
-
1. Erste Schritte
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches auf einen Blick
- 3.2 Einfaches Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Erstellung eines SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git-Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Von Drittanbietern gehostete Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisions-Auswahl
- 7.2 Interaktives Stagen
- 7.3 Stashen und Bereinigen
- 7.4 Deine Arbeit signieren
- 7.5 Suchen
- 7.6 Den Verlauf umschreiben
- 7.7 Reset entzaubert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debuggen mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Replace (Ersetzen)
- 7.14 Anmeldeinformationen speichern
- 7.15 Zusammenfassung
-
8. Git einrichten
- 8.1 Git Konfiguration
- 8.2 Git-Attribute
- 8.3 Git Hooks
- 8.4 Beispiel für Git-forcierte Regeln
- 8.5 Zusammenfassung
-
9. Git und andere VCS-Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git Interna
-
A1. Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Schnittstellen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
A2. Anhang B: Git in deine Anwendungen einbetten
- A2.1 Die Git-Kommandozeile
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Anhang C: Git Kommandos
- A3.1 Setup und Konfiguration
- A3.2 Projekte importieren und erstellen
- A3.3 Einfache Snapshot-Funktionen
- A3.4 Branching und Merging
- A3.5 Projekte gemeinsam nutzen und aktualisieren
- A3.6 Kontrollieren und Vergleichen
- A3.7 Debugging
- A3.8 Patchen bzw. Fehlerkorrektur
- A3.9 E-mails
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Basisbefehle
5.3 Verteiltes Git - Ein Projekt verwalten
Ein Projekt verwalten
Du musst nicht nur wissen, wie du effektiv zu einem Projekt etwas beitragen kannst. Du solltest auch wissen, wie du ein Projekt verwaltest.
Du musst bspw. wissen wie du Patches akzeptierst und anwendest, die über format-patch generiert und per E-Mail an dich gesendet wurden. Weiterhin solltest du wissen, wie du Änderungen in Remote-Branches für Repositorys integrierst, die du als Remotes zu deinem Projekt hinzugefügt hast.
Unabhängig davon, ob du ein zentrales Repository verwalten oder durch Überprüfen oder Genehmigen von Patches helfen möchtest, musst du wissen, wie du die Arbeit Anderer so akzeptierst, dass es für andere Mitwirkende transparent und auf lange Sicht auch nachhaltig ist.
Arbeiten in Featurebranches
Wenn man vorhat, neuen Code zu integrieren, ist es im Allgemeinen eine gute Idee, diesen in einem Feature Branch zu testen. Das ist ein temporärer Branch, der speziell zum Ausprobieren dieser neuen Änderungen erstellt wurde.
Auf diese Weise ist es einfach, einen Patch einzeln zu optimieren und ihn nicht weiter zu bearbeiten, wenn er nicht funktioniert, bis du wieder Zeit hast, dich wieder damit zu befassen.
Du solltest einen einfachen Branchnamen erstellen, der auf dem Thema der Arbeit basiert, die du durchführst, wie z.B. ruby_client oder etwas ähnlich Aussagekräftiges. Dann kannst du dich später leichter daran erinnern, falls du den Branch für eine Weile hast ruhen lassen und später daran weiter arbeitest.
Der Betreuer des Git-Projekts neigt auch dazu, diese Branches mit einem Namespace zu versehen – wie z. B. sc/ruby_client, wobei sc für die Person steht, die die Arbeit beigesteuert hat.
Wie du dich erinnerst, kannst du den Branch basierend auf deinem master Branch wie folgt erstellen:
$ git branch sc/ruby_client masterWenn du anschließend sofort zum neuen Branch wechseln möchtest, kannst du auch die Option checkout -b verwenden:
$ git checkout -b sc/ruby_client masterJetzt kannst du die getätigte Arbeit zu diesem Branch hinzufügen und festlegen, ob du ihn mit deinen bestehenden Branches zusammenführen möchtest.
Integrieren von Änderungen aus E-Mails
Wenn du einen Patch per E-Mail erhältst, den du in deinem Projekt integrieren möchtest, musst du den Patch in deinem Feature Branch einfließen lassen, damit du ihn prüfen kannst.
Es gibt zwei Möglichkeiten, einen per E-Mail versendeten Patch anzuwenden: mit git apply oder mit git am.
Änderungen mit apply integrieren
Wenn du den Patch von jemandem erhalten hast, der ihn mit git diff oder mit einer Variante des Unix-Befehls diff erzeugt hat (was nicht empfohlen wird; siehe nächster Abschnitt), kannst du ihn mit dem Befehl git apply integrieren.
Angenommen du hast den Patch unter /tmp/patch-ruby-client.patch gespeichert. Dann kannst du den Patch folgendermaßen integrieren:
$ git apply /tmp/patch-ruby-client.patchHierdurch werden die Dateien in deinem Arbeitsverzeichnis geändert.
Es ist fast identisch mit dem Ausführen eines patch -p1 Befehls zum Anwenden des Patches, obwohl es vorsichtiger ist und unscharfe Übereinstimmungen selektiver als patch akzeptiert.
Damit kann man auch Dateien Hinzufügen, Löschen und Umbenennen, wenn diese im git diff Format beschrieben sind, was mit patch nicht möglich ist.
Zu guter Letzt ist git apply ein „wende alles oder nichts an“ Modell, bei dem entweder alles oder nichts übernommen wird. patch hingegen integriert Patchdateien eventuell nur teilweise und kann dein Arbeitsverzeichnis in einem undefinierten Zustand versetzen.
git apply ist insgesamt sehr viel konservativer als patch.
Es wird kein Commit erstellen. Nach dem Ausführen musst du die eingeführten Änderungen manuell bereitstellen und comitten.
Du kannst git apply verwenden, um zu prüfen, ob ein Patch ordnungsgemäß integriert werden kann, bevor du versuchst, ihn tatsächlich anzuwenden. Du kannst git apply --check auf den Patch ausführen:
$ git apply --check 0001-see-if-this-helps-the-gem.patch
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not applyWenn keine Ausgabe erfolgt, sollte der Patch ordnungsgemäß angewendet werden können. Dieser Befehl wird auch mit einem Rückgabewert ungleich Null beendet, wenn die Prüfung fehlschlägt. So kannst du ihn bei Bedarf in Skripten verwenden.
Änderungen mit am integrieren
Wenn der Beitragende ein Git-Benutzer ist und den Befehl format-patch zum Generieren seines Patches verwendet hat, ist deine Arbeit einfacher. Der Patch enthält bereits Informationen über den Autor und eine entsprechende Commitnachricht.
Wenn möglich, ermutige die Beitragenden format-patch anstelle von diff zum Erstellen von Patches zu verwenden.
Du solltest git apply nur für ältere Patches und ähnliche Dinge verwenden.
Um einen von format-patch erzeugten Patch zu integrieren, verwende git am (der Befehl heißt am, da er verwendet wird, um „eine Reihe von Patches aus einer Mailbox anzuwenden“).
Technisch gesehen ist git am so aufgebaut, dass eine mbox-Datei gelesen werden kann. Hierbei handelt es sich um ein einfaches Nur-Text-Format zum Speichern einer oder mehrerer E-Mail-Nachrichten in einer Textdatei.
Das sieht in etwa so aus:
From 330090432754092d704da8e76ca5c05c198e71a8 Mon Sep 17 00:00:00 2001
From: Jessica Smith <jessica@example.com>
Date: Sun, 6 Apr 2008 10:17:23 -0700
Subject: [PATCH 1/2] Add limit to log function
Limit log functionality to the first 20Dies ist der Anfang der Ausgabe des Befehls git format-patch, den du im vorherigen Abschnitt gesehen hast. Es zeigt ein gültiges mbox Email Format.
Wenn dir jemand den Patch ordnungsgemäß mit git send-email per E-Mail zugesendet hat und du ihn in ein mbox-Format herunterlädst, kannst du git am auf diese mbox-Datei ausführen. Damit werden alle angezeigten Patches entsprechend angewendet.
