
-
1. Aan de slag
- 1.1 Over versiebeheer
- 1.2 Een kort historisch overzicht van Git
- 1.3 Wat is Git?
- 1.4 De commando-regel
- 1.5 Git installeren
- 1.6 Git klaarmaken voor eerste gebruik
- 1.7 Hulp krijgen
- 1.8 Samenvatting
-
2. Git Basics
-
3. Branchen in Git
- 3.1 Branches in vogelvlucht
- 3.2 Eenvoudig branchen en mergen
- 3.3 Branch-beheer
- 3.4 Branch workflows
- 3.5 Branches op afstand (Remote branches)
- 3.6 Rebasen
- 3.7 Samenvatting
-
4. Git op de server
- 4.1 De protocollen
- 4.2 Git op een server krijgen
- 4.3 Je publieke SSH sleutel genereren
- 4.4 De server opzetten
- 4.5 Git Daemon
- 4.6 Slimme HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Hosting oplossingen van derden
- 4.10 Samenvatting
-
5. Gedistribueerd Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisie Selectie
- 7.2 Interactief stagen
- 7.3 Stashen en opschonen
- 7.4 Je werk tekenen
- 7.5 Zoeken
- 7.6 Geschiedenis herschrijven
- 7.7 Reset ontrafeld
- 7.8 Mergen voor gevorderden
- 7.9 Rerere
- 7.10 Debuggen met Git
- 7.11 Submodules
- 7.12 Bundelen
- 7.13 Vervangen
- 7.14 Het opslaan van inloggegevens
- 7.15 Samenvatting
-
8. Git aanpassen
- 8.1 Git configuratie
- 8.2 Git attributen
- 8.3 Git Hooks
- 8.4 Een voorbeeld van Git-afgedwongen beleid
- 8.5 Samenvatting
-
9. Git en andere systemen
- 9.1 Git als een client
- 9.2 Migreren naar Git
- 9.3 Samenvatting
-
10. Git Binnenwerk
- 10.1 Binnenwerk en koetswerk (plumbing and porcelain)
- 10.2 Git objecten
- 10.3 Git Referenties
- 10.4 Packfiles
- 10.5 De Refspec
- 10.6 Uitwisseling protocollen
- 10.7 Onderhoud en gegevensherstel
- 10.8 Omgevingsvariabelen
- 10.9 Samenvatting
-
A1. Bijlage A: Git in andere omgevingen
- A1.1 Grafische interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in Eclipse
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Samenvatting
-
A2. Bijlage B: Git in je applicaties inbouwen
- A2.1 Commando-regel Git
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Bijlage C: Git Commando’s
- A3.1 Setup en configuratie
- A3.2 Projecten ophalen en maken
- A3.3 Basic Snapshotten
- A3.4 Branchen en mergen
- A3.5 Projecten delen en bijwerken
- A3.6 Inspectie en vergelijking
- A3.7 Debuggen
- A3.8 Patchen
- A3.9 Email
- A3.10 Externe systemen
- A3.11 Beheer
- A3.12 Binnenwerk commando’s (plumbing commando’s)
5.3 Gedistribueerd Git - Het beheren van een project
Het beheren van een project
Naast weten hoe effectief bij te dragen aan een project, is het ook handig om te weten hoe je er een beheert.
Dit kan bestaan uit het accepteren en toepassen van patches die met format-patch gemaakt en naar je gemaild zijn, of het integreren van wijzigingen in de remote branches van repositories die je hebt toegevoegd als remotes van je project.
Of je nu een canonieke repository beheert, of wilt bijdragen door het controleren of goedkeuren van patches, je moet weten hoe werk te ontvangen op een manier die het duidelijkst is voor andere bijdragers en voor jou op langere termijn vol te houden.
Werken in topic branches
Als je overweegt om nieuw werk te integreren, is het over het algemeen een goed idee om het uit te proberen in een topic branch — een tijdelijke branch, speciaal gemaakt om dat nieuwe werk uit te proberen.
Op deze manier is het handig om een patch individueel te bewerken en het even opzij te zetten als het niet lukt, totdat je tijd hebt om er op terug te komen.
Als je een eenvoudige branchnaam maakt, gebaseerd op het onderwerp van het werk dat je aan het proberen bent, bijvoorbeeld ruby_client of iets dergelijks, dan is het makkelijk om te herinneren als je het voor een tijdje opzij legt en er later op terug komt.
De beheerder van het Git project heeft de neiging om deze branches ook van een naamsruimte (namespace) te voorzien — zoals sc/ruby_client, waarbij sc een afkorting is van de persoon die het werk heeft bijgedragen.
Zoals je je zult herinneren, kun je de branch gebaseerd op je master-branch zo maken:
$ git branch sc/ruby_client masterOf, als je er ook meteen naar wilt omschakelen, kun je de checkout -b optie gebruiken:
$ git checkout -b sc/ruby_client masterNu ben je klaar om het bijgedragen werk in deze topic branch toe te voegen, en te bepalen of je het wilt mergen in je meer permanente branches.
Patches uit e-mail toepassen
Als je een patch per e-mail ontvangt, en je moet die integreren in je project, moet je de patch in je topic branch toepassen om het te evalueren.
