
-
1. Erste Schritte
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches auf einen Blick
- 3.2 Einfaches Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Erstellung eines SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git-Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Von Drittanbietern gehostete Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisions-Auswahl
- 7.2 Interaktives Stagen
- 7.3 Stashen und Bereinigen
- 7.4 Deine Arbeit signieren
- 7.5 Suchen
- 7.6 Den Verlauf umschreiben
- 7.7 Reset entzaubert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debuggen mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Replace (Ersetzen)
- 7.14 Anmeldeinformationen speichern
- 7.15 Zusammenfassung
-
8. Git einrichten
- 8.1 Git Konfiguration
- 8.2 Git-Attribute
- 8.3 Git Hooks
- 8.4 Beispiel für Git-forcierte Regeln
- 8.5 Zusammenfassung
-
9. Git und andere VCS-Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git Interna
-
A1. Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Schnittstellen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
A2. Anhang B: Git in deine Anwendungen einbetten
- A2.1 Die Git-Kommandozeile
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Anhang C: Git Kommandos
- A3.1 Setup und Konfiguration
- A3.2 Projekte importieren und erstellen
- A3.3 Einfache Snapshot-Funktionen
- A3.4 Branching und Merging
- A3.5 Projekte gemeinsam nutzen und aktualisieren
- A3.6 Kontrollieren und Vergleichen
- A3.7 Debugging
- A3.8 Patchen bzw. Fehlerkorrektur
- A3.9 E-mails
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Basisbefehle
3.6 Git Branching - Rebasing
Rebasing
Es gibt bei Git zwei Wege, um Änderungen von einem Branch in einen anderen zu integrieren: merge und rebase.
In diesem Abschnitt wirst du erfahren, was Rebasing ist, wie du es anwendest, warum es ein ziemlich erstaunliches Werkzeug ist und bei welchen Gelegenheiten du es besser nicht einsetzen solltest.
Einfacher Rebase
Wenn du dich noch mal ein früheres Beispiel aus Einfaches Merging anschaust, kannst du sehen, dass du deine Arbeit verzweigt und Commits auf zwei unterschiedlichen Branches erstellt hast.
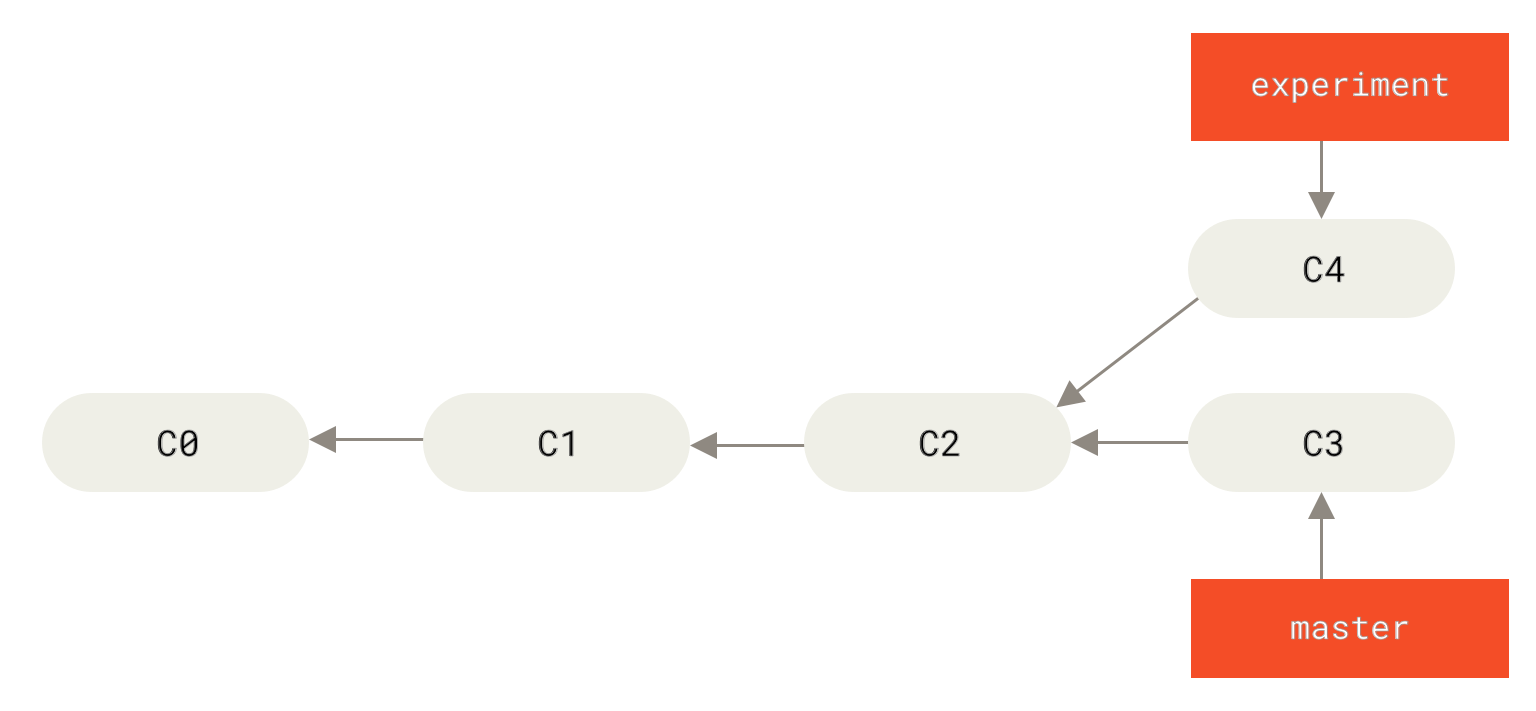
Der einfachste Weg, die Branches zu integrieren ist der Befehl merge, wie wir bereits besprochen haben.
Er führt einen Drei-Wege-Merge zwischen den beiden letzten Branch-Snapshots (C3 und C4) und dem jüngsten gemeinsamen Vorgänger der beiden (C2) durch und erstellt einen neuen Snapshot (und Commit).