Wenn du einen Mail-Client ausführst, der mehrere E-Mails im Mbox-Format speichern kann, kannst du ganze Patch-Serien in einer Datei speichern. Diese können anschließend mit git am einzeln angewendet werden.
Wenn jemand eine mit git format-patch erzeugte Patch-Datei in ein Ticketsystem oder ähnliches hochgeladen hat, kannst du die Datei lokal speichern. Die Datei kannst du dann an git am übergeben, um sie zu integrieren:
$ git am 0001-limit-log-function.patch
Applying: Add limit to log functionWie du sehen kannst, wurde der Patch korrekt integriert und es wurde automatisch ein neuer Commit für dich erstellt.
Die Autoreninformationen werden aus den Kopfzeilen From und Date der E-Mail entnommen und die Commitnachricht wird aus dem Subject und dem Textkörper (vor dem Patch) der E-Mail entnommen.
Wenn dieser Patch bspw. aus dem obigen mbox-Beispiel angewendet würde, würde der erzeugte Commit in etwa so aussehen:
$ git log --pretty=fuller -1
commit 6c5e70b984a60b3cecd395edd5b48a7575bf58e0
Author: Jessica Smith <jessica@example.com>
AuthorDate: Sun Apr 6 10:17:23 2008 -0700
Commit: Scott Chacon <schacon@gmail.com>
CommitDate: Thu Apr 9 09:19:06 2009 -0700
Add limit to log function
Limit log functionality to the first 20Die Commit Informationen gibt die Person an, die den Patch angewendet hat und den Zeitpunkt, wann er angewendet wurde.
Die Author Information gibt die Person an, die den Patch ursprünglich erstellt hat und wann er ursprünglich erstellt wurde.
Es besteht jedoch die Möglichkeit, dass der Patch nicht sauber angewendet werden kann.
Möglicherweise ist dein Hauptbranch zu weit vom Branch entfernt, von dem aus der Patch erstellt wurde. Oder aber der Patch hängt noch von einem anderen Patch ab, den du noch nicht angewendet hast.
In diesem Fall schlägt der Prozess git am fehl und du wirst gefragt, was du tun möchtest:
$ git am 0001-see-if-this-helps-the-gem.patch
Applying: See if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Patch failed at 0001.
When you have resolved this problem run "git am --resolved".
If you would prefer to skip this patch, instead run "git am --skip".
To restore the original branch and stop patching run "git am --abort".Dieser Befehl fügt Konfliktmarkierungen in alle Dateien ein, in denen Probleme auftreten. Ähnlich wie bei einem Konflikt bei der Zusammenführung (engl. merge) bzw. bei der Reorganisation (engl. rebase).
Du löst dieses Problem auf die gleiche Art: Bearbeite die Datei, um den Konflikt zu lösen. Anschließend füge die neue Datei der Staging-Area hinzu und führe dann git am --resolved aus, um mit dem nächsten Patch fortzufahren:
$ (fix the file)
$ git add ticgit.gemspec
$ git am --resolved
Applying: See if this helps the gemWenn du möchtest, dass Git den Konflikt etwas intelligenter löst, kannst du ihm die Option „-3“ übergeben, wodurch Git versucht, eine Drei-Wege-Merge durchzuführen. Diese Option ist standardmäßig nicht aktiviert, da sie nicht funktioniert, wenn sich der Commit, auf dem der Patch basiert, nicht in deinem Repository befindet. Wenn du diesen Commit hast – wenn der Patch auf einem öffentlichen Commit basiert -, ist die Option „-3“ im Allgemeinen viel intelligenter beim Anwenden eines Patch mit Konflikten:
$ git am -3 0001-see-if-this-helps-the-gem.patch
Applying: See if this helps the gem
error: patch failed: ticgit.gemspec:1
error: ticgit.gemspec: patch does not apply
Using index info to reconstruct a base tree...
Falling back to patching base and 3-way merge...
No changes -- Patch already applied.In diesem Fall wäre der Patch ohne die Option -3 als Konflikt gewertet worden.
Da die Option -3 verwendet wurde, konnte der Patch sauber angewendet werden.
Wenn du mehrere Patches aus mbox anwendest, kannst du auch den Befehl am im interaktiven Modus ausführen. Bei jedem gefundenen Patch wird angehalten und du wirst gefragt, ob du ihn anwenden möchtest:
$ git am -3 -i mbox
Commit Body is:
--------------------------
See if this helps the gem
--------------------------
Apply? [y]es/[n]o/[e]dit/[v]iew patch/[a]ccept allDies ist hilfreich, wenn du eine Reihe von Patches gespeichert hast. Du kannst dir den Patch anzeigen lassen, wenn du dich nicht daran erinnerst, worum es genau geht. Oder du wendest den Patch nicht an, weil du es bereits getan hast.
Wenn alle Patches für dein Feature angewendet und in deinem Branch committet wurden, kannst du auswählen, ob und wie du sie in einen Hauptbranch integrieren möchtest.
Remote Branches auschecken
Wenn du einen Beitrag von einem Git-Nutzer erhältst, der sein eigenes Repository eingerichtet, eine Reihe von Änderungen vorgenommen und dir dann die URL zum Repository und den Namen des Remote-Branchs gesendet hat, in dem sich die Änderungen befinden, dann kannst du diesen als remote hinzufügen und die Änderungen lokal zusammenführen.
Wenn Jessica dir bspw. eine E-Mail sendet, die besagt, dass sie eine großartige neue Funktion im ruby-client Branch ihres Repositorys hat, kannst du diese testen, indem du den Branch als remote hinzufügst und ihn lokal auscheckst:
$ git remote add jessica https://github.com/jessica/myproject.git
$ git fetch jessica
$ git checkout -b rubyclient jessica/ruby-clientWenn Jessica dir später erneut eine E-Mail mit einem anderen Branch sendet, der eine weitere großartige Funktion enthält, kannst du diese direkt abrufen und auschecken, da du bereits über das Remote Repository verfügst.
Dies ist vor allem dann nützlich, wenn du durchgängig mit einer Person arbeitest. Wenn jemand nur selten einen Patch empfängt, ist das Akzeptieren über E-Mail möglicherweise weniger zeitaufwendig. Andernfalls müsste jeder seinen eigenen Server unterhalten und Remotes hinzufügen und entfernen, um diese wenige Patches zu erhalten. Es ist auch unwahrscheinlich, dass du Hunderte von Remotes einbinden möchtest für Personen, die nur ein oder zwei Patches beisteuern. Skripte und gehostete Dienste können dies jedoch vereinfachen – dies hängt weitgehend davon ab, wie du und die Mitwirkenden entwickeln.
Der andere Vorteil dieses Ansatzes ist, dass du auch die Historie der Commits erhältst. Obwohl du möglicherweise Probleme bei der Zusammenführungen hast, wissen du, worauf in deiner Historie deren Arbeit basiert. Eine ordnungsgemäße Drei-Wege-Zusammenführung ist die Standardeinstellung, anstatt ein „-3“ einzugeben, und zu hoffen, dass der Patch aus einem öffentlichen Commit generiert wurde, auf den du Zugriff hast.
Wenn du nicht durchgängig mit einer Person arbeitest, aber dennoch auf diese Weise von dieser Person abrufen möchtest, kannst du die URL des Remote-Repositorys für den Befehl git pull angeben.
Dies führt einen einmaligen Abruf durch und speichert die URL nicht als Remote-Referenz:
$ git pull https://github.com/onetimeguy/project
From https://github.com/onetimeguy/project
* branch HEAD -> FETCH_HEAD
Merge made by the 'recursive' strategy.Bestimmen, was übernommen wird
Stell dir vor, du hast einen Feature Branch mit neuen Beiträgen. An dieser Stelle kannst du festlegen, was du damit machen möchtest. In diesem Abschnitt werden einige Befehle noch einmal behandelt. Mit diesen kannst du genau überprüfen, was du übernimmst, wenn du die Beiträge in deinem Hauptbranch zusammenführst.
Es ist oft hilfreich, eine Überprüfung über alle Commits zu erhalten, die sich in diesem Branch jedoch nicht in deinem master Branch befinden.
