
-
1. 使い始める
- 1.1 バージョン管理に関して
- 1.2 Git略史
- 1.3 Gitの基本
- 1.4 コマンドライン
- 1.5 Gitのインストール
- 1.6 最初のGitの構成
- 1.7 ヘルプを見る
- 1.8 まとめ
-
2. Git の基本
- 2.1 Git リポジトリの取得
- 2.2 変更内容のリポジトリへの記録
- 2.3 コミット履歴の閲覧
- 2.4 作業のやり直し
- 2.5 リモートでの作業
- 2.6 タグ
- 2.7 Git エイリアス
- 2.8 まとめ
-
3. Git のブランチ機能
- 3.1 ブランチとは
- 3.2 ブランチとマージの基本
- 3.3 ブランチの管理
- 3.4 ブランチでの作業の流れ
- 3.5 リモートブランチ
- 3.6 リベース
- 3.7 まとめ
-
4. Gitサーバー
- 4.1 プロトコル
- 4.2 サーバー用の Git の取得
- 4.3 SSH 公開鍵の作成
- 4.4 サーバーのセットアップ
- 4.5 Git デーモン
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 サードパーティによる Git ホスティング
- 4.10 まとめ
-
5. Git での分散作業
- 5.1 分散作業の流れ
- 5.2 プロジェクトへの貢献
- 5.3 プロジェクトの運営
- 5.4 まとめ
-
6. GitHub
- 6.1 アカウントの準備と設定
- 6.2 プロジェクトへの貢献
- 6.3 プロジェクトのメンテナンス
- 6.4 組織の管理
- 6.5 スクリプトによる GitHub の操作
- 6.6 まとめ
-
7. Git のさまざまなツール
- 7.1 リビジョンの選択
- 7.2 対話的なステージング
- 7.3 作業の隠しかたと消しかた
- 7.4 作業内容への署名
- 7.5 検索
- 7.6 歴史の書き換え
- 7.7 リセットコマンド詳説
- 7.8 高度なマージ手法
- 7.9 Rerere
- 7.10 Git によるデバッグ
- 7.11 サブモジュール
- 7.12 バンドルファイルの作成
- 7.13 Git オブジェクトの置き換え
- 7.14 認証情報の保存
- 7.15 まとめ
-
8. Git のカスタマイズ
- 8.1 Git の設定
- 8.2 Git の属性
- 8.3 Git フック
- 8.4 Git ポリシーの実施例
- 8.5 まとめ
-
9. Gitとその他のシステムの連携
- 9.1 Git をクライアントとして使用する
- 9.2 Git へ移行する
- 9.3 まとめ
-
10. Gitの内側
- 10.1 配管(Plumbing)と磁器(Porcelain)
- 10.2 Gitオブジェクト
- 10.3 Gitの参照
- 10.4 Packfile
- 10.5 Refspec
- 10.6 転送プロトコル
- 10.7 メンテナンスとデータリカバリ
- 10.8 環境変数
- 10.9 まとめ
-
A1. 付録 A: その他の環境でのGit
- A1.1 グラフィカルインタフェース
- A1.2 Visual StudioでGitを使う
- A1.3 EclipseでGitを使う
- A1.4 BashでGitを使う
- A1.5 ZshでGitを使う
- A1.6 PowershellでGitを使う
- A1.7 まとめ
-
A2. 付録 B: Gitをあなたのアプリケーションに組み込む
- A2.1 Gitのコマンドラインツールを使う方法
- A2.2 Libgit2を使う方法
- A2.3 JGit
-
A3. 付録 C: Gitのコマンド
- A3.1 セットアップと設定
- A3.2 プロジェクトの取得と作成
- A3.3 基本的なスナップショット
- A3.4 ブランチとマージ
- A3.5 プロジェクトの共有とアップデート
- A3.6 検査と比較
- A3.7 デバッグ
- A3.8 パッチの適用
- A3.9 メール
- A3.10 外部システム
- A3.11 システム管理
- A3.12 配管コマンド
7.7 Git のさまざまなツール - リセットコマンド詳説
リセットコマンド詳説
専門的なツールを説明する前に、reset と checkout について触れておきます。