Er zijn twee manieren om een gemailde patch toe te passen: met git apply of met git am.
Een patch toepassen met apply
Als je de patch ontvangen hebt van iemand die het gegenereerd heeft met de git diff of een Unix diff commando (wat niet wordt aangeraden, zie de volgende paragraaf), kun je het toepassen met het git apply commando.
Aangenomen dat je de patch als /tmp/patch-ruby-client.patch opgeslagen hebt, kun je de patch als volgt toepassen:
$ git apply /tmp/patch-ruby-client.patchDit wijzigt de bestanden in je werk directory.
Het is vrijwel gelijk aan het uitvoeren van een patch -p1 commando om de patch toe te passen, alhoewel het meer paranoïde is en minder "fuzzy matches" accepteert dan patch.
Het handelt ook het toevoegen, verwijderen, en hernoemen van bestanden af als ze beschreven staan in het git diff formaat, wat patch niet doet.
Als laatste volgt git apply een “pas alles toe of laat alles weg” model waarbij alles of niets wordt toegepast.
Dit in tegenstelling tot patch die gedeeltelijke patches kan toepassen, waardoor je werkdirectory in een vreemde status achterblijft.
Over het algemeen is git apply terughoudender dan patch.
Het zal geen commit voor je aanmaken — na het uitvoeren moet je de geïntroduceerde wijzigingen handmatig stagen en committen.
Je kunt ook git apply gebruiken om te zien of een patch netjes kan worden toepast voordat je het echt doet — je kunt git apply --check uitvoeren met de patch:
$ git apply --check 0001-seeing-if-this-helps-the-gem.patch
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not applyAls er geen uitvoer is, dan zou de patch netjes moeten passen. Dit commando retourneert ook een niet-nul status als de controle faalt, zodat je het kunt gebruiken in scripts als je dat zou willen.
Een patch met am toepassen
Als de bijdrager een Git gebruiker is en zo vriendelijk is geweest om het format-patch commando te gebruiken om de patch te genereren, dan is je werk eenvoudiger omdat de patch de auteur-informatie en een commit-bericht voor je bevat.
Als het enigzins kan, probeer dan je bijdragers aan te moedigen om format-patch te gebruiken in plaats van diff om patches voor je te genereren.
Je zou alleen `git apply hoeven te gebruiken voor oude patches en dergelijke zaken.
Om een patch gegenereerd met format-patch toe te passen, gebruik je git am (het commando wordt am genoemd, omdat het wordt gebruikt om "een serie van patches toe te passen [apply] uit een mailbox".
Technisch is git am gemaakt om een mbox bestand te lezen, wat een eenvoudig gewone platte tekstformaat is om één of meer e-mail berichten in een tekstbestand op te slaan.
Het ziet er ongeveer zo uit:
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] add limit to log function
Limit log functionality to the first 20Dit is het begin van de uitvoer van het git format-patch commando dat je gezien hebt in de vorige paragraaf.
Dit is ook een geldig mbox e-mail formaat.
Als iemand jou de patch correct gemaild heeft door gebruik te maken van git send-email en je download dat in een mbox formaat, dan kan je git am naar dat mbox bestand verwijzen, en het zal beginnen met alle patches die het tegenkomt toe te passen.
Als je een mail client gebruikt die meerdere e-mails kan opslaan in mbox formaat, dan kun je hele reeksen patches in een bestand opslaan en dan git am gebruiken om ze één voor één toe te passen.
Maar, als iemand een patch bestand heeft geüpload die gegenereerd is met git format-patch naar een ticket systeem of zoiets, kun je het bestand lokaal opslaan en dan dat opgeslagen bestand aan git am doorgeven om het te applyen:
$ git am 0001-limit-log-function.patch
Applying: add limit to log functionJe ziet dat het netjes is toegepast, en automatisch een nieuwe commit voor je heeft aangemaakt.
De auteursinformatie wordt gehaald uit de From en Date velden in de kop van de e-mail, en het bericht van de commit wordt gehaald uit de Subject en de inhoud (voor de patch) van het mailbericht zelf.
Bijvoorbeeld, als deze patch was toegepast van het mbox voorbeeld hierboven, dan zou de gegenereerde commit er ongeveer zo uit zien:
$ git log --pretty=fuller -1 commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0 Author: Jessica Smith <jessica@example.com> AuthorDate: Sun Apr 6 10:17:23 2008 -0700 Commit: Scott Chacon <schacon@gmail.com> CommitDate: Thu Apr 9 09:19:06 2009 -0700 add limit to log function Limit log functionality to the first 20
De Commit informatie toont de persoon die de patch toegepast heeft en de tijd waarop het is toegepast.
De Author informatie toont de persoon die de patch oorspronkelijk gemaakt heeft en wanneer het gemaakt is.
Maar het is mogelijk dat de patch niet netjes toegepast kan worden.
Misschien is jouw hoofdbranch te ver afgeweken van de branch waarop de patch gebouwd is, of is de patch afhankelijk van een andere patch, die je nog niet hebt toegepast.
In dat geval zal het git am proces falen en je vragen wat je wilt doen:
$ git am 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Patch failed at 0001.