Du kannst Commits im master Branch ausschließen, indem du die Option --not vor dem Branchnamen hinzufügst.
Dies entspricht dem Format master..contrib, welches wir zuvor verwendet haben.
Wenn deine Mitstreiter dir bspw. zwei Patches senden und du einen Branch mit dem Namen contrib erstellst und diese Patches dort anwendest, kannst du Folgendes ausführen:
$ git log contrib --not master
commit 5b6235bd297351589efc4d73316f0a68d484f118
Author: Scott Chacon <schacon@gmail.com>
Date: Fri Oct 24 09:53:59 2008 -0700
See if this helps the gem
commit 7482e0d16d04bea79d0dba8988cc78df655f16a0
Author: Scott Chacon <schacon@gmail.com>
Date: Mon Oct 22 19:38:36 2008 -0700
Update gemspec to hopefully work betterDenke daran, dass du die Option -p an git log übergeben kannst, um zu sehen, welche Änderungen jeder Commit einführt.
Um einen vollständigen Überblick darüber zu erhalten, was passieren würde, wenn du diesen Branch mit einem anderen Branch zusammenführen würdest, musst du möglicherweise einen ungewöhnlichen Kniff anwenden, um die richtigen Ergebnisse zu erzielen. Eventuell denkst du daran folgendes auszuführen:
$ git diff masterDieser Befehl gibt die die Unterschiede zurück. Dies kann jedoch irreführend sein.
Wenn dein Masterbranch vorgerückt ist, seit du den Feature-Branch daraus erstellt hast, erhältst du scheinbar unerwartete Ergebnisse.
Dies geschieht, weil Git den Snapshots des letzten Commits des Branches, in dem du dich befindest, und den Snapshot des letzten Commits des Branches master direkt miteinander vergleicht.
Wenn du bspw. eine Zeile in eine Datei im Branch master eingefügt hast, sieht ein direkter Vergleich des Snapshots so aus, als würde der Feature Branch diese Zeile entfernen.
Wenn master ein direkter Vorgänger deines Feature-Branches ist, ist dies kein Problem. Wenn aber beiden Historien voneinander abweichen, sieht es so aus, als würdest du alle neuen Inhalte in deinem Featurebranch hinzufügen und alles entfernen, was im master Branch eindeutig ist.
Was du wirklich sehen möchtest, sind die Änderungen, die dem Featurebranch hinzugefügt wurden. Die Arbeit, die du hinzufügst, wenn du den neuen Branch mit master zusammenführst.
Du tust dies, indem Git den letzten Commit in deinem Featurebranch mit dem ersten gemeinsamen Vorgänger aus dem master Branch vergleicht.
