
-
1. Per Iniziare
- 1.1 Il Controllo di Versione
- 1.2 Una Breve Storia di Git
- 1.3 Cos’é Git?
- 1.4 La riga di comando
- 1.5 Installing Git
- 1.6 First-Time Git Setup
- 1.7 Chiedere aiuto
- 1.8 Sommario
-
2. Git Basics
- 2.1 Getting a Git Repository
- 2.2 Recording Changes to the Repository
- 2.3 Viewing the Commit History
- 2.4 Undoing Things
- 2.5 Working with Remotes
- 2.6 Tagging
- 2.7 Git Aliases
- 2.8 Sommario
-
3. Git Branching
- 3.1 Branches in a Nutshell
- 3.2 Basic Branching and Merging
- 3.3 Branch Management
- 3.4 Branching Workflows
- 3.5 Remote Branches
- 3.6 Rebasing
- 3.7 Summary
-
4. Git on the Server
- 4.1 The Protocols
- 4.2 Getting Git on a Server
- 4.3 Generating Your SSH Public Key
- 4.4 Setting Up the Server
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Third Party Hosted Options
- 4.10 Summary
-
5. Distributed Git
- 5.1 Distributed Workflows
- 5.2 Contributing to a Project
- 5.3 Maintaining a Project
- 5.4 Summary
-
6. GitHub
-
7. Git Tools
- 7.1 Revision Selection
- 7.2 Interactive Staging
- 7.3 Stashing and Cleaning
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Rewriting History
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugging with Git
- 7.11 Submodules
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Summary
-
8. Customizing Git
- 8.1 Git Configuration
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git and Other Systems
- 9.1 Git as a Client
- 9.2 Migrating to Git
- 9.3 Summary
-
10. Git Internals
- 10.1 Plumbing and Porcelain
- 10.2 Git Objects
- 10.3 Git References
- 10.4 Packfiles
- 10.5 The Refspec
- 10.6 Transfer Protocols
- 10.7 Maintenance and Data Recovery
- 10.8 Environment Variables
- 10.9 Summary
-
A1. Appendice A: Git in altri contesti
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Riassunto
-
A2. Appendice B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendice C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
1.1 Per Iniziare - Il Controllo di Versione
Questo capitolo spiegherà come iniziare ad usare Git. Inizieremo con una introduzione sugli strumenti per il controllo delle versioni, per poi passare a come far funzionare Git sul proprio sistema e quindi come configurarlo per lavorarci. Alla fine di questo capitolo, dovresti capire a cosa serve Git, perché dovresti usarlo e dovresti essere pronto ad usarlo.
Il Controllo di Versione
Cos’è il "controllo di versione", e perché dovresti usarlo? Il controllo di versione è un sistema che registra, nel tempo, i cambiamenti ad un file o ad una serie di file, così da poter richiamare una specifica versione in un secondo momento. Per gli esempi di questo libro verrà usato il codice sorgente di un software come file sotto controllo di versione, anche se in realtà gli esempi si possono eseguire quasi con ogni tipo di file sul computer.
Se sei un grafico o un webdesigner e vuoi tenere tutte le versioni di un’immagine o di un layout (cosa che sicuramente vorresti), un Sistema per il Controllo di Versione (VCS) è una cosa saggia da utilizzare. Un VCS ti permette di ripristinare i file ad una versione precedente, ripristinare l’intero progetto a uno stato precedente, revisionare le modifiche fatte nel tempo, vedere chi ha cambiato qualcosa che può aver causato un problema, chi ha introdotto un problema e quando, e molto altro ancora. Usare un VCS, in generale, significa anche che se fai un pasticcio o perdi qualche file, puoi facilmente recuperare la situazione. E ottieni tutto questo con poca fatica.
Sistema di Controllo di Versione Locale
Molte persone gestiscono le diverse versioni copiando i file in un’altra directory (magari una directory denominata con la data, se sono furbi). Questo approccio è molto comune perché è molto semplice, ma è anche incredibilmente soggetto ad errori. É facile dimenticare in quale directory sei e modificare il file sbagliato o copiare dei file che non intendevi copiare.
