
-
1. Pierwsze kroki
- 1.1 Wprowadzenie do kontroli wersji
- 1.2 Krótka historia Git
- 1.3 Podstawy Git
- 1.4 Linia poleceń
- 1.5 Instalacja Git
- 1.6 Wstępna konfiguracja Git
- 1.7 Uzyskiwanie pomocy
- 1.8 Podsumowanie
-
2. Podstawy Gita
- 2.1 Pierwsze repozytorium Gita
- 2.2 Rejestrowanie zmian w repozytorium
- 2.3 Podgląd historii rewizji
- 2.4 Cofanie zmian
- 2.5 Praca ze zdalnym repozytorium
- 2.6 Tagowanie
- 2.7 Aliasy
- 2.8 Podsumowanie
-
3. Gałęzie Gita
- 3.1 Czym jest gałąź
- 3.2 Podstawy rozgałęziania i scalania
- 3.3 Zarządzanie gałęziami
- 3.4 Sposoby pracy z gałęziami
- 3.5 Gałęzie zdalne
- 3.6 Zmiana bazy
- 3.7 Podsumowanie
-
4. Git na serwerze
- 4.1 Protokoły
- 4.2 Uruchomienie Git na serwerze
- 4.3 Generowanie Twojego publicznego klucza SSH
- 4.4 Konfigurowanie serwera
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Inne opcje hostowania przez podmioty zewnętrzne
- 4.10 Podsumowanie
-
5. Rozproszony Git
-
6. GitHub
-
7. Narzędzia Gita
- 7.1 Wskazywanie rewizji
- 7.2 Interaktywne używanie przechowali
- 7.3 Schowek i czyszczenie
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Przepisywanie historii
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugowanie z Gitem
- 7.11 Moduły zależne
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Podsumowanie
-
8. Dostosowywanie Gita
- 8.1 Konfiguracja Gita
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git i inne systemy
- 9.1 Git jako klient
- 9.2 Migracja do Gita
- 9.3 Podsumowanie
-
10. Mechanizmy wewnętrzne w Git
- 10.1 Komendy typu plumbing i porcelain
- 10.2 Obiekty Gita
- 10.3 Referencje w Git
- 10.4 Spakowane pliki (packfiles)
- 10.5 Refspec
- 10.6 Protokoły transferu
- 10.7 Konserwacja i odzyskiwanie danych
- 10.8 Environment Variables
- 10.9 Podsumowanie
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
1.1 Pierwsze kroki - Wprowadzenie do kontroli wersji
Ten rozdział poświęcony jest pierwszym krokom z Git. Rozpoczyna się krótkim wprowadzeniem do narzędzi kontroli wersji, następnie przechodzi do instalacji i początkowej konfiguracji Git. Po przeczytaniu tego rozdziału powinieneś rozumieć w jakim celu Git został stworzony, dlaczego warto z niego korzystać oraz być przygotowany do używania go.
Wprowadzenie do kontroli wersji
Czym jest kontrola wersji i dlaczego powinieneś się nią przejmować? System kontroli wersji śledzi wszystkie zmiany dokonywane na pliku (lub plikach) i umożliwia przywołanie dowolnej wcześniejszej wersji. Przykłady w tej książce będą śledziły zmiany w kodzie źródłowym, niemniej w ten sam sposób można kontrolować praktycznie dowolny typ plików.
Jeśli jesteś grafikiem lub projektantem WWW i chcesz zachować każdą wersję pliku graficznego lub układu witryny WWW (co jest wysoce prawdopodobne), to używanie systemu kontroli wersji (VCS-Version Control System) jest bardzo rozsądnym rozwiązaniem. Pozwala on przywrócić plik(i) do wcześniejszej wersji, odtworzyć stan całego projektu, porównać wprowadzone zmiany, dowiedzieć się kto jako ostatnio zmodyfikował część projektu powodującą problemy, kto i kiedy wprowadził daną modyfikację. Oprócz tego używanie VCS oznacza, że nawet jeśli popełnisz błąd lub stracisz część danych, naprawa i odzyskanie ich powinno być łatwe. Co więcej, wszystko to można uzyskać całkiem niewielkim kosztem.
Lokalne systemy kontroli wersji
Dla wielu ludzi preferowaną metodą kontroli wersji jest kopiowanie plików do innego katalogu (może nawet oznaczonego datą, jeśli są sprytni). Takie podejście jest bardzo częste ponieważ jest wyjątkowo proste, niemniej jest także bardzo podatne na błędy. Zbyt łatwo zapomnieć w jakim jest się katalogu i przypadkowo zmodyfikować błędny plik lub skopiować nie te dane.