Technisch gesehen könntest du dies tun, indem du den gemeinsamen Vorgänger explizit herausfindest und dann dein diff darauf ausführst:
$ git merge-base contrib master
36c7dba2c95e6bbb78dfa822519ecfec6e1ca649
$ git diff 36c7dboder kurzgefasst:
$ git diff $(git merge-base contrib master)Beides ist jedoch nicht besonders praktisch, weshalb Git einen anderen Weg für diesen Vorgang bietet: die Drei-Punkt-Syntax (engl. Triple-Dot-Syntax).
Im Kontext des Befehls git diff kannst du drei Punkte nach einem anderen Branch einfügen, um ein diff zwischen dem letzten Commit deines aktuellen Branch und dem gemeinsamen Vorgänger eines anderen Branches zu erstellen:
$ git diff master...contribDieser Befehl zeigt dir nur die Arbeit an, die dein aktueller Branch seit dem gemeinsamen Vorgänger mit master eingeführt hat.
Dies ist eine sehr nützliche Syntax, die du dir merken solltest.
Beiträge integrieren
Wenn dein Featurebranch bereit ist, um in einen Hauptbranch integriert zu werden, lautet die Frage, wie du dies tun kannst. Welchen Workflow möchtest du verwenden, um dein Projekt zu verwalten? Du hast eine Reihe von Möglichkeiten, daher werden wir einige davon behandeln.
Zusammenführungs Workflow (engl. mergen)
Ein grundlegender Workflow besteht darin, all diese Arbeiten einfach direkt in deinem master Branch zusammenzuführen.
In diesem Szenario hast du einen master Branch, der stabilen Code enthält.
Wenn du in einem Branch arbeitest, von dem du glaubst, dass du ihn abgeschlossen hast, oder von jemand anderem beigesteuert und überprüft hast, führst du ihn in deinem Hauptbranch zusammen. Lösche anschließend diesen gerade zusammengeführten Branch und wiederholen den Vorgang bei Bedarf.
Wenn wir zum Beispiel ein Repository mit zwei Branches namens ruby_client und php_client haben, die wie Historie mit mehreren Topic Branches aussehen, und wir ruby_client gefolgt von php_client zusammenführen, sieht dein Verlauf so aus Status nach einem Featurebranch Merge.
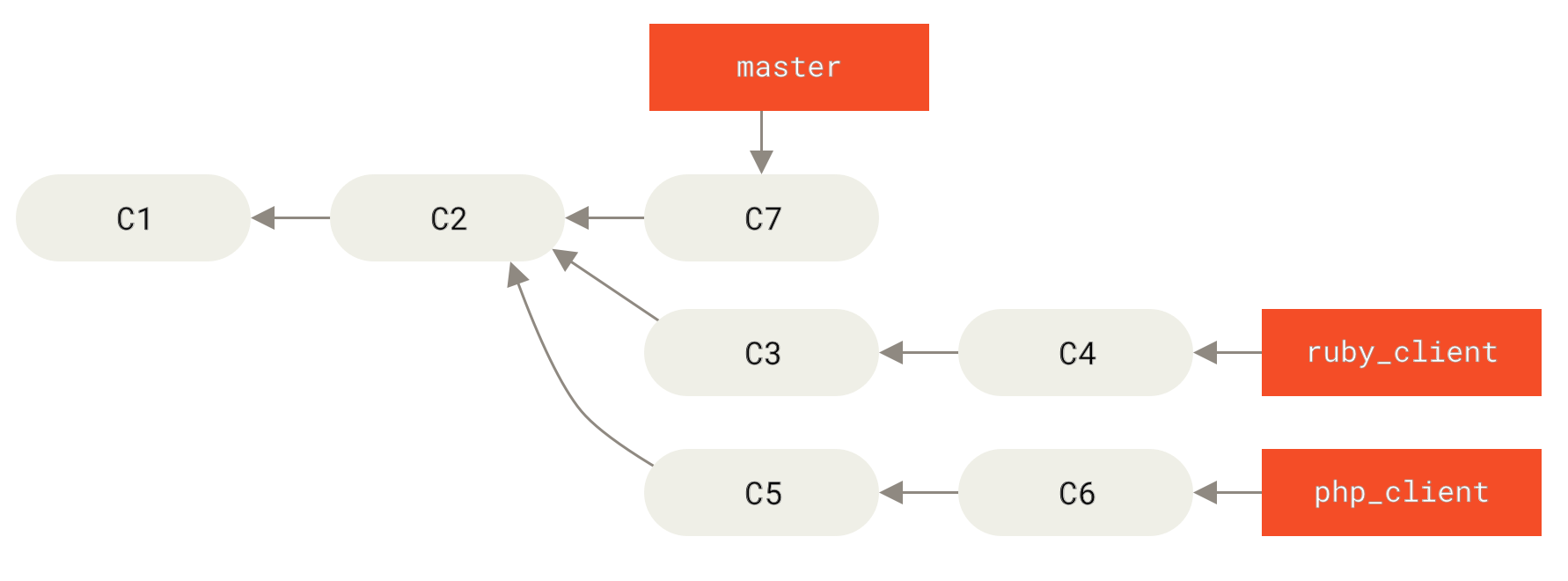
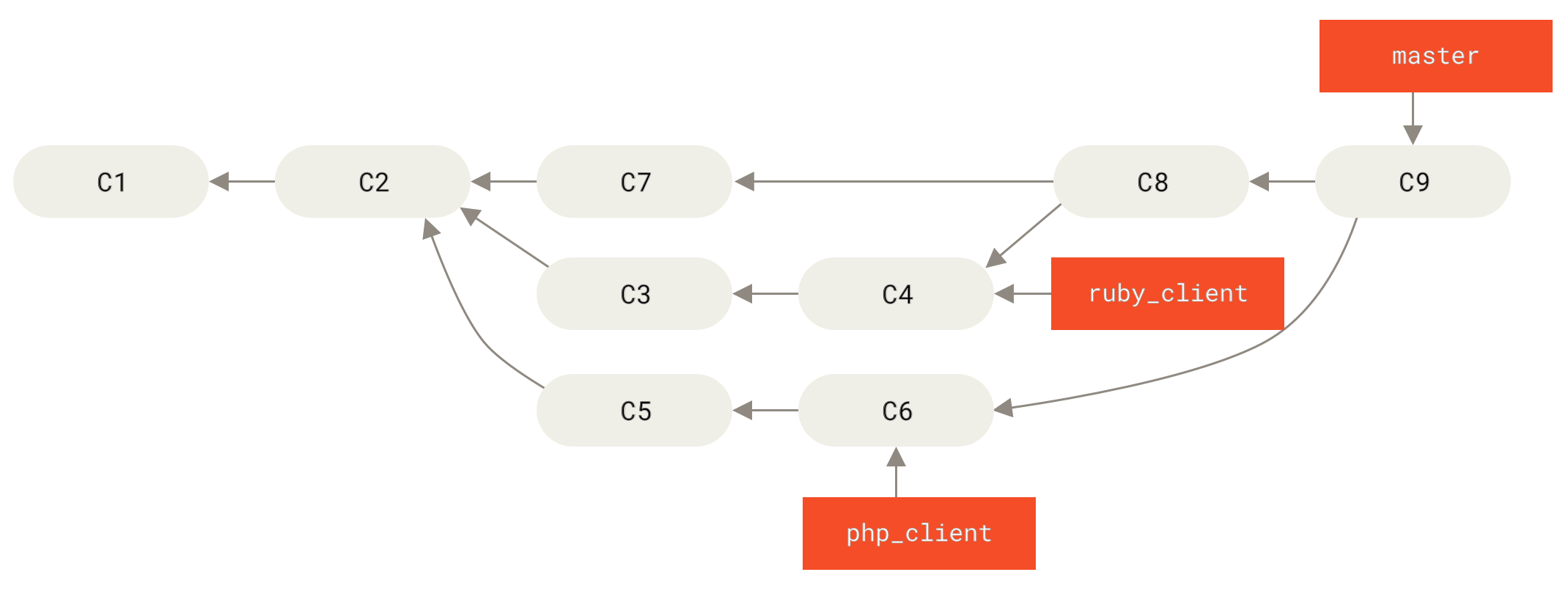
Das ist wahrscheinlich der einfachste Workflow. Es kann jedoch zu Problemen kommen, wenn du größere oder stabilere Projekte bearbeitest. Bei diesen musst du mit der Einführung von Änderungen sehr vorsichtig sein.