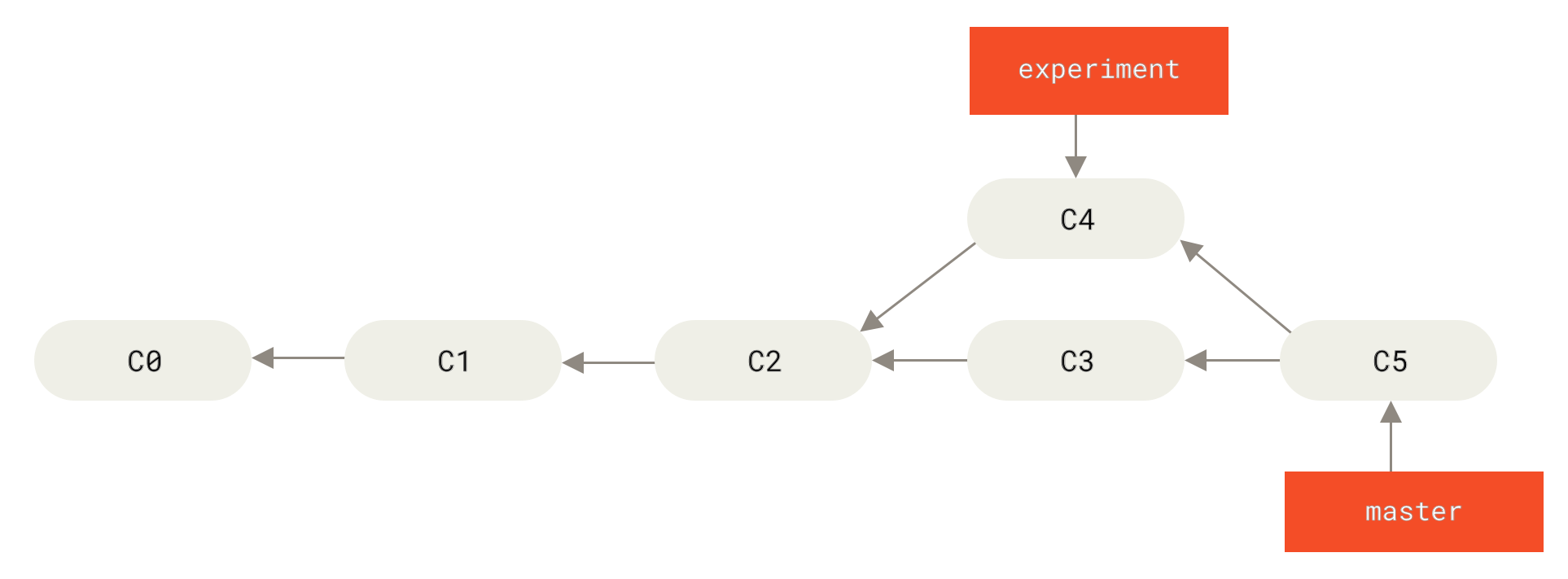
Allerdings gibt es noch einen anderen Weg: Du kannst den Patch der Änderungen, den wir in C4 eingeführt haben, nehmen und am Ende von C3 erneut anwenden.
Dieses Vorgehen nennt man in Git rebasing.
Mit dem Befehl rebase kannst du alle Änderungen, die in einem Branch vorgenommen wurden, übernehmen und in einem anderen Branch wiedergeben.
Für dieses Beispiel würdest du den Branch experiment auschecken und dann wie folgt auf den master Branch restrukturieren (engl. rebase):
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged commandDies funktioniert, indem Git zum letzten gemeinsamen Vorgänger der beiden Branches (der, auf dem du arbeitest, und jener, auf den du rebasen möchtest) geht, dann die Informationen zu den Änderungen (diffs) sammelt, welche seitdem bei jedem einzelnen Commit des aktuellen Branches gemacht wurden, diese in temporären Dateien speichert, den aktuellen Branch auf den gleichen Commit setzt wie den Branch, auf den du rebasen möchtest, und dann alle Änderungen erneut durchführt.
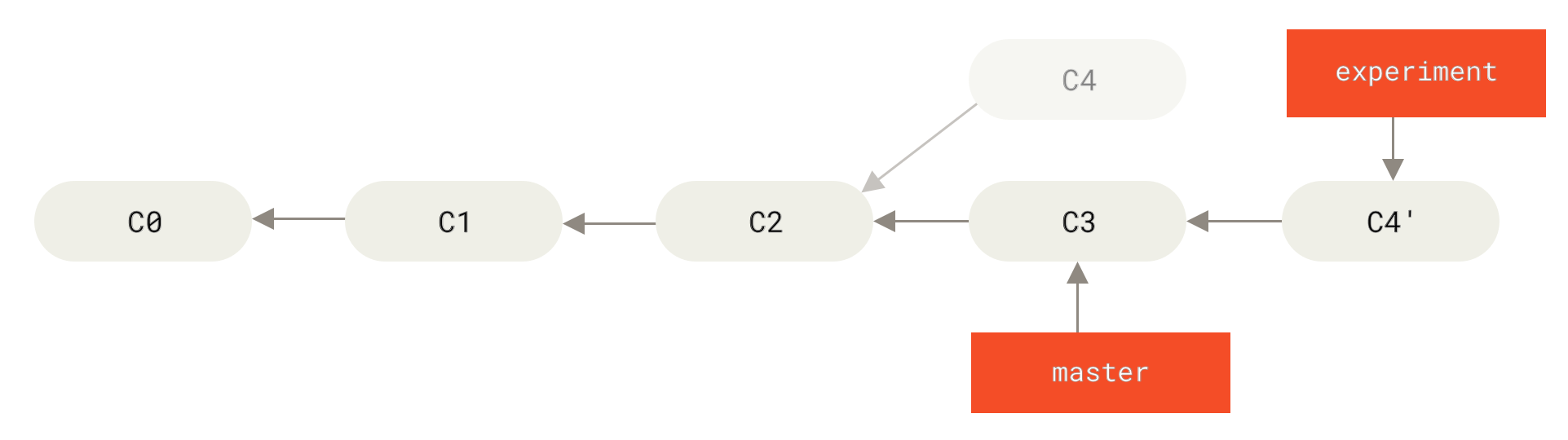
C4 eingeführten Änderung auf C3
An diesem Punkt kannst du zum vorherigen master Branch wechseln und einen fast-forward-Merge durchführen.
$ git checkout master
$ git merge experiment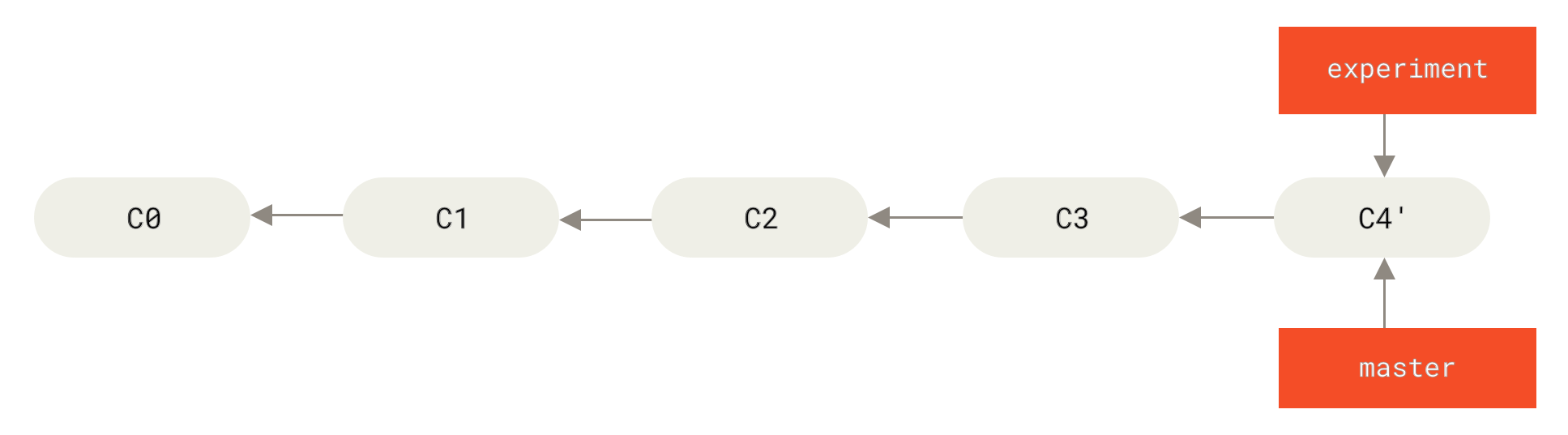
master BranchesJetzt ist der Schnappschuss, der auf C4' zeigt, exakt derselbe wie derjenige, auf den C5 in dem Merge-Beispiel gezeigt hat.