Aby poradzić sobie z takimi problemami, programiści już dość dawno temu stworzyli lokalne systemy kontroli wersji, które składały się z prostej bazy danych w której przechowywane były wszystkie zmiany dokonane na śledzonych plikach (por. Rysunek 1-1).
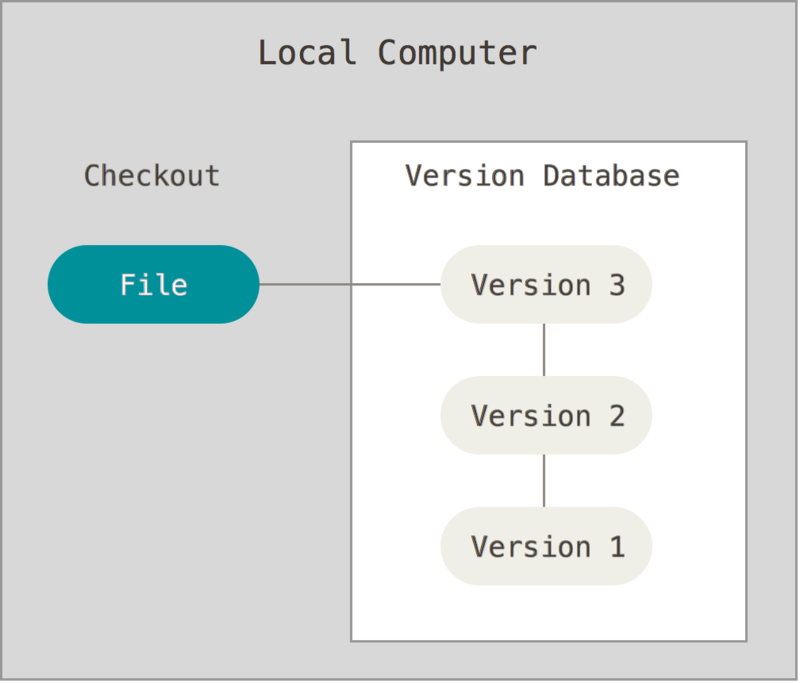
Jednym z najbardziej popularnych narzędzi VCS był system rcs, który wciąż jest obecny na wielu dzisiejszych komputerach. Nawet w popularnym systemie operacyjnym Mac OS X rcs jest dostępny po zainstalowaniu Narzędzi Programistycznych (Developer Tools). Program ten działa zapisując, w specjalnym formacie na dysku, dane różnicowe (to jest zawierające jedynie różnice pomiędzy plikami) z każdej dokonanej modyfikacji. Używając tych danych jest w stanie przywołać stan pliku z dowolnego momentu.
Scentralizowane systemy kontroli wersji
Kolejnym poważnym problemem z którym można się spotkać jest potrzeba współpracy w rozwoju projektu z odrębnych systemów. Aby poradzić sobie z tym problemem stworzono scentralizowane systemy kontroli wersji (CVCS - Centralized Version Control System). Systemy takie jak CVS, Subversion czy Perforce składają się z jednego serwera, który zawiera wszystkie pliki poddane kontroli wersji, oraz klientów którzy mogą się z nim łączyć i uzyskać dostęp do najnowszych wersji plików. Przez wiele lat był to standardowy model kontroli wersji (por. Rysunek 1-2).
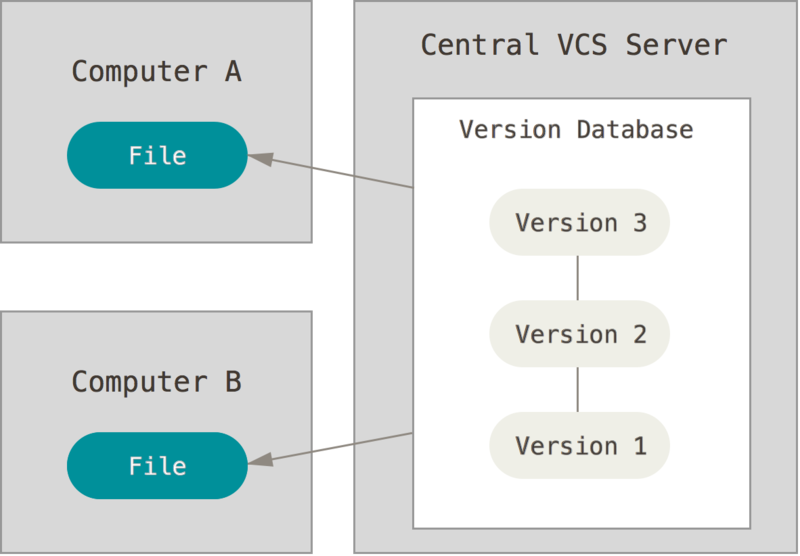
Taki schemat posiada wiele zalet, szczególnie w porównaniu z VCS. Dla przykładu każdy może się zorientować co robią inni uczestnicy projektu. Administratorzy mają dokładną kontrolę nad uprawnieniami poszczególnych użytkowników. Co więcej systemy CVCS są także dużo łatwiejsze w zarządzaniu niż lokalne bazy danych u każdego z klientów.