Wenn du ein wichtiges Projekt hast, möchtest du möglicherweise einen zweistufigen Merge Prozess verwenden.
In diesem Szenario hast du zwei lange laufende Branches namens master und develop. Du legst fest, dass master nur dann aktualisiert wird, wenn eine sehr stabile Version vorhanden ist und der gesamte neue Code in den Branch develop integriert wird.
Du pushst diese beiden Branches regelmäßig in das öffentliche Repository.
Jedes Mal, wenn du einen neuen Branch zum Zusammenführen hast (Vor einem Featurebranch Merge), führst du ihn in develop (Nach einem Featurebranch Merge) zusammen. Wenn du nun ein Release mit einem Tag versiehst, spulst du master an dieser Stelle weiter, an der sich der jetzt stabile develop Branch befindet (Nach einem Projekt Release).
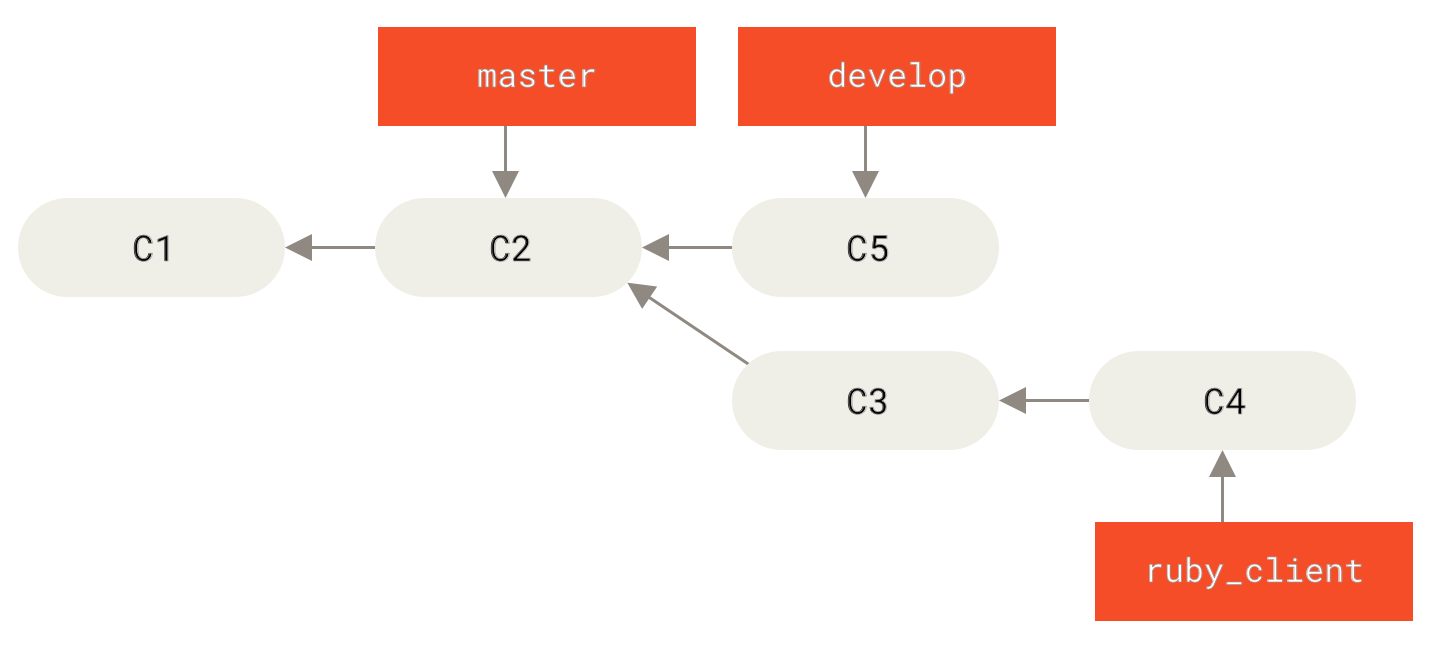
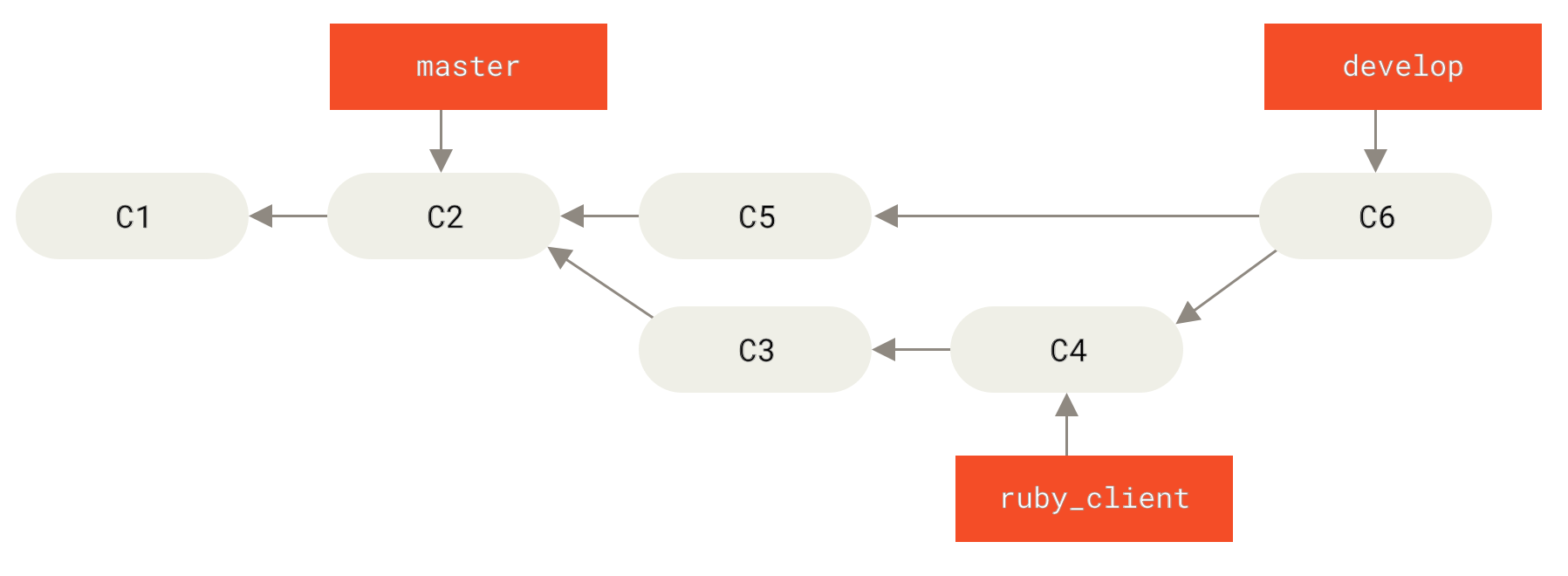
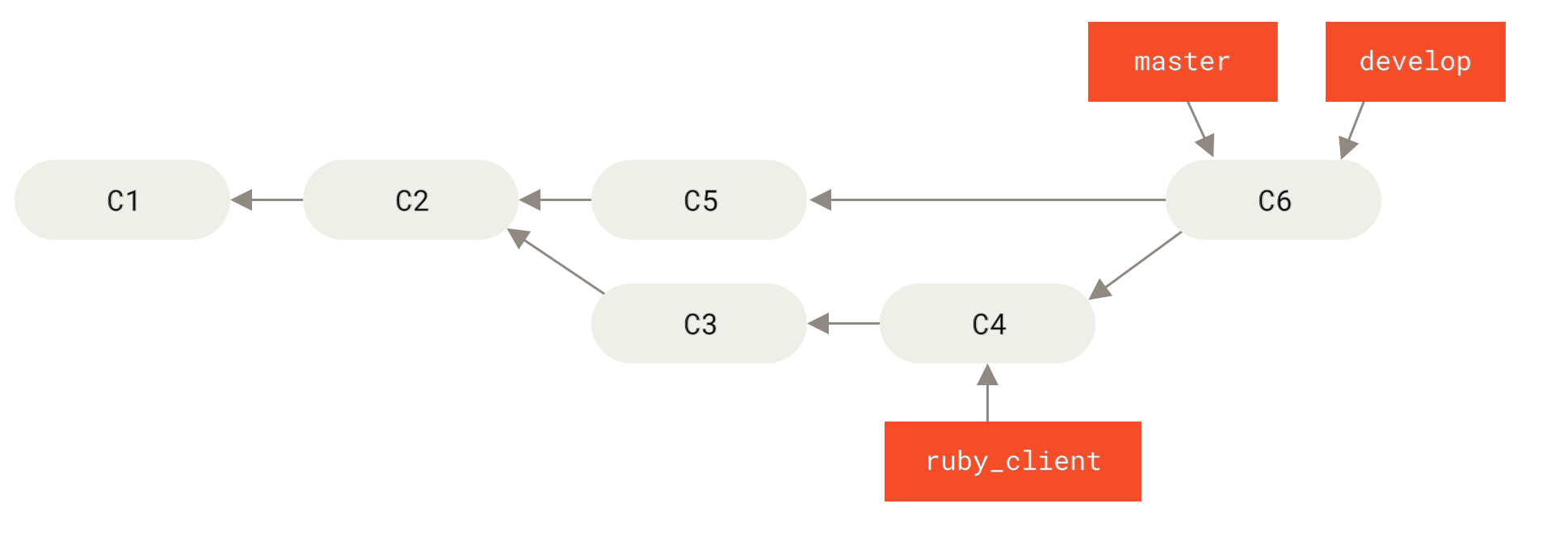
Auf diese Weise können Benutzer, die das Repository deines Projekts klonen, entweder master oder develop auschecken. Mit master können sie die neueste stabile Version erstellen und somit recht einfache auf dem neuesten Stand bleiben. Oder sie können develop auschecken, welchen den aktuellsten Inhalt enthält.
Du kannst dieses Konzept auch erweitern, indem du einen integrate Branch einrichtest, in dem alle Arbeiten zusammengeführt werden.
Wenn die Codebasis auf diesem Branch stabil ist und die Tests erfolgreich sind, kannst du sie zu einem Entwicklungsbranch zusammen führen. Wenn sich dieser dann als stabil erwiesen hat, kannst du deinen master Branch fast-forwarden.
Workflows mit umfangreichen Merges
Das Git-Projekt selber hat vier kontinuierlich laufende Branches: master, next und seen (vormals 'pu' – vorgeschlagene Updates) für neue Arbeiten und maint für Wartungs-Backports.
Wenn neue Arbeiten von Mitwirkenden eingereicht werden, werden sie in ähnlicher Weise wie oben beschrieben in Featurebranches im Projektrepository des Betreuers gesammelt (siehe Verwaltung einer komplexen Reihe paralleler Featurebranches).
Zu diesem Zeitpunkt werden die Features evaluiert, um festzustellen, ob sie korrekt sind und zur Weiterverarbeitung bereit sind oder ob sie Nacharbeit benötigen.
Wenn sie korrekt sind, werden sie zu next zusammengeführt, und dieser Branch wird dann gepusht, damit jeder die miteinander integrierten Features testen kann.
