commit su cui hai basato il tuo lavoro eseguiamo git rebase teamone / master, Git:
-
Determina quale lavoro è unico per il nostro ramo (C2, C3, C4, C6, C7)
-
Determina quali non sono merge commit (C2, C3, C4)
-
Determina quali non sono stati riscritti nel ramo di destinazione (solo C2 e C3, poiché C4 è la stessa patch di C4')
-
Applica questi commit all’inizio di
teamone/master
Quindi, invece del risultato che vediamo in Congiungi di nuovo lo stesso lavoro in un nuovo commit di unione, finiremmo con qualcosa di più simile a Rebase in cima al lavoro di rebase con push forzato..
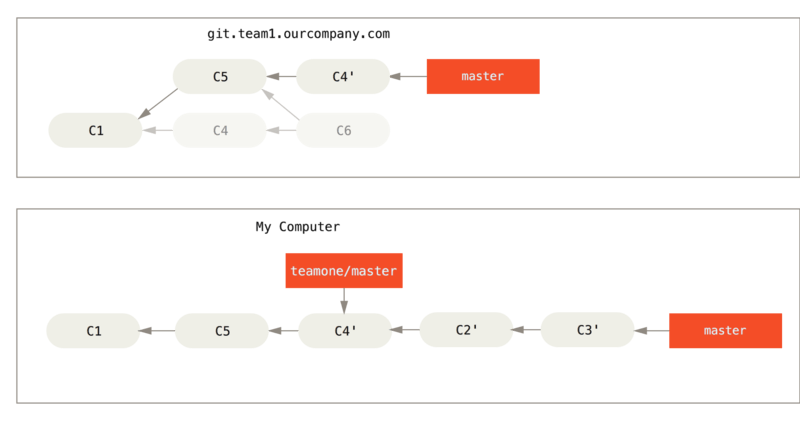
Funziona solo se C4 e C4' che il tuo partner ha creato sono quasi esattamente la stessa patch. Altrimenti il rebase non sarà in grado di dire che si tratta di un duplicato e aggiungerà un’altra patch simile a C4 (che probabilmente non si applicherà in modo pulito, poiché le modifiche sarebbero già lì).
Puoi anche semplificarlo eseguendo un git pull --rebase invece di un normale` git pull`. Oppure, in questo caso, potresti farlo manualmente con un git fetch seguito da un git rebase teamone/master.
Se stai usando git pull e vuoi rendere` --rebase` predefinito, puoi impostare la configurazione pull.rebase con qualcosa tipo git config --global pull.rebase true.
Se usi il rebase come un modo per lavorare e ripulire i commit prima del push, e se ribasi solo i commit che non sono mai stati disponibili pubblicamente, allora tutto andrà bene. Se ribasi i commit che sono già stati pubblicati e qualcuno ha basato il lavoro su di essi, allora potreste trovarvi in una situazione frustrante e i tuoi colleghi ti odieranno.
Se tu o un collega lo trovate necessario ad un certo punto, assicurati che tutti eseguano git pull --rebase per cercare di rendere tutto meno doloroso.
Rebase vs. Merge
Ora che hai visto rebase e merge in azione, potresti chiederti quale sia il migliore. Prima di poter rispondere a questa domanda, facciamo un passo indietro e parliamo di cosa significa lo storico.
Da un certo punto di vista lo storico dei commit del tuo repository è un registro di ciò che è realmente accaduto. È un documento storico, di per sé prezioso e non dovrebbe essere manomesso. Da questo punto di vista, cambiare lo storico dei commit è quasi blasfemo; stai mentendo su ciò che è effettivamente accaduto. E se ci fosse una serie caotica di merge commit? È quello che è successo e il repository dovrebbe raccontarlo ai posteri.
Il punto di vista opposto è che la cronologia dei commit è la storia di come è stato realizzato il tuo progetto. Non pubblicheresti la prima bozza di un libro e il manuale su come mantenere il tuo software merita un’attenta revisione. Questo è il punto di vista di chi utilizza strumenti come rebase e filter-branch per raccontare la storia nel modo migliore per i futuri lettori.
Ora, alla domanda se sia meglio merge o rebase: è evidente che non è così semplice. Git è uno strumento potente e ti consente di fare molte cose per e con il tuo storico, ma ogni team e ogni progetto è diverso. Ora che sai come funzionano entrambe queste cose, sta a te decidere quale è la migliore per la tua situazione particolare.
In generale, il modo per ottenere il meglio da entrambi i mondi è riformulare le modifiche locali che hai apportato ma che non hai ancora condiviso prima del push, al fine di ripulire lo storico, ma non ribasare mai nulla di cui hai fatto il push da qualche parte.