Es gibt keinen Unterschied im Endergebnis der Integration. Das Rebase sorgt jedoch für eine klarere Historie.
Wenn man das Protokoll eines rebase Branches betrachtet, sieht es wie eine lineare Historie aus: Es scheint, dass alle Arbeiten sequentiell stattgefunden hätten, auch wenn sie ursprünglich parallel stattgefunden haben.
Häufig wirst du das anwenden, damit deine Commits sauber auf einen Remote-Branch angewendet werden – vielleicht in einem Projekt, zu dem du beitragen möchtest, das du aber nicht pflegst.
Du würdest deine Änderungen in einem lokalen Branch durchführen und diese im Anschluss mittels rebase zu origin/master dem Hauptprojekt hinzufügen.
Auf diese Weise muss der Maintainer keine Integrationsarbeiten durchführen – nur einen „fast-forward“ oder ein einfaches Einbinden deines Patches.
Beachte, dass der Snapshot, auf welchen der letzte Commit zeigt, ob es nun der letzte des Rebase-Commits nach einem Rebase oder der finale Merge-Commit nach einem Merge ist, derselbe Schnappschuss ist. Nur der Verlauf ist ein anderer. Rebasing wiederholt die Änderungsschritte von einer Entwicklungslinie auf einer anderen in der Reihenfolge, in der sie entstanden sind. Dagegen werden beim Merge die beiden Endpunkte der Branches genommen und miteinander gemerged.
Weitere interessante Rebases
Du kannst dein Rebase auch auf einen anderen Branch als den Rebase-Ziel-Branch anwenden.
Nimm zum Beispiel einen Verlauf wie im Bild: Ein Verlauf mit einem Feature-Branch neben einem anderen Feature-Branch.
Du hast einen Feature-Branch (server) angelegt, um ein paar serverseitige Funktionalitäten zu deinem Projekt hinzuzufügen, und hast dann einen Commit gemacht.
Anschließend hast du von diesem einen weiteren Branch abgezweigt, um clientseitige Änderungen (client) vorzunehmen. Auch hier hast du ein paar Commits durchgeführt.
Zum Schluss wechselst du wieder zu deinem vorherigen server Branch und machst weitere Commits.
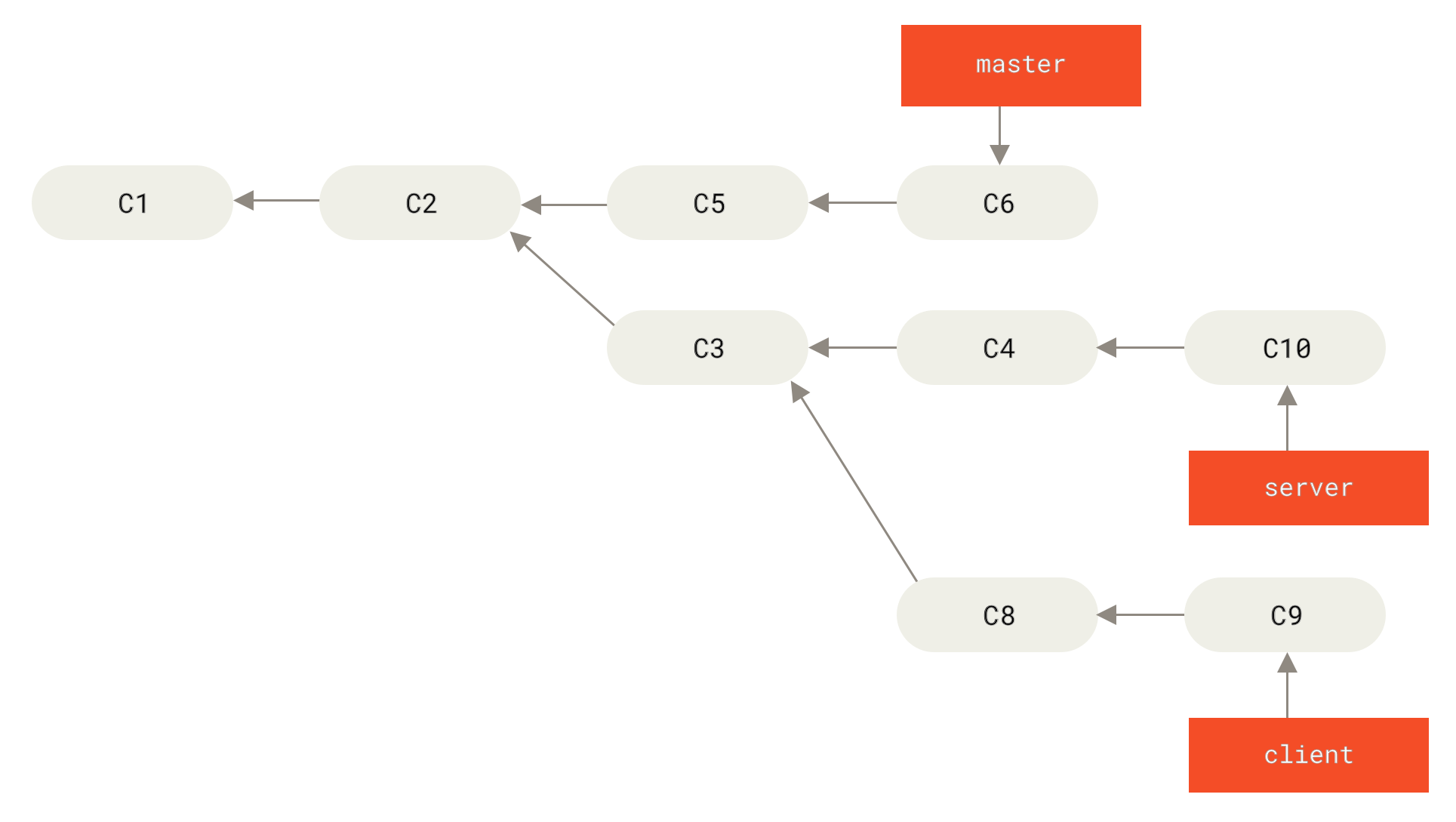
Angenommen, du entscheidest dich, dass du für einen Release deine clientseitigen Änderungen mit deiner Hauptentwicklungslinie zusammenführst, während du die serverseitigen Änderungen noch zurückhalten willst, bis diese weiter getestet wurden.