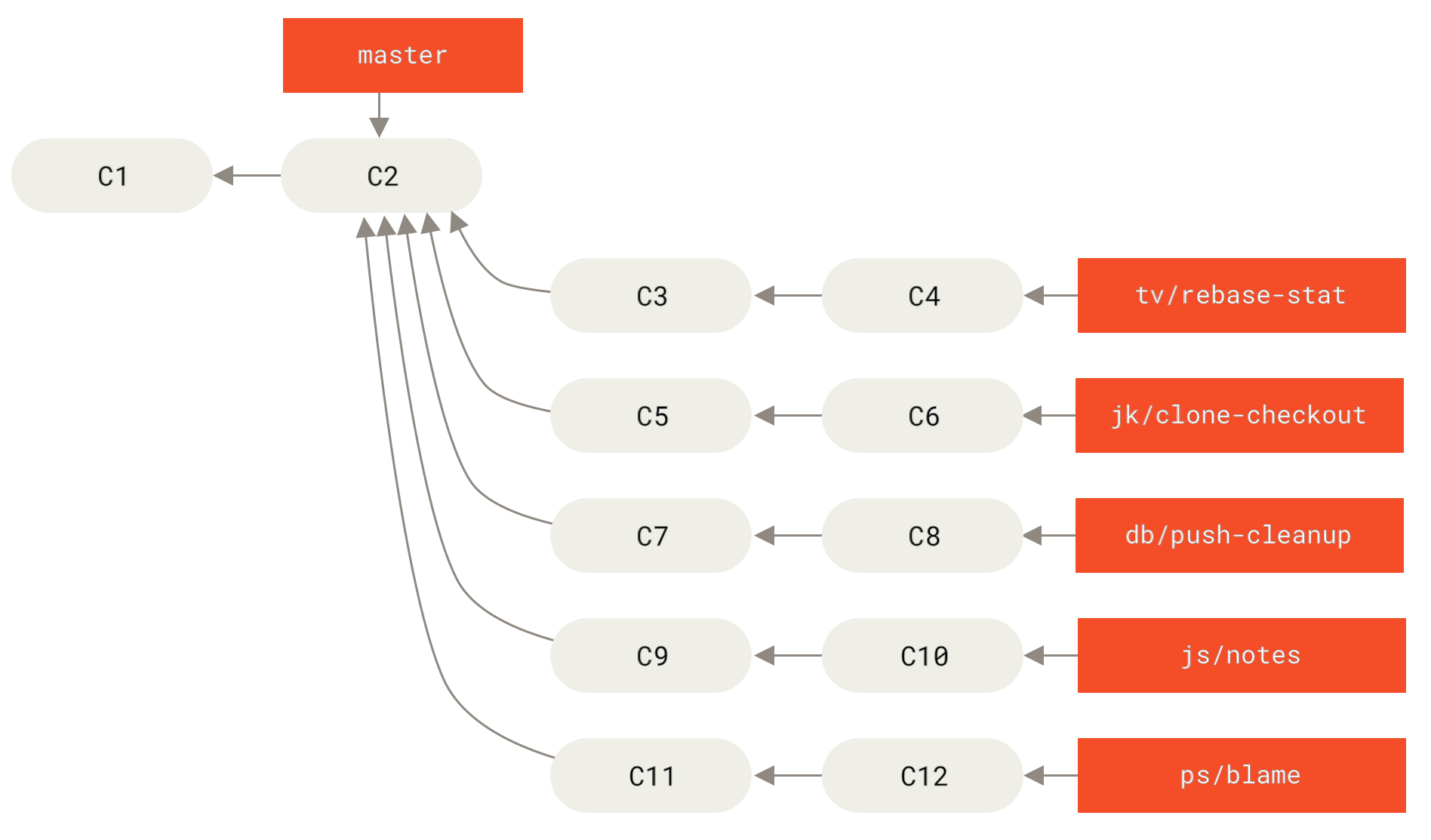
Wenn die Features noch bearbeitet werden müssen, werden sie in seen gemerged.
Wenn festgestellt wird, dass sie absolut stabil sind, werden die Features wieder zu master zusammengeführt.
Die Branches next und seen werden dann von master neu aufgebaut.
Dies bedeutet, dass master fast immer vorwärts geht, next wird gelegentlich und seen häufiger rebased:
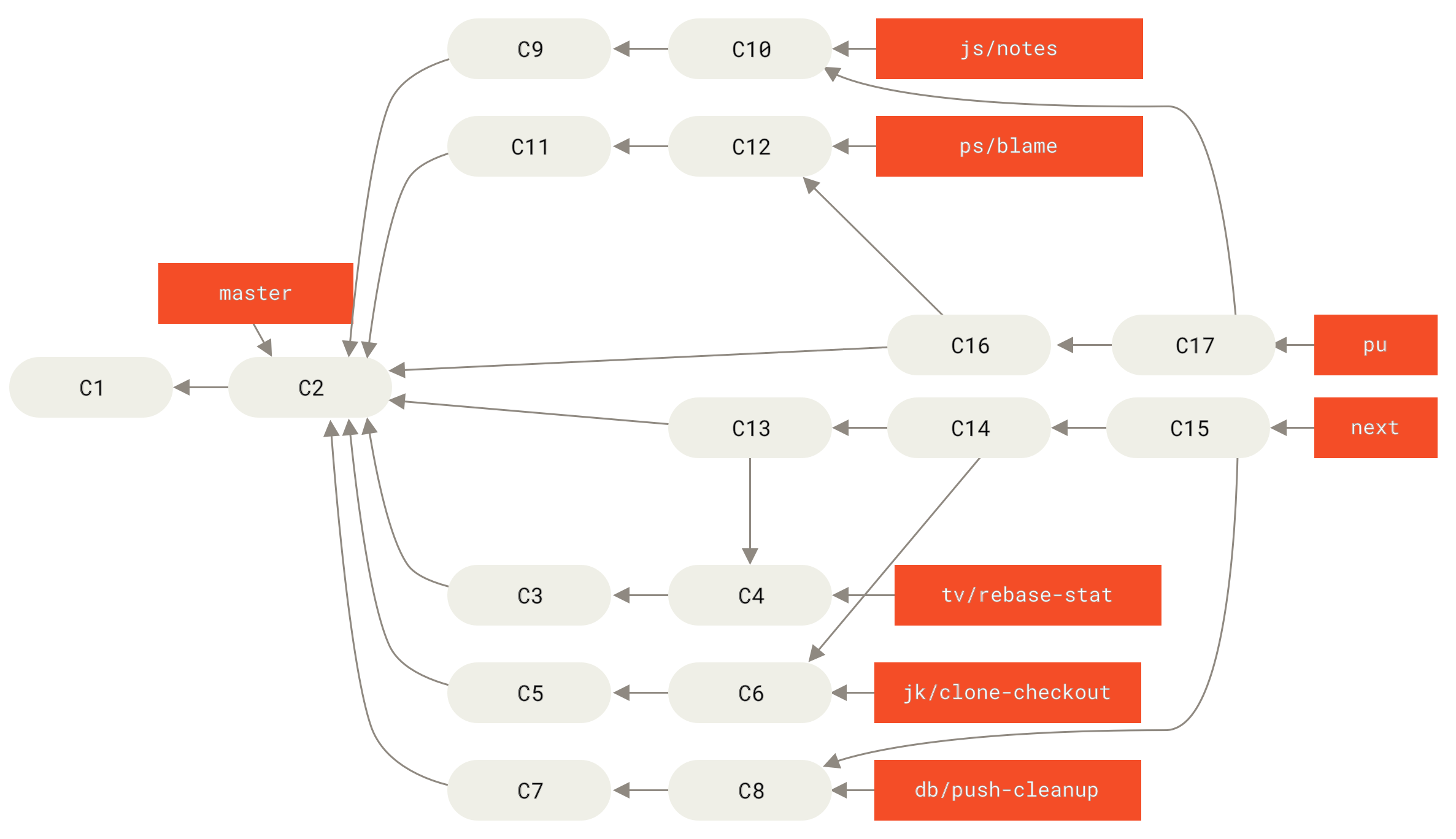
Wenn ein Branch schließlich zu master zusammengeführt wurde, wird er aus dem Repository entfernt.
Das Git-Projekt hat auch einen maint Branch, der von letzten release geforkt wurde, um für den Fall, dass eine Wartungsversion erforderlich ist, Backport-Patches bereitzustellen.
Wenn du das Git-Repository also klonst, stehen dir vier Branches zur Verfügung, mit denen du das Projekt in verschiedenen Entwicklungsstadien bewerten kannst, je nachdem, wie aktuell du sein möchtest oder wie du einen Beitrag leisten möchtest. Der Betreuer verfügt über einen strukturierten Workflow, der ihm hilft, neue Beiträge zu überprüfen.
Der Workflow des Git-Projekts ist sehr speziell.
Um dies zu verstehen, kannst du das Git Maintainer’s guide lesen.
Rebasing und Cherry-Picking Workflows
Andere Betreuer bevorzugen es, die Arbeit auf ihrem master Branch zu rebasen oder zu cherry-picken, anstatt sie zusammenzuführen, um einen linearen Verlauf beizubehalten.
Wenn du in einem Featureranch arbeitest und dich dazu entschlossen hast, ihn zu integrieren, wechselst du in diesen Branch und führst den rebase Befehl aus, um die Änderungen auf deinen master (oder develop Branch usw.) aufzubauen.
Wenn das gut funktioniert, kannst du deinen master Branch fast-forwarden, und du erhältst eine lineare Projekthistorie.