いざ使うことになると、一番ややこしい部類の Git コマンドです。
出来ることがあまりに多くて、ちゃんと理解したうえで正しく用いることなど夢のまた夢のようにも思えてしまいます。
よって、ここでは単純な例えを使って説明していきます。
3つのツリー
reset と checkout を単純化したいので、Git を「3つのツリーのデータを管理するためのツール」と捉えてしまいましょう。
なお、ここでいう「ツリー」とはあくまで「ファイルの集まり」であって、データ構造は含みません。
(Git のインデックスがツリーとは思えないようなケースもありますが、ここでは単純にするため、「ツリー=ファイルの集まり」で通していきます。)
いつものように Git を使っていくと、以下のツリーを管理・操作していくことになります。
| ツリー | 役割 |
|---|---|
HEAD |
最新コミットのスナップショットで、次は親になる |
インデックス |
次のコミット候補のスナップショット |
作業ディレクトリ |
サンドボックス |
HEAD
現在のブランチを指し示すポインタは HEAD と呼ばれています。HEAD は、そのブランチの最新コミットを指し示すポインタでもあります。 ということは、HEAD が指し示すコミットは新たに追加されていくコミットの親になる、ということです。 HEAD のことを 最新のコミット のスナップショットと捉えておくとわかりやすいでしょう。
では、スナップショットの内容を確認してみましょう。実に簡単です。 ディレクトリ構成と SHA-1 チェックサムを HEAD のスナップショットから取得するには、以下のコマンドを実行します。
$ git cat-file -p HEAD
tree cfda3bf379e4f8dba8717dee55aab78aef7f4daf
author Scott Chacon 1301511835 -0700
committer Scott Chacon 1301511835 -0700
initial commit
$ git ls-tree -r HEAD
100644 blob a906cb2a4a904a152... README
100644 blob 8f94139338f9404f2... Rakefile
040000 tree 99f1a6d12cb4b6f19... libcat-file や ls-tree は「配管」コマンドなので、日々の作業で使うことはないはずでしょう。ただし、今回のように詳細を把握するには便利です。
インデックス
インデックスとは、次のコミット候補 のことを指します。Git の「ステージングエリア」と呼ばれることもあります。git commit を実行すると確認される内容だからです。
インデックスの中身は、前回のチェックアウトで作業ディレクトリに保存されたファイルの一覧になっています。保存時のファイルの状態も記録されています。
ファイルに変更を加え、git commit コマンドを実行すると、ツリーが作成され新たなコミットとなります。
$ git ls-files -s
100644 a906cb2a4a904a152e80877d4088654daad0c859 0 README
100644 8f94139338f9404f26296befa88755fc2598c289 0 Rakefile
100644 47c6340d6459e05787f644c2447d2595f5d3a54b 0 lib/simplegit.rbこの例で使った ls-files コマンドも縁の下の力持ち的なコマンドです。インデックスの状態を表示してくれます。
なお、インデックスは厳密にはツリー構造ではありません。実際には、階層のない構造になっています。ただ、理解する上ではツリー構造と捉えて差し支えありません。
作業ディレクトリ
3つのツリーの最後は作業ディレクトリです。
他のツリーは、データを .git ディレクトリ内に処理しやすい形で格納してしまうため、人間が取り扱うには不便でした。
一方、作業ディレクトリにはデータが実際のファイルとして展開されます。とても取り扱いやすい形です。
作業ディレクトリのことは サンドボックス だと思っておいてください。そこでは、自由に変更を試せます。変更が完了したらステージングエリア(インデックス)に追加し、さらにコミットして歴史に追加するのです。
$ tree
.