Per far fronte a questo problema, i programmatori svilupparono VCS locali che avevano un database semplice che manteneva tutti i cambiamenti dei file sotto controllo di revisione.
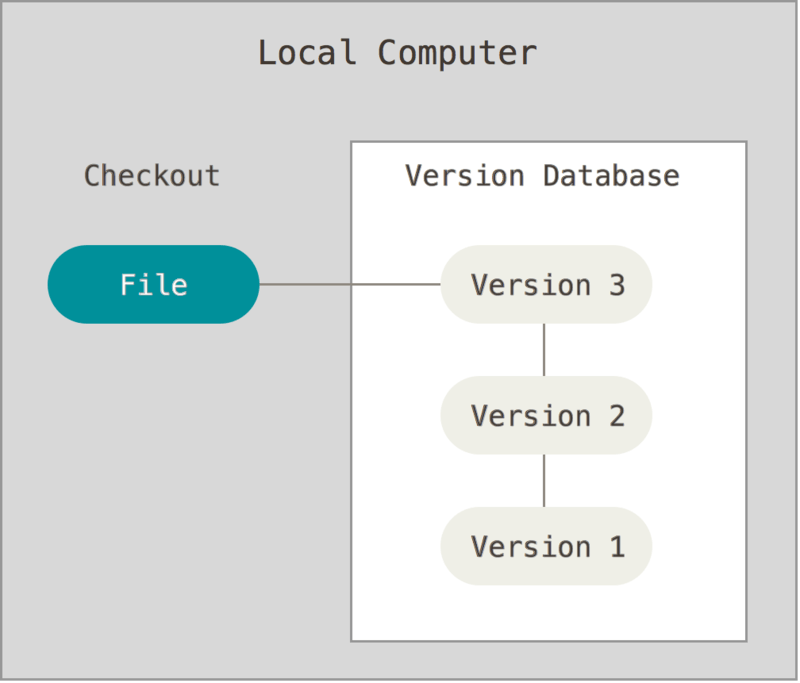
Uno dei più popolari strumenti VCS era un sistema chiamato RCS, che è ancora oggi distribuito con molti computer. RCS funziona salvando sul disco in un formato specifico un insieme di patch (ovvero le differenze tra i file); può quindi ricreare lo stato di qualsiasi file in qualsiasi momento determinato, aggiungendo le varie patch.
Sistemi di Controllo di Versione Centralizzati
Successivamente queste persone dovettero affrontare il problema del collaborare con altri sviluppatori su altri sistemi. Per far fronte a questo problema, vennero sviluppati sistemi di controllo di versione centralizzati (CVCS). Questi sistemi (come CVS, Subversion e Perforce) hanno un unico server che contiene tutte le versioni dei file e un numero di utenti che scaricano i file dal server centrale. Questo è stato lo standard del controllo di versione per molti anni.
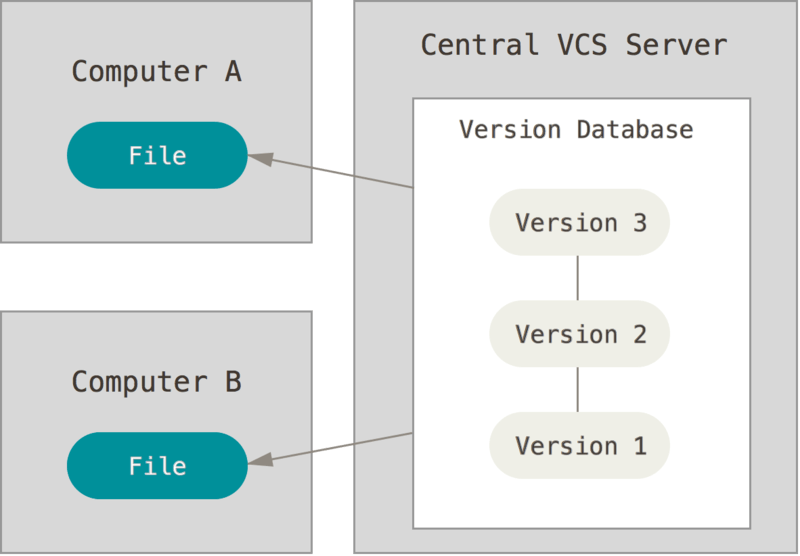
Questa impostazione offre molti vantaggi, specialmente rispetto ai VCS locali. Per esempio, chiunque sa, con una certa approssimazione, cosa stia facendo un’altra persona del progetto. Gli amministratori hanno un controllo preciso su chi può fare cosa, ed è molto più facile amministrare un CVCS che un database locale su ogni client.