Eine andere Möglichkeit, die eingeführte Arbeit von einem Branch in einen anderen zu verschieben, besteht darin, sie zu cherry-picken. Ein Cherry-Pick in Git ist wie ein Rebase für ein einzelnes Commit. Es nimmt den Patch, der in einem Commit eingeführt wurde, und versucht ihn erneut auf den Branch anzuwenden, auf dem du dich gerade befindest. Dies ist nützlich, wenn du eine Reihe von Commits für einen Branch hast und nur einen davon integrieren möchtest. Oder aber wenn du nur einen Commit für einen Branch hast und es vorziehst, diesen zu cherry-picken, anstatt ein Rebase auszuführen. Angenommen, du hast ein Projekt, das folgendermaßen aussieht:
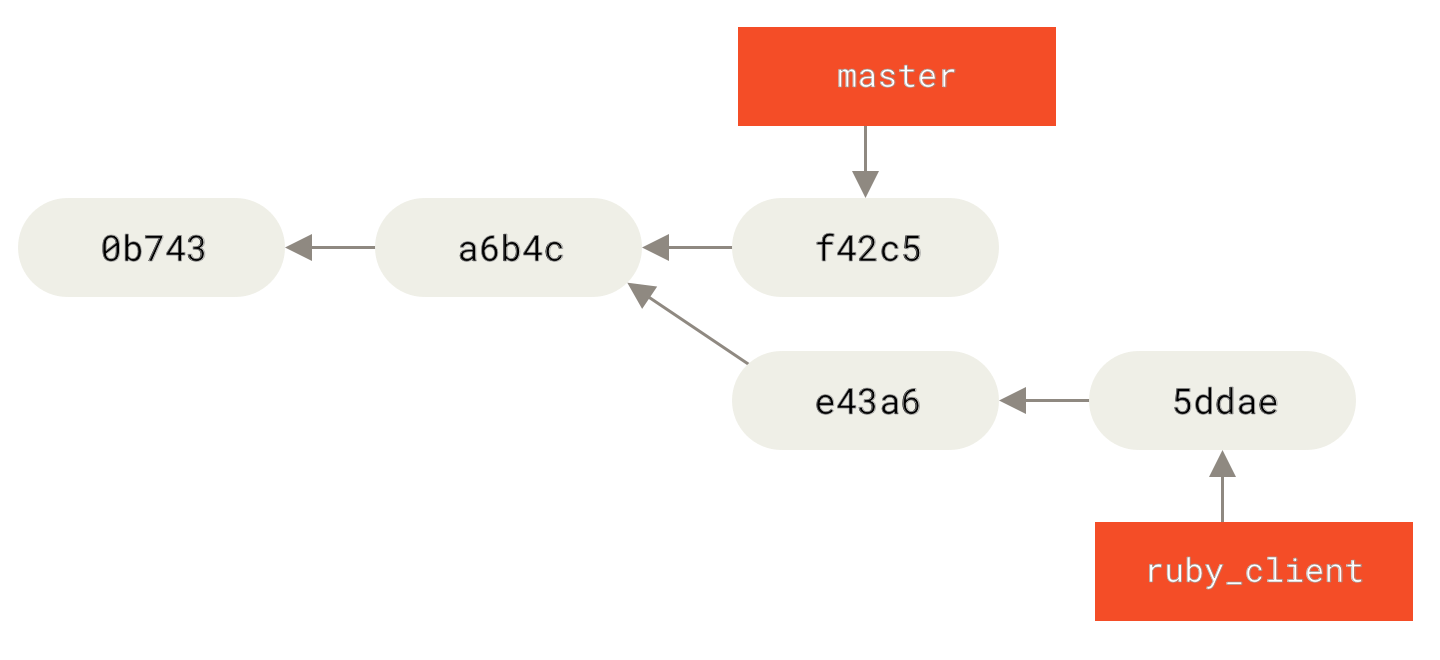
Wenn du den Commit „e43a6“ in deinem master Branch ziehen möchtest, kannst du folgendes ausführen:
$ git cherry-pick e43a6
Finished one cherry-pick.
[master]: created a0a41a9: "More friendly message when locking the index fails."
3 files changed, 17 insertions(+), 3 deletions(-)Dies zieht die gleiche Änderung nach sich, die in e43a6 eingeführt wurde. Du erhältst jedoch einen neuen Commit SHA-1-Wert, da das angewendete Datum unterschiedlich ist.
Nun sieht die Historie so aus:
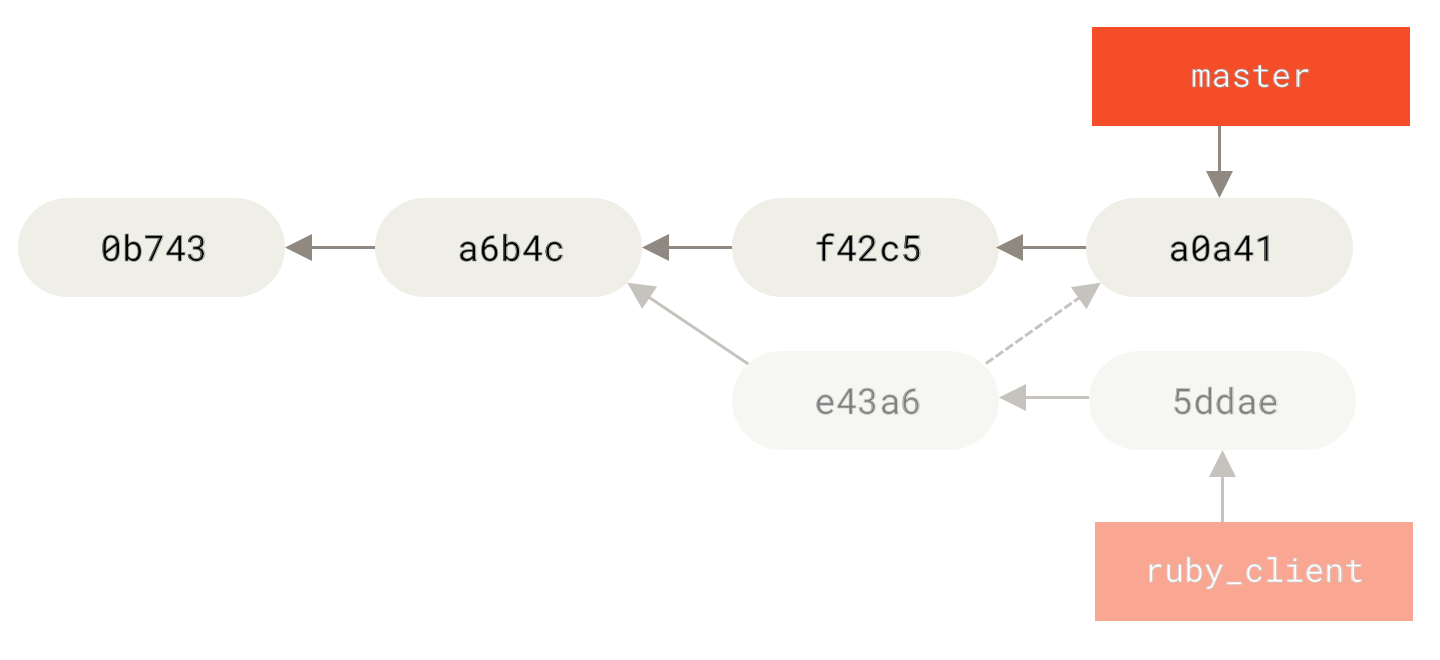
Jetzt kannst du deinen Featurebranch entfernen und die Commits löschen, die du nicht einbeziehen willst.
Rerere
Wenn du viel mergst und rebased oder einen langlebigen Featurebranch pflegst, hat Git eine Funktion namens „rerere“, die nützlich sein kann.
Rerere steht für „reuse recorded resolution“ (deutsch „Aufgezeichnete Lösung wiederverwenden“). Es ist eine Möglichkeit, die manuelle Konfliktlösung zu verkürzen. Wenn rerere aktiviert ist, behält Git eine Reihe von Pre- und Postimages von erfolgreichen Commits bei. Wenn es feststellt, dass ein Konflikt genauso aussieht, wie der, den du bereits behoben hast, wird die Korrektur vom letzten Mal verwendet, ohne nochmal nachzufragen.
Diese Funktion besteht aus zwei Teilen: einer Konfigurationseinstellung und einem Befehl.