Du kannst die Änderungen auf dem client Branch, die nicht auf dem server Branch (C8 und C9) sind, übernehmen und sie in deinem master Branch wiedergeben, indem du die Option --onto von git rebase verwendest:
$ git rebase --onto master server clientDas bedeutet im Wesentlichen, „Checke den client Branch aus, finde die Patches des gemeinsamen Vorgängers der Branches client und server heraus und wende sie erneut auf den master Branch an.“
Das ist ein wenig komplex, aber das Resultat ist ziemlich toll.
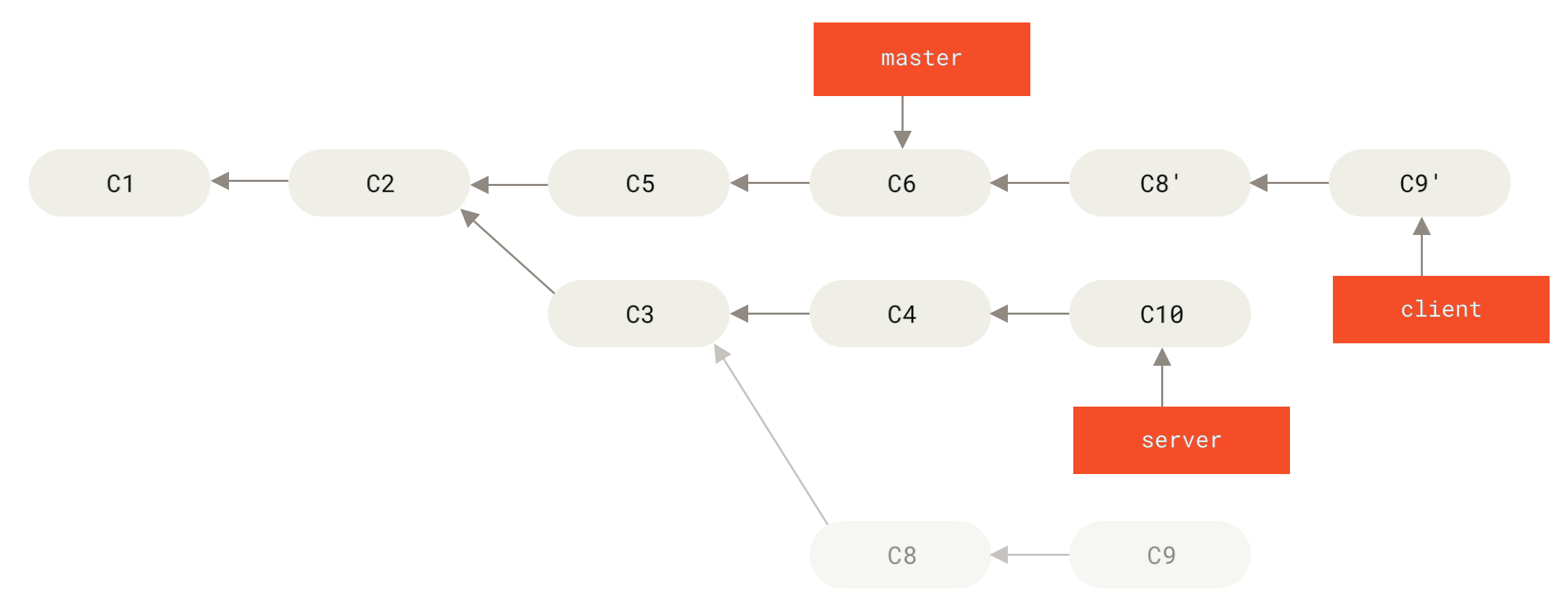
Jetzt kannst du deinen Master-Branch vorspulen (engl. fast-forward) (siehe Vorspulen deines master Branches zum Einfügen der Änderungen des client Branches):
$ git checkout master
$ git merge client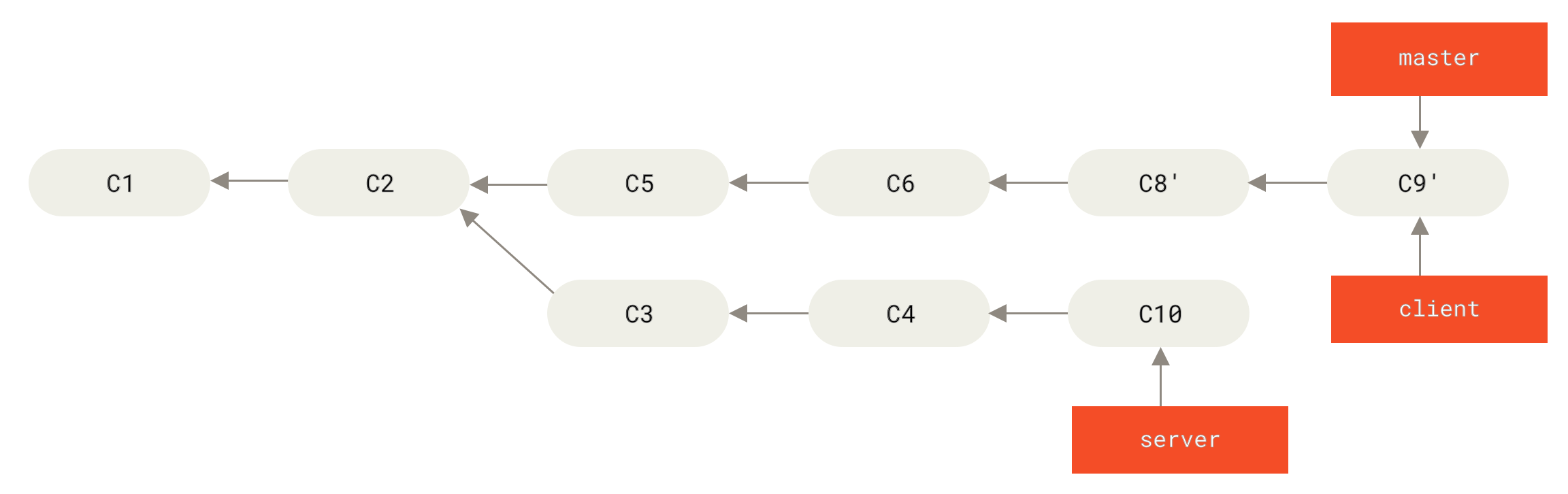
master Branches zum Einfügen der Änderungen des client BranchesLass uns annehmen, du entscheidest dich dazu, deinen server Branch ebenfalls einzupflegen.
Du kannst das Rebase des server Branches auf den master Branch anwenden, ohne diesen vorher auschecken zu müssen, indem du die Anweisung git rebase <Basis-Branch> <Feature-Branch> ausführst, welche für dich den Feature-Branch auscheckt (in diesem Fall server) und ihn auf dem Basis-Branch (master) wiederholt:
$ git rebase master serverDas wiederholt deine Änderungen aus dem server Branch am Ende des master Branches, wie in Rebase deines server Branches am Ende deines master Branches gezeigt wird.