When you have resolved this problem run "git am --resolved".
If you would prefer to skip this patch, instead run "git am --skip".
To restore the original branch and stop patching run "git am --abort".Dit commando zet conflict markeringen in alle bestanden waar het problemen mee heeft, net zoals een conflicterende merge of rebase operatie.
Je lost dit probleem op een vergelijkbare manier op — wijzig het bestand om het conflict op te lossen, stage het bestand en voer dan git am --resolved uit om door te gaan met de volgende patch:
$ (fix the file)
$ git add ticgit.gemspec
$ git am --resolved
Applying: seeing if this helps the gemAls je wilt dat Git iets meer intelligentie toepast om het conflict op te lossen, kun je een -3 optie eraan meegeven, dit zorgt ervoor dat Git een driewegs-merge probeert.
Deze optie staat standaard niet aan omdat het niet werkt als de commit waarvan de patch zegt dat het op gebaseerd is niet in je repository zit.
Als je die commit wel hebt — als de patch gebaseerd was op een gepubliceerde commit — dan is de -3 over het algemeen veel slimmer in het toepassen van een conflicterende patch:
$ git am -3 0001-seeing-if-this-helps-the-gem.patch
Applying: seeing if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
No changes -- Patch already applied.In dit geval, zonder de -3 optie zou het als een conflict zijn beschouwd.
Omdat de de -3 optie gebruikt is, is de patch netjes toegepast.
Als je een aantal patches van een mbox toepast, kun je ook het am commando in een interactieve modus uitvoeren, wat bij iedere patch die het vindt stopt en je vraagt of je het wilt applyen:
$ git am -3 -i mbox
Commit Body is:
--------------------------
seeing if this helps the gem
--------------------------
Apply? [y]es/[n]o/[e]dit/[v]iew patch/[a]ccept allDit is prettig wanneer je een aantal patches opgespaard hebt, omdat je de patch eerst kunt zien als je je niet kunt herinneren wat het is, of de patch niet toepassen omdat je dat al eerder gedaan hebt.
Als alle patches voor je topic branch zijn toegepast en gecommit zijn op je branch, kan je besluiten of en hoe ze te integreren in een branch met een langere looptijd.
Remote branches uitchecken
Als je bijdrage van een Git gebruiker komt die zijn eigen repository opgezet heeft, een aantal patches daarin gepusht heeft, en jou de URL naar de repository gestuurd heeft en de naam van de remote branch waarin de wijzigingen zitten, kan je ze toevoegen als een remote en het mergen lokaal doen.
Bijvoorbeeld, als Jessica je een e-mail stuurt waarin staat dat ze een prachtig mooie nieuwe feature in de ruby-client-branch van haar repository heeft, kun je deze testen door de remote toe te voegen en die branch lokaal te bekijken:
$ git remote add jessica git://github.com/jessica/myproject.git
$ git fetch jessica
$ git checkout -b rubyclient jessica/ruby-clientAls ze je later opnieuw mailt met een andere branch die weer een andere mooie feature bevat, dan kun je die meteen ophalen (fetch) en bekijken (checkout) omdat je de remote al ingesteld hebt.
Dit is meest praktisch als je vaak met een persoon werkt. Als iemand eens in de zoveel tijd een enkele patch bij te dragen heeft, dan is het accepteren per mail misschien minder tijdrovend dan te eisen dat iedereen hun eigen server moet beheren, en daarna voortdurend remotes te moeten toevoegen en verwijderen voor die paar patches. Je zult daarbij waarschijnlijk ook niet honderden remotes willen hebben, elk voor iemand die maar een patch of twee bijdraagt. Aan de andere kant, scripts en gehoste diensten maken het wellicht eenvoudiger — het hangt sterk af van de manier waarop je ontwikkelt en hoe je bijdragers ontwikkelen.
Een bijkomend voordeel van deze aanpak is dat je de historie van de commits ook krijgt.
Alhoewel je misschien terechte merge-problemen hebt, weet je op welk punt in de historie hun werk is gebaseerd; een echte drieweg merge is de standaard in plaats van een -3 te moeten meegeven en hopen dat de patch gegenereerd was van een publieke commit waar je toegang toe hebt.
Als je maar af en toe met een persoon werkt, maar toch op deze manier van hen wilt pullen, dan kun je de URL van de remote repository geven aan het git pull commando.
Dit doet een eenmalig pull en bewaart de URL niet als een remote referentie:
$ git pull https://github.com/onetimeguy/project
From https://github.com/onetimeguy/project
* branch HEAD -> FETCH_HEAD
Merge made by the 'recursive' strategy.Bepalen wat geïntroduceerd is geworden
Je hebt een topic branch dat bijgedragen werk bevat. Nu kan je besluiten wat je er mee wilt doen. Deze paragraaf worden een aantal commando’s nogmaals behandeld om te laten zien hoe je ze kunt gebruiken om precies te reviewen wat je zult introduceren als je dit merged in je hoofd-branch.
Het is vaak handig om een overzicht te krijgen van alle commits die in deze branch zitten, maar die niet in je master-branch zitten.
Je kunt commits weglaten die al in de master branch zitten door de --not optie mee te geven voor de branch naam.