Die Konfigurationseinstellung lautet rerere.enabled. Man kann sie in die globale Konfiguration eingeben:
$ git config --global rerere.enabled trueWenn du nun einen merge durchführst, der Konflikte auflöst, wird diese Auflösung im Cache für die Zukunft gespeichert.
Bei Bedarf kannst du mit dem rerere Cache mittels des Befehls git rerere interagieren.
Wenn der Befehlt ausgeführt wird, überprüft Git seine Lösungsdatenbank und versucht eine Übereinstimmung mit aktuellen Mergekonflikten zu finden und diesen zu lösen (dies geschieht jedoch automatisch, wenn rerere.enabled auf` true` gesetzt ist).
Es gibt auch Subbefehle, um zu sehen, was aufgezeichnet wird, um eine bestimmte Konfliktlösung aus dem Cache zu löschen oder um den gesamten Cache zu löschen.
Wir werden uns in Rerere eingehender mit rerere beschäftigen.
Tagging deines Releases
Wenn du dich entschieden hast, ein Release zu erstellen, dann möchtest du wahrscheinlich einen Tag zuweisen, damit du dieses Release in Zukunft jederzeit neu erstellen kannst. Du kannst einen neuen Tag erstellen, wie in Git Grundlagen beschrieben. Wenn du den Tag als Betreuer signieren möchtest, sieht der Tag möglicherweise folgendermaßen aus:
$ git tag -s v1.5 -m 'my signed 1.5 tag'
You need a passphrase to unlock the secret key for
user: "Scott Chacon <schacon@gmail.com>"
1024-bit DSA key, ID F721C45A, created 2009-02-09Wenn du deinen Tags signierst, hast du möglicherweise das Problem, den öffentlichen PGP-Schlüssel zu verteilen, der zum Signieren deines Tags verwendet wird.
Der Betreuer des Git-Projekts hat dieses Problem behoben, indem er seinen öffentlichen Schlüssel als Blob in das Repository aufgenommen und anschließend einen Tag hinzugefügt hat, der direkt auf diesen Inhalt verweist.
Um dies zu tun, kannst du herausfinden, welchen Schlüssel du möchtest, indem du gpg --list-keys ausführst:
$ gpg --list-keys
/Users/schacon/.gnupg/pubring.gpg
---------------------------------
pub 1024D/F721C45A 2009-02-09 [expires: 2010-02-09]
uid Scott Chacon <schacon@gmail.com>
sub 2048g/45D02282 2009-02-09 [expires: 2010-02-09]Anschließend kannst du den Schlüssel direkt in die Git-Datenbank importieren, indem du ihn exportierst und diesen über git hash-object weiterleitest. Dadurch wird ein neuer Blob mit diesen Inhalten in Git geschrieben und du erhältst den SHA-1 des Blobs zurück:
$ gpg -a --export F721C45A | git hash-object -w --stdin
659ef797d181633c87ec71ac3f9ba29fe5775b92Nachdem du nun den Inhalt deines Schlüssels in Git hast, kannst du einen Tag erstellen, der direkt darauf verweist. Dies tust du indem du den neuen SHA-1-Wert angibst, den du mit dem Befehl hash-object erhalten hast:
$ git tag -a maintainer-pgp-pub 659ef797d181633c87ec71ac3f9ba29fe5775b92Wenn du git push --tags ausführst, wird der Tag maintainer-pgp-pub für alle freigegeben.
Wenn jemand einen Tag verifizieren möchte, kann er deinen PGP-Schlüssel direkt importieren, indem er den Blob direkt aus der Datenbank zieht und in GPG importiert:
$ git show maintainer-pgp-pub | gpg --importMit diesem Schlüssel können alle deine signierten Tags überprüfen.
Wenn du der Tag-Nachricht Anweisungen hinzufügst, kannst du dem Endbenutzer mit git show <tag> genauere Anweisungen zur Tag-Überprüfung geben.
Eine Build Nummer generieren
Git verfügt nicht über ansteigende Zahlen wie 'v123' oder ähnliches für jeden Commit. Wenn du einen lesbaren Namen für deinen Commit benötigst, dann kannst du für diesen Commit den Befehl git describe ausführen.
Als Antwort generiert Git eine Zeichenfolge, die aus dem Namen des jüngsten Tags vor diesem Commit besteht, gefolgt von der Anzahl der Commits seit diesem Tag, gefolgt von einem partiellen SHA-1-Wert des beschriebene Commits (vorangestelltem wird dem Buchstaben „g“ für Git):
$ git describe master
v1.6.2-rc1-20-g8c5b85cAuf diese Weise kannst du einen Snaphot exportieren oder einen Build erstellen und einen verständlichen Namen vergeben.
Wenn du Git aus den Quellcode erstellst, der aus dem Git-Repository geklont wurde, erhältst du mit git --version etwas, das genauso aussieht.
Wenn du einen Commit beschreibst, den du direkt getaggt hast, erhältst du einfach den Tag-Namen.
Standardmäßig erfordert der Befehl git describe annotierte (mit Anmerkungen versehene) Tags (die mit dem Flag -a oder -s erstellt wurden). Wenn du auch leichtgewichtige (nicht mit Anmerkungen versehene) Tags verwenden möchtest, fügst du dem Befehl die Option --tags hinzu.
Du kannst diese Zeichenfolge auch als Ziel der Befehle git checkout oder git show verwenden, obwohl sie auf dem abgekürzten SHA-1-Wert am Ende basiert, sodass sie möglicherweise nicht für immer gültig ist.
Zum Beispiel hat der Linux-Kernel kürzlich einen Sprung von 8 auf 10 Zeichen gemacht, um die Eindeutigkeit von SHA-1-Objekten zu gewährleisten, sodass ältere Ausgabenamen von git describe ungültig wurden.
Ein Release vorbereiten
Als nächstes möchtest du einen Build freigeben.
Eines der Dinge, die du tun möchtest, ist ein Archiv des neuesten Schnappschusses deines Codes für die Unglücklichen zu erstellen, die Git nicht verwenden.
Der Befehl dazu lautet git archive:
$ git archive master --prefix='project/' | gzip > `git describe master`.tar.gz
$ ls *.tar.gz
v1.6.2-rc1-20-g8c5b85c.tar.gzWenn jemand dieses Archiv öffnet, erhält er den neuesten Schnappschuss deines Projekts in einem projekt Verzeichnis.
Du kannst auch ein zip-Archiv auf die gleiche Weise erstellen, indem du jedoch die Option --format=zip an git archive übergibst:
$ git archive master --prefix='project/' --format=zip > `git describe master`.zipDu hast jetzt einen schönen Tarball und ein Zip-Archiv deiner Projektversion, die du auf deiner Website hochladen oder per E-Mail an andere Personen senden kannst.
Das Shortlog
Es ist Zeit, eine E-Mail an die Personen deiner Mailingliste zu senden, die wissen möchten, was in deinem Projekt vor sich geht.
Mit dem Befehl git shortlog kannst du schnell eine Art Änderungsprotokoll dessen abrufen, was deinem Projekt seit deiner letzten Veröffentlichung oder deiner letzte E-Mail hinzugefügt wurde.
Es fasst alle Commits in dem von dir angegebenen Bereich zusammen. Im Folgenden findest du als Beispiel eine Zusammenfassung aller Commits seit deiner letzten Veröffentlichung, sofern deine letzte Veröffentlichung den Namen v1.0.1 hat:
$ git shortlog --no-merges master --not v1.0.1
Chris Wanstrath (6):
Add support for annotated tags to Grit::Tag
Add packed-refs annotated tag support.
Add Grit::Commit#to_patch
Update version and History.txt
Remove stray `puts`
Make ls_tree ignore nils
Tom Preston-Werner (4):
fix dates in history
dynamic version method
Version bump to 1.0.2
Regenerated gemspec for version 1.0.2Du erhältst eine übersichtliche Zusammenfassung aller Commits seit Version 1.0.1, gruppiert nach Autoren, die du per E-Mail an deine Mailingliste senden kannst.