server Branches am Ende deines master BranchesDann kannst du den Basis-Branch (master) vorspulen (engl. fast-forward):
$ git checkout master
$ git merge serverDu kannst die Branches client und server löschen, da die ganze Arbeit bereits in master integriert wurde und du diese nicht mehr benötigst. Dein Verlauf für diesen gesamten Prozess sieht jetzt wie in Endgültiger Commit-Verlauf aus:
$ git branch -d client
$ git branch -d server
Die Gefahren des Rebasing
Ahh, aber der ganze Spaß mit dem Rebasen kommt nicht ohne Schattenseiten und Fallstricke, welche in einer einzigen Zeile zusammengefasst werden können:
Führe keinen Rebase mit Commits durch, die außerhalb deines Repositorys existieren und auf welche die Arbeit anderer Personen basiert.
Wenn du dich an diese Leitlinie hältst, wirst du gut zurechtkommen. Wenn du es nicht tust, werden die Leute dich hassen und du wirst von Freunden und Familie verschmäht werden.
Wenn du ein Rebase durchführst, entfernst du bestehende Commits und erstellen stattdessen neue, die zwar ähnlich aber dennoch unterschiedlich sind. Stell dir vor, du lädst diese Commits hoch und andere laden sich diese herunter und nehmen sie als Grundlage für ihre Arbeit. Dann änderst du jedoch ihre commits