Dit doet hetzelfde als het master..contrib formaat dat we eerder gebruikt hebben.
Bijvoorbeeld, als je bijdrager je twee patches stuurt, je hebt een branch genaamd contrib gemaakt en hebt die patches daar toegepast, dan kun je dit uitvoeren:
$ git log contrib --not master
commit 5b6235bd297351589efc4d73316f0a68d484f118
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Oct 24 09:53:59 2008 -0700
seeing if this helps the gem
commit 7482e0d16d04bea79d0dba8988cc78df655f16a0
Author: Scott Chacon <schacon@gmail.com>
Date: Mon Oct 22 19:38:36 2008 -0700
updated the gemspec to hopefully work betterOm te zien welke wijzigingen door een commit worden geïntroduceerd, onthoud dan dat je de -p optie kunt meegeven aan git log en dan zal de geïntroduceerde diff bij elke commit erachter geplakt worden.
Om een volledige diff te zien van wat zou gebeuren als je deze topic branch merged met een andere branch, zul je misschien een vreemde truc moeten toepassen om de juiste resultaten te krijgen. Je zult misschien dit uit willen voeren:
$ git diff masterDit commando geeft je een diff, maar het kan misleidend zijn.
Als je master-branch vooruit geschoven is sinds je de topic branch er vanaf hebt gemaakt, dan zul je ogenschijnlijk vreemde resultaten krijgen.
Dit gebeurt omdat Git de snapshots van de laatste commit op de topic branch waar je op zit vergelijkt met de snapshot van de laatste commit op de master-branch.
Bijvoorbeeld, als je een regel in een bestand hebt toegevoegd op de master-branch, dan zal een directe vergelijking van de snapshots eruit zien alsof de topic branch die regel gaat verwijderen.
Als master een directe voorganger is van je topic branch is dit geen probleem, maar als de twee histories uitelkaar zijn gegaan, zal de diff eruit zien alsof je alle nieuwe spullen in je topic-branch toevoegt en al hetgeen wat alleen in de master-branch staat weghaalt.
Wat je eigenlijk had willen zien zijn de wijzigingen die in de topic branch zijn toegevoegd — het werk dat je zult introduceren als je deze branch met master merget. Je doet dat door Git de laatste commit op je topic branch te laten vergelijken met de eerste gezamenlijke voorouder die het heeft met de master-branch.
Technisch, kun je dat doen door de gezamenlijke voorouder op te zoeken en dan daar je diff op uit te voeren:
$ git merge-base contrib master
36c7dba2c95e6bbb78dfa822519ecfec6e1ca649
$ git diff 36c7dbof, beknopter:
$ git diff $(git merge-base contrib master)Echter, dat is niet handig, dus levert Git een andere verkorte manier om hetzelfde te doen: de driedubbele punt syntax.
In de context van het diff commando, kun je twee punten achter een andere branch zetten om een diff te doen tussen de laatste commit van de branch waar je op zit en de gezamenlijke voorouder met een andere branch:
$ git diff master..contribDit commando laat alleen het werk zien dat je huidige topic branch heeft geïntroduceerd sinds de gezamenlijke voorouder met master. Dat is een erg handige syntax om te onthouden.
Bijgedragen werk integreren
Als al het werk in je onderwerp branch klaar is om te worden geïntegreerd in een hogere branch, dan is de vraag hoe dat te doen. En daarbij, welke workflow wil je gebruiken om je project te beheren? Je hebt een aantal alternatieven, dus we zullen er een aantal behandelen.
Mergende workflows
Een eenvoudige workflow is om al dat werk direct in de master-branch te mergen.
In dit scenario heb je een master-branch die feitelijk de stabiele code bevat.
Als je werk in een topic branch hebt waaraan je gewerkt hebt, of dat iemand anders heeft bijgedragen en je hebt dat nagekeken, dan merge je het in de master branch, verwijdert de topic branch en herhaalt het proces.
Bijvoorbeeld, als we een repository hebben met werk in twee branches genaamd ruby_client en php_client, wat eruit ziet zoals Historie met een aantal topic branches. en mergen eerst ruby_client en daarna php_client, dan zal je historie er uit gaan zien zoals in Na het mergen van een topic branch..
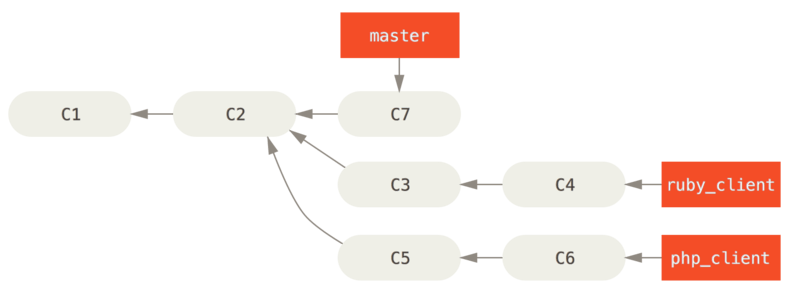
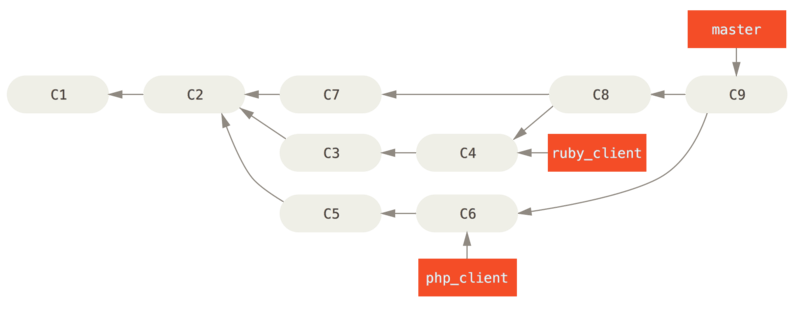
Dat is waarschijnlijk de eenvoudigste workflow, maar het wordt problematisch als je werkt met grotere of stabielere projecten waar je heel voorzichtig moet zijn met wat je introduceert.