├── README
├── Rakefile
└── lib
└── simplegit.rb
1 directory, 3 files作業手順
Git を使う主目的は、プロジェクトのスナップショットを健全な状態で取り続けることです。そのためには、3つのツリーを操作する必要があります。
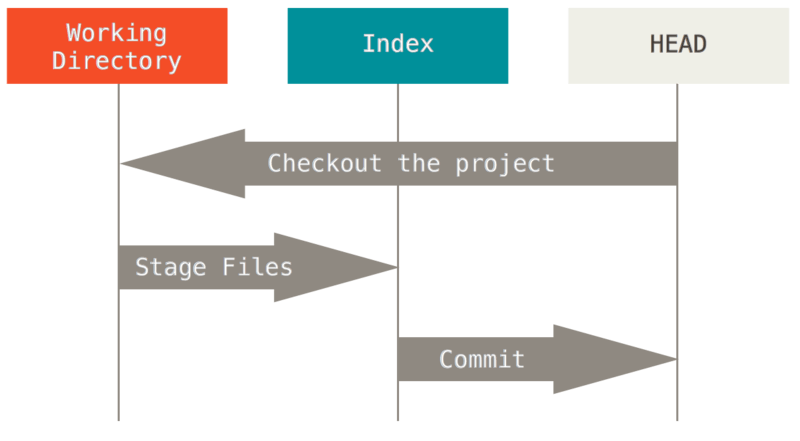
その手順を頭を使って説明しましょう。まず、新しいディレクトリを作って、テキストファイルをひとつ保存したとします。
現段階でのこのファイルを v1 としましょう(図では青塗りの部分)。
次に git init を実行して Git リポジトリを生成します。このときの HEAD は、これから生成される予定のブランチを指し示すことになります( master はまだ存在しません)。
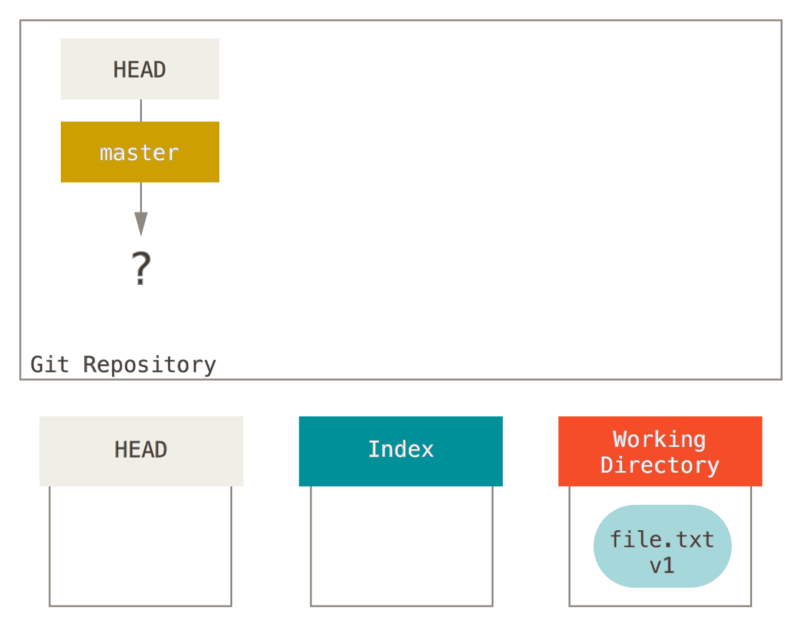
この時点では、作業ディレクトリにしかテキストファイルのデータは存在しません。