nochmal und rebasen und pushst sie. Deine Kollegen müssen ihre Änderungen nochmal remergen. Wenn sie nun versuchen diesen remerge bei sich zu pullen, wird das nicht funktionieren und es kommt zu einem heillosen Durcheinander.
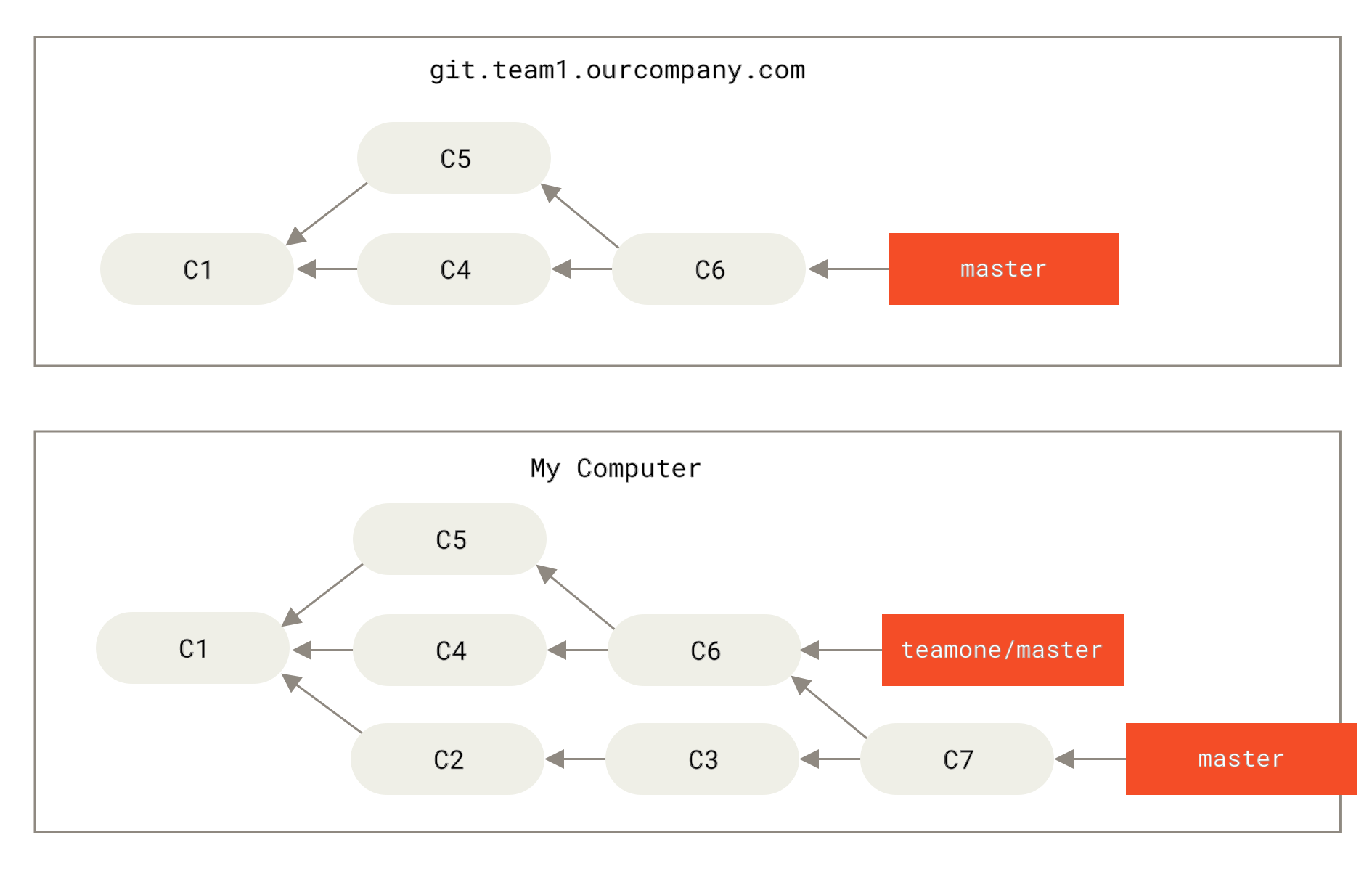
Schauen wir uns ein Beispiel an, wie ein Rebase von Arbeiten, die du öffentlich gemacht hast, Probleme verursachen kann. Nehmen wir an, du klonst ein Repository von einem zentralen Server und machst ein paar Änderungen. Dein Commit-Verlauf sieht anschließend so aus:
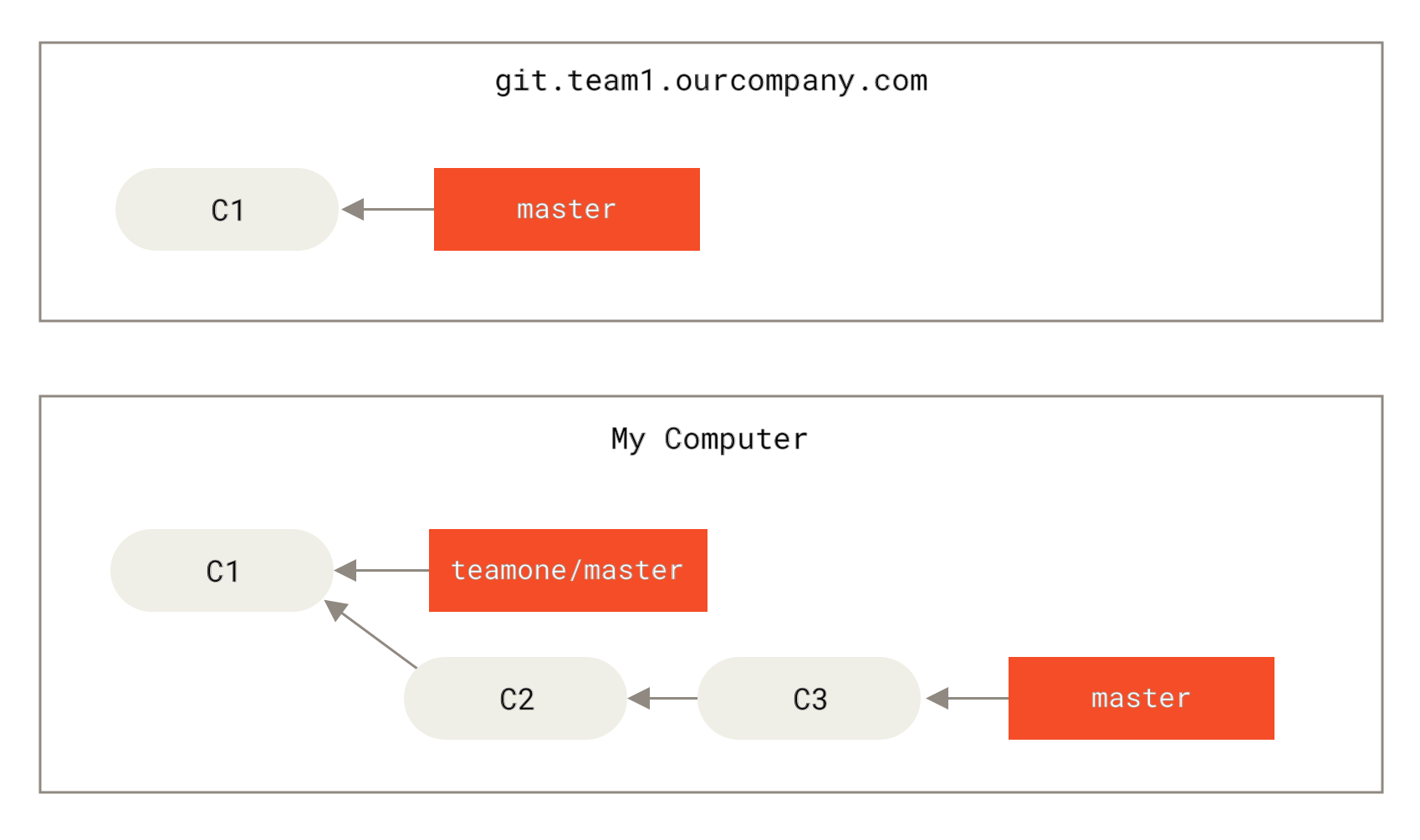
Nun macht jemand anderes Änderungen am Code, einschließlich eines Merges und pusht diese dann auf den zentralen Server. Du holst die Änderungen ab und mergst den neuen Remote-Branch mit deiner Arbeit, sodass dein Verlauf wie folgt aussieht.
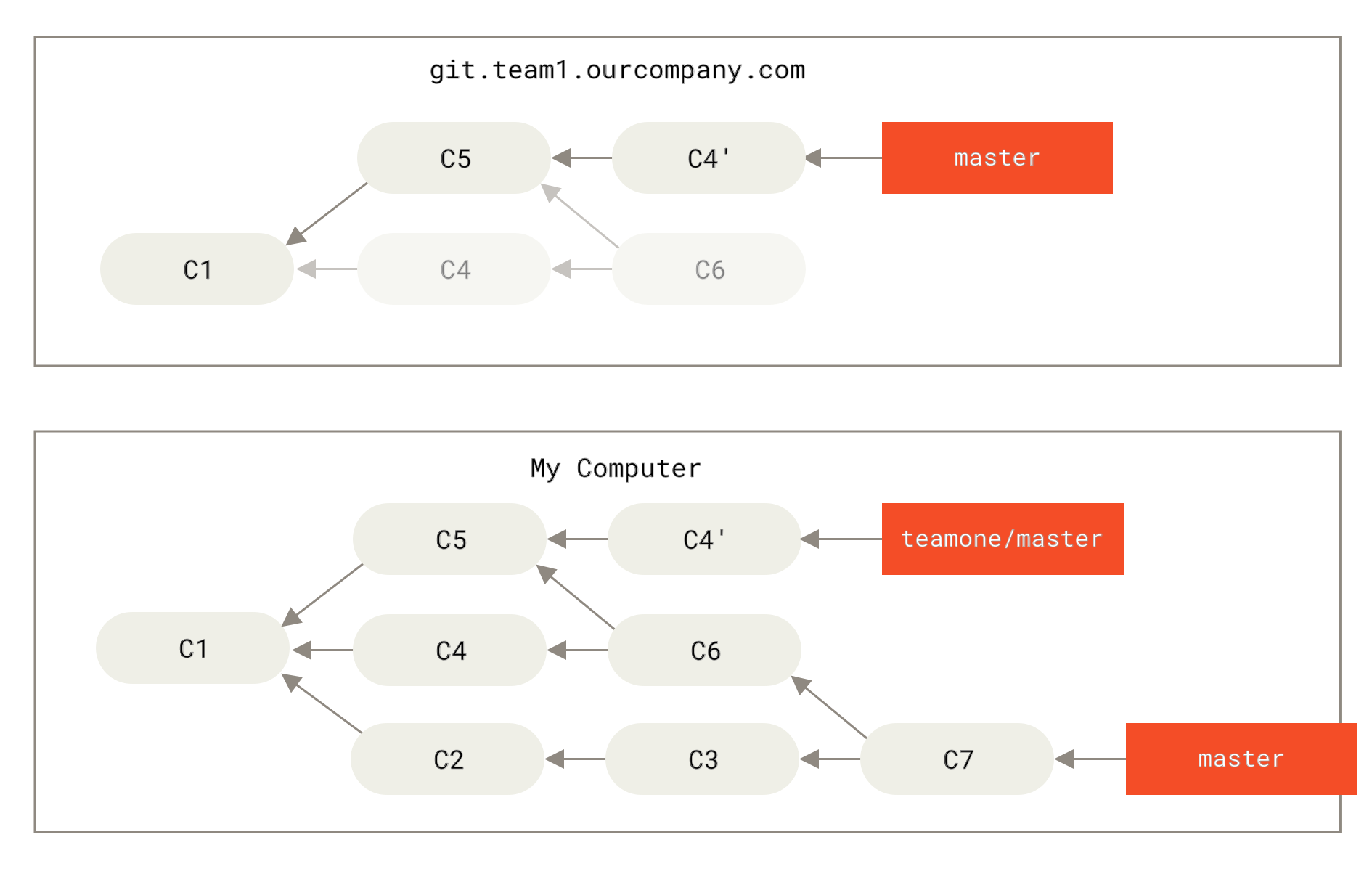
Als nächstes entscheidet die Person, welche die gemergte Arbeit hochgeladen hat, diese rückgängig zu machen und stattdessen deine Arbeit mittels Rebase hinzuzufügen. Sie führt dazu die Anweisung git push --force aus, um den Verlauf auf dem Server zu überschreiben.
Du holst das Ganze dann von diesem Server ab und lädst die neuen Commits herunter.
Jetzt sitzt ihr beide in der Klemme.