Als je belangrijkere projecten hebt, zou je kunnen denken aan een twee-fasen merge cyclus.
In dit scenario heb je twee langlopende branches, master en develop, waarin je bepaalt dat master alleen wordt geupdate als een hele stabiele release wordt gemaakt en alle nieuwe code wordt geintegreerd in de develop-branch.
Je pusht beide branches regelmatig naar de publieke repository.
Elke keer heb je een nieuwe topic branch om in te mergen (Voor de merge van een topic branch.), je merget deze in develop (Na de merge van een topic branch.); daarna, als je een release tagt, fast-forward je master naar waar de nu stabiele develop-branch is (Na een project release.).
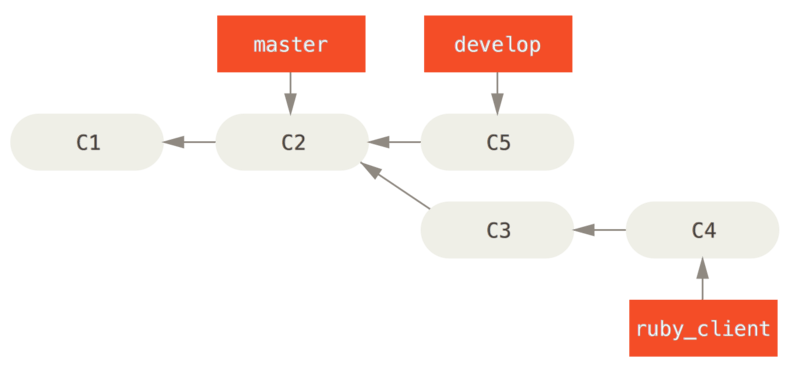
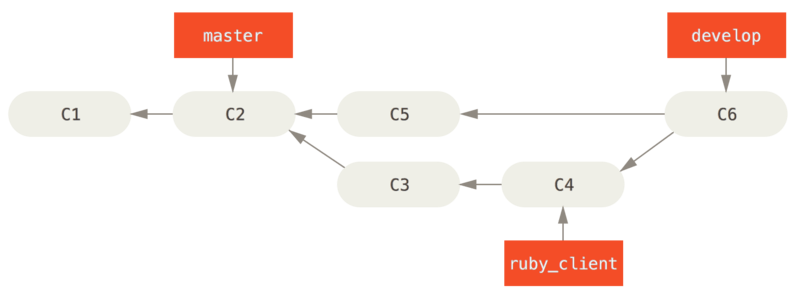
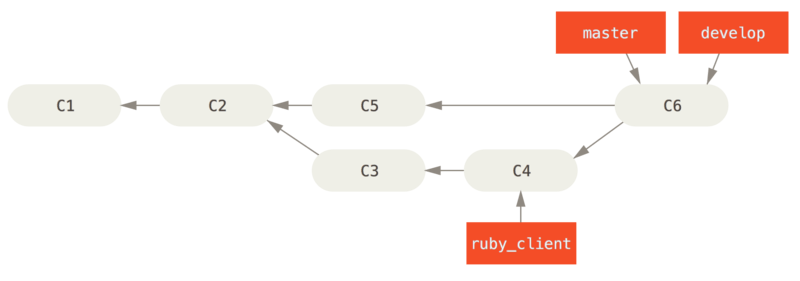
Op deze manier kunnen mensen, wanneer ze de repository van jouw project klonen, ervoor kiezen om je master uit te checken om de laatste stabiele versie te maken en eenvoudig up-to-date te blijven op die versie, of ze kunnen develop uitchecken, die het nieuweste materiaal bevat.
Je kunt dit concept ook doortrekken, en een intergrate-branch hebben waar al het werk wordt gemerged.
Dan, als de code op die branch stabiel is en de tests passeert, kan je dit op de develop-branch mergen, als dat dan enige tijd stabiel is gebleken kan je de master-branch fast-forwarden.
Workflows met grote merges
Het Git project heeft vier langlopende branches: master, next, en pu (proposed updates, voorgestelde wijzigingen) voor nieuw spul, en maint voor onderhoudswerk (maintenance backports).
Als nieuw werk wordt geïntroduceerd door bijdragers, wordt het samengeraapt in topic branches in de repository van de beheerder op een manier die lijkt op wat we omschreven hebben (zie Een complexe reeks van parallelle bijgedragen topic branches beheren.).