Questa configurazione ha tuttavia alcune gravi controindicazioni. La più ovvia è che il server centralizzato rappresenta il singolo punto di rottura del sistema. Se questo va giù per un’ora, in quel periodo nessuno può collaborare o salvare una nuova versione di qualsiasi cosa su cui sta lavorando. Se il disco rigido del database centrale si danneggia, e non ci sono i backup, perdi assolutamente tutto — tutta la storia del progetto ad eccezione dei singoli snapshot (istantanee) che le persone possono avere in locale sulle loro macchine. Anche i sistemi locali di VCS soffrono di questo problema — ogni volta che tutta la storia del progetto è in un unico posto, si rischia di perdere tutto.
Sistemi di Controllo di Versione Distribuiti
E qui entrano in gioco i Sistemi di Controllo di Versione Distribuiti (DVCS). In un DVCS (come Git, Mercurial, Bazaar o Darcs), i client non solo controllano lo snapshot più recente dei file, ma piuttosto fanno una copia identica dell’archivio (repository), completa di tutta la propria storia. In questo modo se un server smettesse di funzionare e se i sistemi interagissero tramite questo server, il repository di un qualsiasi client potrebbe essere copiato sul server per ripristinarlo. Ogni clone è proprio un backup completo di tutti i dati.
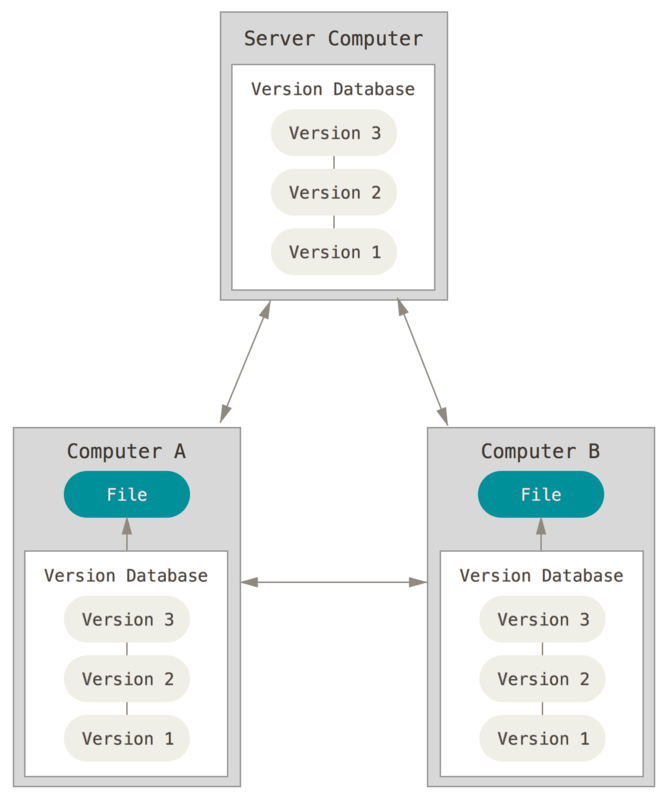
Inoltre, molti di questi sistemi trattano bene l’avere più repository remoti su cui poter lavorare, così puoi collaborare con gruppi differenti di persone in modi differenti, simultaneamente sullo stesso progetto. Questo ti permette di impostare diversi tipi di flussi di lavoro che non sono possibili in sistemi centralizzati, come i modelli gerarchici.