Wenn du ein git pull durchführst, würdest du einen Merge-Commit erzeugen, welcher beide Entwicklungslinien einschließt und dein Repository würde so aussehen:
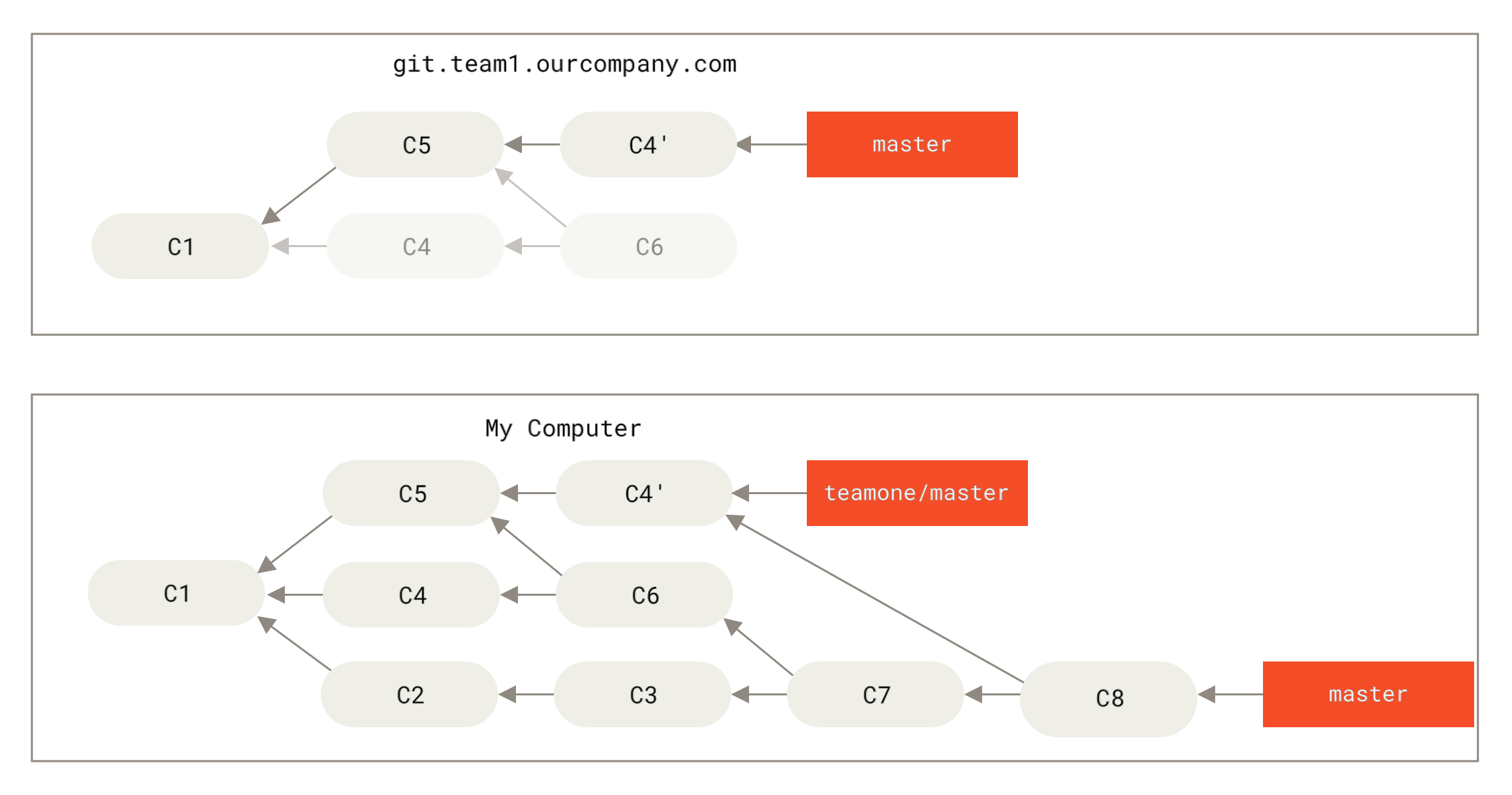
Falls du ein git log ausführst, wenn dein Verlauf so aussieht, würdest du zwei Commits sehen, bei denen Autor, Datum und Nachricht übereinstimmen, was verwirrend ist.
Weiter würdest du, wenn du diesen Verlauf zurück auf den Server pushst, alle diese vom Rebase stammenden Commits auf dem zentralen Server ablegen, was die Kollegen noch weiter durcheinander bringen würde.
Man kann ziemlich sicher davon ausgehen, dass der andere Entwickler C4 und C6 nicht im Verlauf haben möchte; das ist der Grund, warum derjenige das Rebase überhaupt gemacht hat.
Rebasen, wenn du Rebase durchführst
Wenn du dich in einer solchen Situation befindest, hat Git eine weitere magische Funktion, die dir helfen könnte. Falls jemand in deinem Team forcierte Änderungen pusht, die Arbeiten überschreiben, auf denen deine basiert, besteht deine Herausforderung darin, herauszufinden, was dir gehört und was andere überschrieben haben.
Es stellt sich heraus, dass Git neben der SHA-1-Prüfsumme eine weitere Prüfsumme berechnet, die nur auf den mit dem Commit eingeführten Änderungen basiert. Diese wird „patch-id“ genannt.
Wenn du die neu umgeschriebene Änderungen pullen und ein Rebase auf auf die neuen Commits deines Partners ausführst, kann Git oft erfolgreich herausfinden, was nur von dir ist und kann es entsprechend auf den neuen Branch anwenden.