Hier worden de topics geëvalueerd om te bepalen of ze veilig zijn en klaar voor verdere verwerking of dat ze nog wat werk nodig hebben.
Als ze veilig zijn, worden ze in next gemerged, en wordt die branch gepusht zodat iedereen de geïntegreerde topics kan uitproberen.
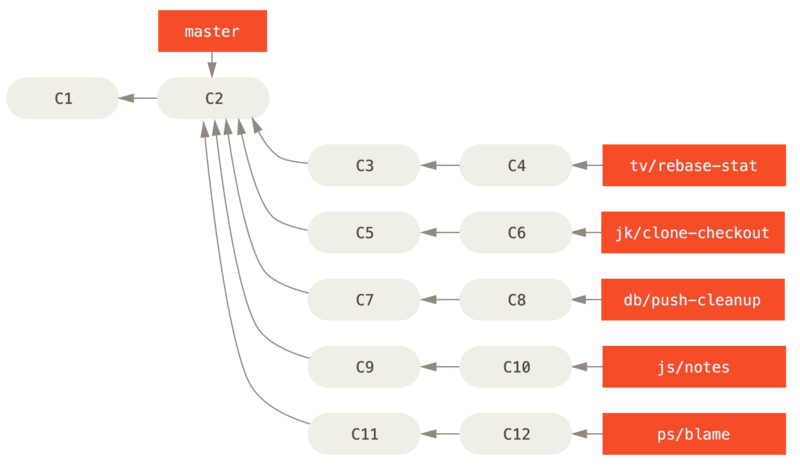
Als de topics nog werk nodig hebben, dan worden ze in plaats daarvan gemerged in pu.
Zodra vastgesteld is dat ze helemaal stabiel zijn, dan worden de topics opnieuw gemerged in master.
De next en pu-branches worden dan opnieuw opgebouwd vanaf de master.
Dit betekent dat master vrijwel altijd vooruit beweegt, next eens in de zoveel tijd gerebaset wordt, en pu nog vaker gerebaset wordt:
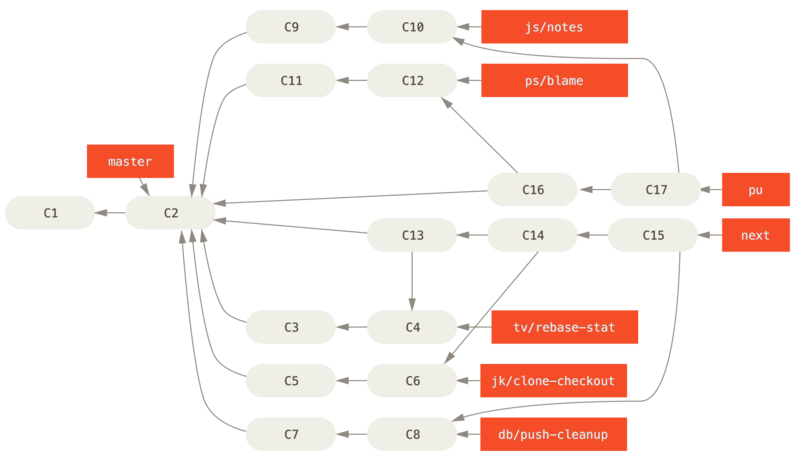
Als een topic branch uiteindelijk is gemerged in master, dan wordt het verwijderd van de repository.
Het Git project heeft ook een maint-branch, die geforkt is van de laatste release om teruggewerkte (backported) patches te leveren in het geval dat een onderhoudsrelease nodig is.
Dus als je de Git repository kloont, dan heb je vier branches die je kunt uitchecken om het project in verschillende stadia van ontwikkeling te evalueren, afhankelijk van hoe nieuw je alles wilt hebben of hoe je wil bijdragen; en de onderhouder heeft een gestructureerde workflow om nieuwe bijdragen aan de tand te voelen.
De workflow van het Git project is gespecialiseerd.
Om dit goed te begrijpen zou je het Git Beheerdersgids kunnen lezen.
Rebasende en cherry pick workflows
Andere beheerders geven de voorkeur aan rebasen of bijgedragen werk te cherry-picken naar hun master branch in plaats van ze erin te mergen, om een vrijwel lineaire historie te behouden.
Als je werk in een topic branch hebt en hebt besloten dat je het wil integreren, dan ga je naar die branch en voert het rebase commando uit om de wijzigingen op je huidige master branch te baseren (of develop, enzovoorts).
Als dat goed werkt, dan kun je de master-branch fast-forwarden, en eindig je met een lineaire project historie.