Niemniej systemy te mają także poważne wady. Najbardziej oczywistą jest problem awarii centralnego serwera. Jeśli serwer przestanie działać na przykład na godzinę, to przez tę godzinę nikt nie będzie miał możliwości współpracy nad projektem, ani nawet zapisania zmian nad którymi pracował. Jeśli dysk twardy na którym przechowywana jest centralna baza danych zostanie uszkodzony a nie tworzono żadnych kopii zapasowych, to można stracić absolutnie wszystko - całą historię projektu, może oprócz pojedynczych jego części zapisanych na osobistych komputerach niektórych użytkowników. Lokalne VCS mają ten sam problem - zawsze gdy cała historia projektu jest przechowywana tylko w jednym miejscu, istnieje ryzyko utraty większości danych.
Rozproszone systemy kontroli wersji
W ten sposób dochodzimy do rozproszonych systemów kontroli wersji (DVCS - Distributed Version Control System). W systemach DVCS (takich jak Git, Mercurial, Bazaar lub Darcs) klienci nie dostają dostępu jedynie do najnowszych wersji plików ale w pełni kopiują całe repozytorium. Gdy jeden z serwerów, używanych przez te systemy do współpracy, ulegnie awarii, repozytorium każdego klienta może zostać po prostu skopiowane na ten serwer w celu przywrócenia go do pracy (por. Rysunek 1-3).
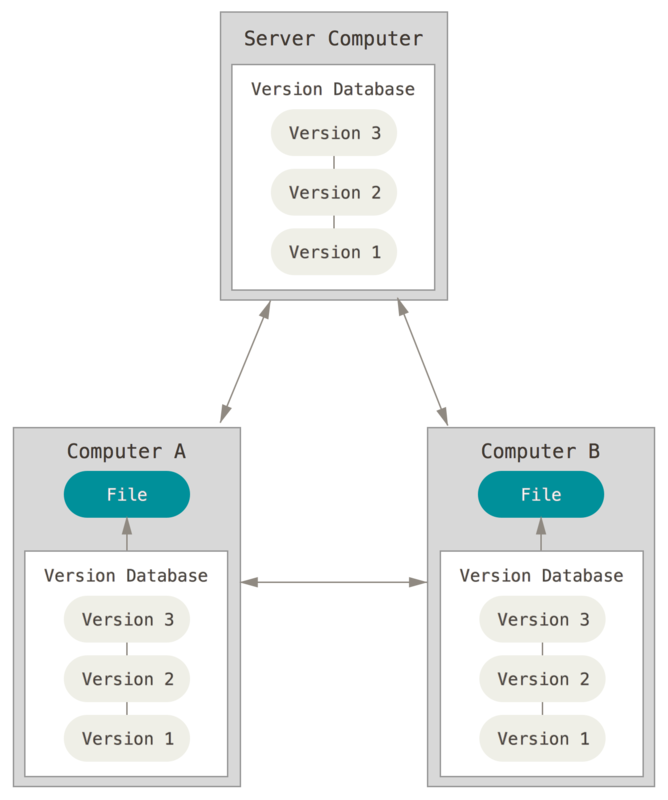
Co więcej, wiele z tych systemów dość dobrze radzi sobie z kilkoma zdalnymi repozytoriami, więc możliwa jest jednoczesna współpraca z różnymi grupami ludzi nad tym samym projektem. Daje to swobodę wykorzystania różnych schematów pracy, nawet takich które nie są możliwe w scentralizowanych systemach, na przykład modeli hierarchicznych.