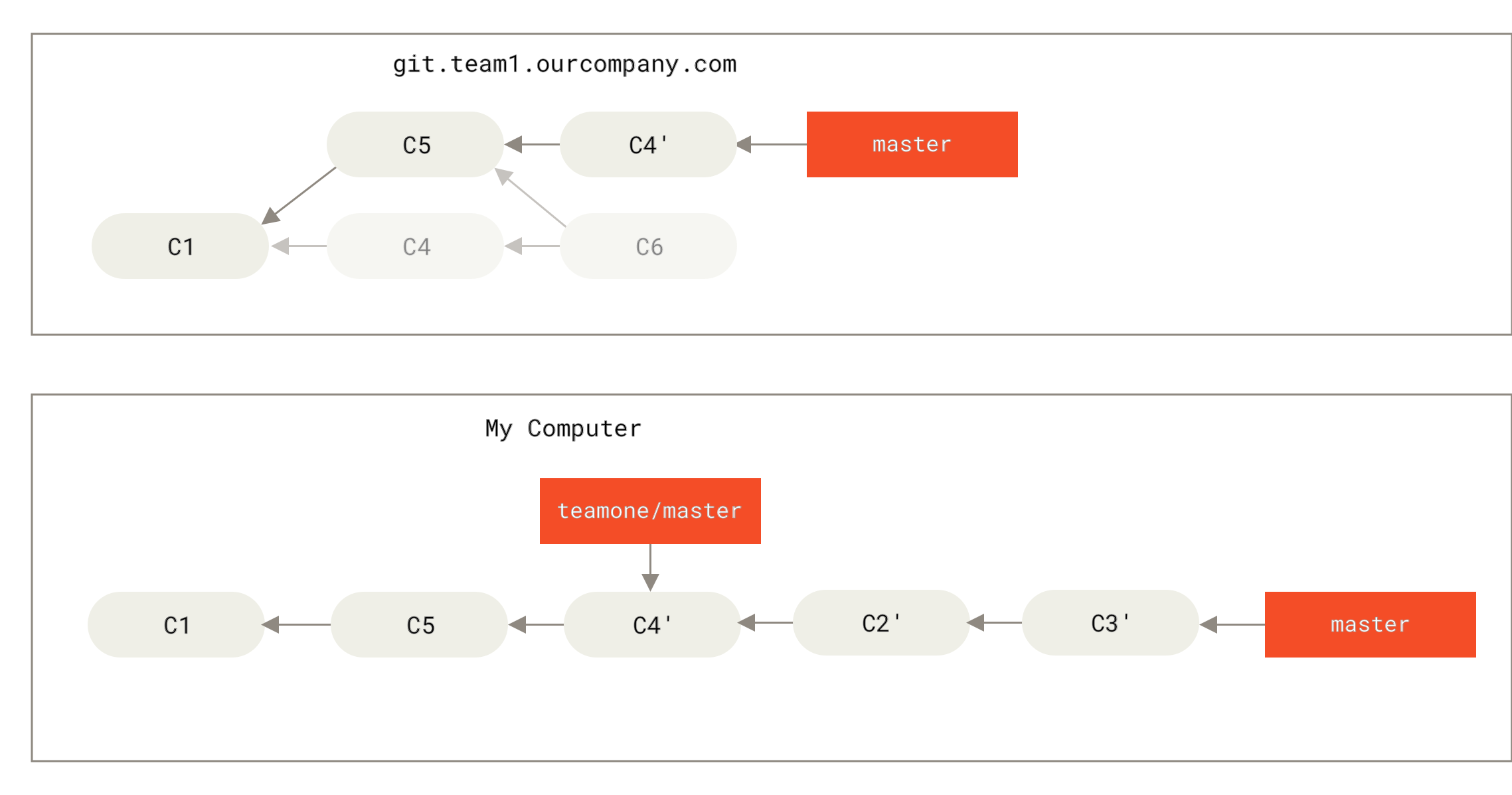
Sobald wir im vorhergehenden Szenario, beispielsweise bei Jemand lädt Commits nach einem Rebase hoch und verwirft damit Commits, auf denen deine Arbeit basiert, die Anweisung git rebase teamone/master ausführen, anstatt ein Merge durchzuführen, dann wird Git:
-
bestimmen, welche Änderungen an unserem Branch einmalig sind (
C2,C3,C4,C6,C7), -
bestimmen, welche der Commits keine Merge-Commits sind (
C2,C3,C4), -
bestimmen, welche Commits nicht neu in den Zielbranch geschrieben wurden (nur
C2undC3, daC4der selbe Patch wieC4'ist), und -
diese Commits am Ende des
teamone/masterBranches anwenden.
Statt des Ergebnisses, welches wir in Du lässt die Änderungen nochmals in dieselbe Arbeit einfließen in einen neuen Merge-Commit sehen, würden wir etwas erhalten, was eher wie Rebase am Ende von Änderungen eines „force-pushed“-Rebase aussieht.
Das funktioniert nur, wenn es sich bei C4 und C4', welche dein Teamkollege erstellt hat, um fast genau denselben Patch handelt.
Andernfalls kann das rebase nicht erkennen, dass es sich um ein Duplikat handelt und fügt einen weiteren, dem Patch C4 ähnlichen, hinzu (der wahrscheinlich nicht sauber angewendet werden kann, da die Änderungen bereits vollständig oder zumindest teilweise vorhanden sind).
Du kannst das auch vereinfachen, indem du ein git pull --rebase anstelle eines normalen git pull verwendest.
Oder du kannst es manuell mit einem git fetch machen, in diesem Fall gefolgt von einem git rebase teamone/master.
Wenn du git pull benutzt und --rebase zur Standardeinstellung machen willst, kannst du den pull.rebase Konfigurationswert mit etwas wie git config --global pull.rebase true einstellen.
Wenn du nur Commits rebased, die noch nie deinen eigenen Computer verlassen haben, ist alles in Ordnung. Wenn du Commits, die gepusht wurden, aber niemand sonst hat, basierend auf den Commits, rebased, wird auch alles in Ordnung sein. Wenn du Commits rebased, die gepusht wurden, auf denen aber keine Commits von jemand anderen basieren, ist auch alles in Ordnung. Wenn du Commits, die bereits veröffentlicht wurden, rebased und die Arbeit anderer Leute basiert auf diese Commits, dann könntest du Probleme bekommen und von deinen Teamkollegen verhöhnt werden.
Wenn du oder ein Partner es irgendwann für unbedingt notwendig halten, stelle sicher, dass jeder weiß, dass er anschließend git pull --rebase laufen lassen muss. So kann man versuchen, den Schaden einzugrenzen, nachdem er passiert ist.
Rebase vs. Merge
Nachdem du jetzt Rebasing und Merging in Aktion erlebt hast, fragst du dich vielleicht, welches davon besser ist. Bevor wir das beantworten können, lass uns ein klein wenig zurückblicken und darüber reden, was Historie bedeutet.
Ein Standpunkt ist, dass der Commit-Verlauf deines Repositorys eine Aufzeichnung davon ist, was wirklich passiert ist. Es ist ein wertvolles Dokument, das nicht manipuliert werden sollte. Aus diesem Blickwinkel ist das Ändern der Commit-Historie fast schon blasphemisch. Man belügt sich über das, was tatsächlich passiert ist. Was wäre, wenn es eine verwirrende Reihe von Merge-Commits gäbe? So ist es nun mal passiert, und das Repository sollte das für die Nachwelt beibehalten.
Der entgegengesetzte Standpunkt ist, dass der Commit-Verlauf den Verlauf deines Projekts darstellt.
Du würdest den ersten Entwurf eines Buches niemals veröffentlichen, warum also deine unordentliche Arbeit?
Wenn du an einem Projekt arbeitest, benötigst du möglicherweise eine Aufzeichnung all deiner Fehltritte und Sackgassen. Wenn es jedoch an der Zeit ist, deine Arbeit der Welt zu zeigen, möchtest du möglicherweise eine kohärentere Geschichte darüber erzählen, wie du von A nach B gekommen bist.
Die Leute in diesem Camp verwenden Tools wie Rebase und Filter-Branch, um ihre Commits neu zu schreiben, bevor sie in den Haupt-Branch integriert werden.
Sie verwenden Tools wie Rebase und Filter-Branch, um die Geschichte so zu erzählen, wie es für zukünftige Leser am besten ist.
Nun zur Frage, ob Mergen oder Rebasen besser ist. Wie so oft, ist diese Frage nicht so leicht zu beantworten. Git ist ein mächtiges Werkzeug und ermöglicht es dir, viele Dinge mit deinem Verlauf anzustellen. Aber jedes Team und jedes Projekt ist anders. Jetzt, da du weißt, wie diese beiden Möglichkeiten funktionieren, liegt es an dir, zu entscheiden, welche für deine Situation die Beste ist.
Für gewöhnlich lassen sich die Vorteile von beiden Techniken nutzen: Rebase lokale Änderungen vor einem Push, um deinen Verlauf zu bereinigen, aber rebase niemals etwas, das du bereits gepusht hast.