De andere manier om geïntroduceerd werk van de ene naar de andere branch te verplaatsen is om het te cherry-picken. Een cherry-pick in Git is een soort rebase voor een enkele commit. Het pakt de patch die was geïntroduceerd in een commit en probeert die weer toe te passen op de branch waar je nu op zit. Dit is handig als je een aantal commits op een topic branch hebt en je er slechts één van wilt integreren, of als je alleen één commit op een topic branch hebt en er de voorkeur aan geeft om het te cherry-picken in plaats van rebase uit te voeren. Bijvoorbeeld, stel dat je een project hebt dat eruit ziet als dit:
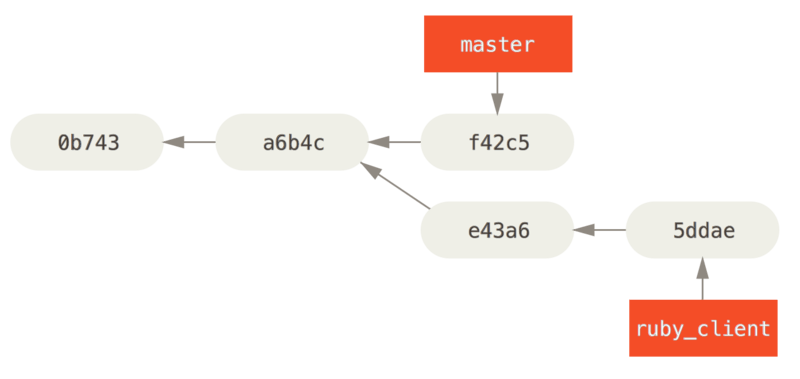
Als je commit e43a6 in je master branch wilt pullen, dan kun je dit uitvoeren
$ git cherry-pick e43a6
Finished one cherry-pick.
[master]: created a0a41a9: "More friendly message when locking the index fails."
3 files changed, 17 insertions(+), 3 deletions(-)Dit pullt dezelfde wijziging zoals geïntroduceerd in e43a6, maar je krijgt een nieuwe SHA-1 waarde, omdat de toepassingsdatum anders is.
Nu ziet je historie er zo uit:
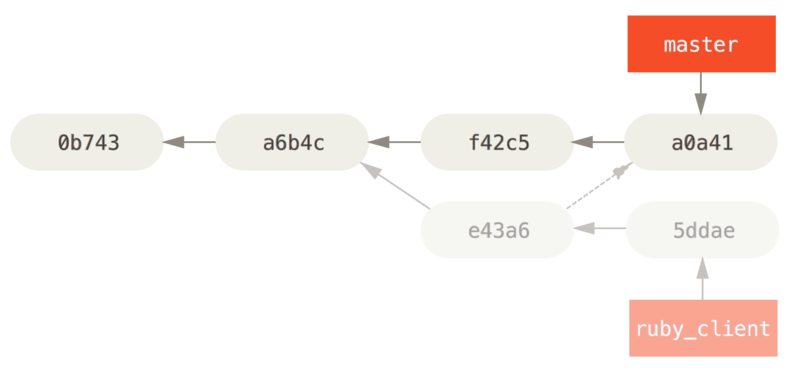
Nu kun je de topic branch verwijderen en de commits die je niet wilde pullen weggooien.
Rerere
Als je veel gaat mergen en rebasen, of als je een langlopende topic branch onderhoudt heeft Git een optie genaamd “rerere” die je kan helpen.
Rerere staat voor “hergebruik het opgeslagen besluit” (Reuse Recorded Resolution) - het is een manier om het andmatige conflict situatie oplossen in te korten. Als rerere is ingeschakeld, zal Git een reeks van ervoor- en erna-plaatjes van succesvolle merges bijhouden en als het opmerkt dat er een conflict is dat precies lijkt op een die je al opgelost hebt, zal het gewoon de oplossing van de vorige keer gebruiken, zonder je ermee lastig te vallen.
Deze optie komt in twee delen: een configuratie instelling en een commando.
De configuratie is een rerere.enabled instelling, en het is handig genoeg om in je globale configuratie te zetten:
$ git config --global rerere.enabled trueVanaf nu, elke keer als je een merge doet dat een conflict oplost, zal de oplossing opgeslagen worden in de cache voor het geval dat je het in de toekomst nodig gaat hebben.
Als het nodig is kan je interacteren met de rerere cache met het git rerere commando.
Als het op zich aangeroepen wordt, zal Git de database met oplossingen controleren en probeert een passende te vinden voor alle huidige merge conflicten en deze proberen op te lossen (alhoewel dit automatisch wordt gedaan als rerere .enabled op true is gezet).
Er zijn ook sub-commando’s om te zien wat er opgeslagen gaat worden, om specifieke oplossingen uit de cache te verwijderen, en om de gehele cache te legen.
We zullen rerere meer gedetailleerd behandelen in Rerere.
Je releases taggen
Als je hebt besloten om een release te maken, zul je waarschijnlijk een tag willen aanmaken zodat je die release op elk moment in de toekomst opnieuw kunt maken. Je kunt een nieuwe tag maken zoals ik heb beschreven in Git Basics. Als je besluit om de tag als de beheerder te tekenen, dan ziet het taggen er wellicht zo uit:
$ git tag -s v1.5 -m 'my signed 1.5 tag'
You need a passphrase to unlock the secret key for
user: "Scott Chacon <schacon@gmail.com>"
1024-bit DSA key, ID F721C45A, created 2009-02-09Als je tags tekent, dan heb je misschien een probleem om de publieke PGP sleutel, die gebruikt is om de tags te tekenen, te verspreiden.
De beheerder van het Git project heeft dit probleem opgelost door hun publieke sleutel als een blob in de repository mee te nemen en een tag te maken die direct naar die inhoud wijst.
Om dit te doen kun je opzoeken welke sleutel je wilt gebruiken door gpg --list-keys uit te voeren:
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 1024D/F721C45A 2009-02-09 [expires: 2010-02-09]
uid Scott Chacon <schacon@gmail.com>
sub 2048g/45D02282 2009-02-09 [expires: 2010-02-09]Daarna kun je de sleutel direct in de Git database importeren, door het te exporteren en te "pipen" naar git hash-object, wat een nieuwe blob schrijft in Git met die inhoud en je de SHA-1 van de blob teruggeeft:
$ gpg -a --export F721C45A | git hash-object -w --stdin
659ef797d181633c87ec71ac3f9ba29fe5775b92Nu je de inhoud van je sleutel in Git hebt, kun je een tag aanmaken die direct daarnaar wijst door de nieuw SHA-1 waarde die het hash-object commando je gaf te specificeren:
$ git tag -a maintainer-pgp-pub 659ef797d181633c87ec71ac3f9ba29fe5775b92Als je git push --tags uitvoert, zal de maintainer-pgp-pub tag met iedereen gedeeld worden.
Als iemand een tag wil verifiëren, dan kunnen ze jouw PGP sleutel direct importeren door de blob direct uit de database te halen en het in GPG te importeren:
$ git show maintainer-pgp-pub | gpg --importZe kunnen die sleutel gebruiken om al je getekende tags te verifiëren.
En als je instructies in het tag bericht zet, dan zal git show <tag> je eindgebruikers meer specifieke instructies geven over tag verificatie.
Een bouw nummer genereren
Omdat Git geen monotoon oplopende nummers heeft zoals v123 of iets gelijkwaardigs om bij iedere commit mee te worden genomen, en je een voor mensen leesbare naam wilt hebben bij een commit, kan je git describe uitvoeren op die commit.
Als antwoord geeft Git je een string met de naam van de dichtstbijzijnde tag voor die commit, gevolg door het aantal commits achter die tag en uiteindelijk gevolgd door een gedeeltelijke SHA-1 waarde van de commit die je omschrijft (vooraf gegaan door een "g" wat Git betekent):
$ git describe master
v1.6.2-rc1-20-g8c5b85cOp deze manier kun je een snapshot of "build" exporteren en het vernoemen naar iets dat begrijpelijk is voor mensen.
Sterker nog: als je Git, gekloont van de Git repository, vanaf broncode gebouwd hebt geeft git --version je iets dat er zo uitziet.
Als je een commit beschrijft die je direct getagged hebt, dan krijg je simpelweg de tag naam.
Het git describe commando geeft beschreven tags de voorkeur (tags gemaakt met de -a of -s vlag); als je ook gebruik wilt maken van lichtgewicht (niet beschreven) tags, voeg dan de optie --tags aan het commando toe.
Je kunt deze tekst ook gebruiken als het doel van een git checkout of git show commando, met de aantekening dat het afhankelijk is van de verkorte SHA-1 waarde aan het einde, dus het zou mogelijk niet voor altijd geldig blijven.
Als voorbeeld, de Linux kernel sprong recentelijk van 8 naar 10 karakters om er zeker van de zijn dat de SHA-1 uniek zijn, oudere git describe commando uitvoernamen werden daardoor ongeldig.
Een release voorbereiden
Nu wil je een build vrijgeven.
Een van de dingen die je wilt doen is een archief maken van de laatste snapshot van je code voor de arme stumperds die geen Git gebruiken.
Het commando om dit te doen is git archive:
$ git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
$ ls *.tar.gz
v1.6.2-rc1-20-g8c5b85c.tar.gzAls iemand die tarball opent, dan krijgen ze de laatste snapshot van je project onder een project directory.
Je kunt op vrijwel dezelfde manier ook een zip archief maken, maar dan door de format=zip optie mee te geven aan git archive:
$ git archive master --prefix='project/' --format=zip > `git describe master`.zipJe hebt nu een mooie tarball en een zip archief van je project release, die je kunt uploaden naar je website of naar mensen kunt e-mailen.
De shortlog
De tijd is gekomen om de maillijst met mensen die willen weten wat er gebeurt in je project te mailen.
Een prettige manier om een soort van wijzigingsverslag te krijgen van wat er is toegevoegd in je project sinds je laatste release of e-mail is om het git shortlog commando te gebruiken.
Het vat alle commits samen binnen de grenswaarden die je het geeft.
Het volgende, bijvoorbeeld, geeft je een samenvatting van alle commits sinds je vorige release, als je laatste release de naam v1.0.1 had:
$ git shortlog --no-merges master --not v1.0.1
Chris Wanstrath (6):
Add support for annotated tags to Grit::Tag
Add packed-refs annotated tag support.
Add Grit::Commit#to_patch
Update version and History.txt
Remove stray `puts`
Make ls_tree ignore nils
Tom Preston-Werner (4):
fix dates in history
dynamic version method
Version bump to 1.0.2
Regenerated gemspec for version 1.0.2Je krijgt een opgeschoonde samenvatting van alle commits sinds v1.0.1, gegroepeerd op auteur, die je naar je lijst kunt e-mailen.