では、このファイルをコミットしてみましょう。まずは git add を実行して、作業ディレクトリ上のデータをインデックスにコピーします。
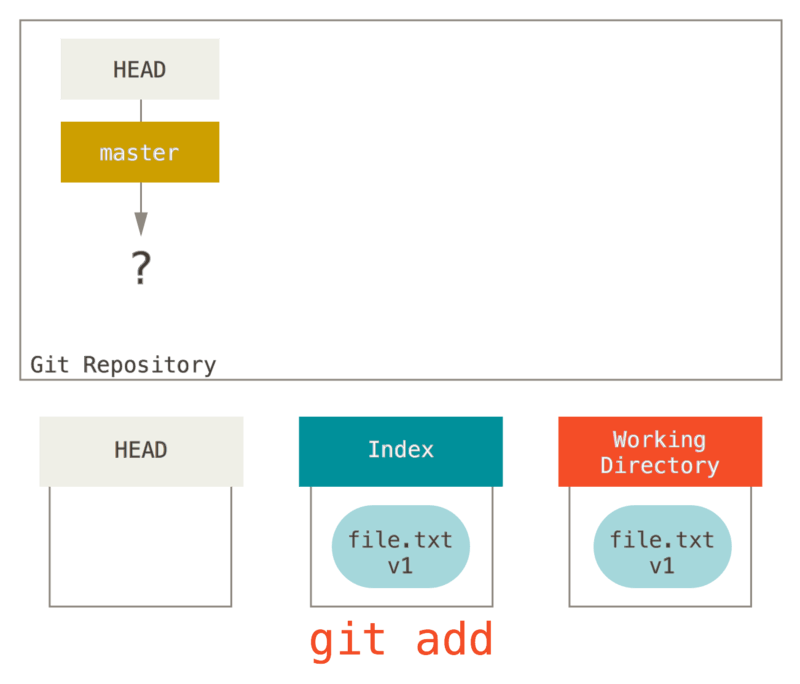
さらに、git commit を実行し、インデックスの内容でスナップショットを作成します。そうすると、作成したスナップショットをもとにコミットオブジェクトが作成され、master がそのコミットを指し示すようになります。
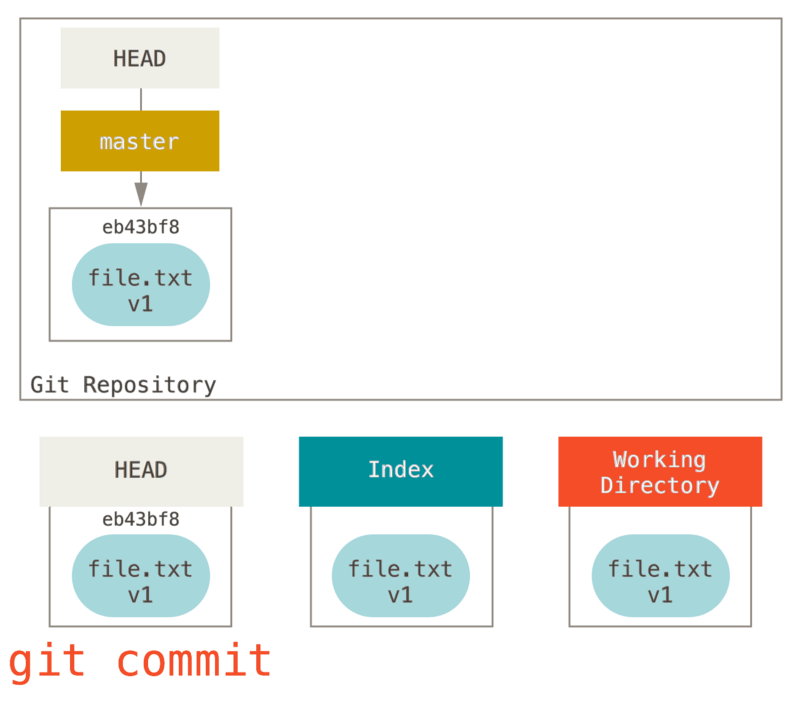
この段階で git status を実行しても、何も変更点は出てきません。3つのツリーが同じ状態になっているからです。
続いて、このテキストファイルの内容を変更してからコミットしてみましょう。 手順はさきほどと同じです。まずは、作業ディレクトリにあるファイルを変更します。 変更した状態のファイルを v2 としましょう(図では赤塗りの部分)。
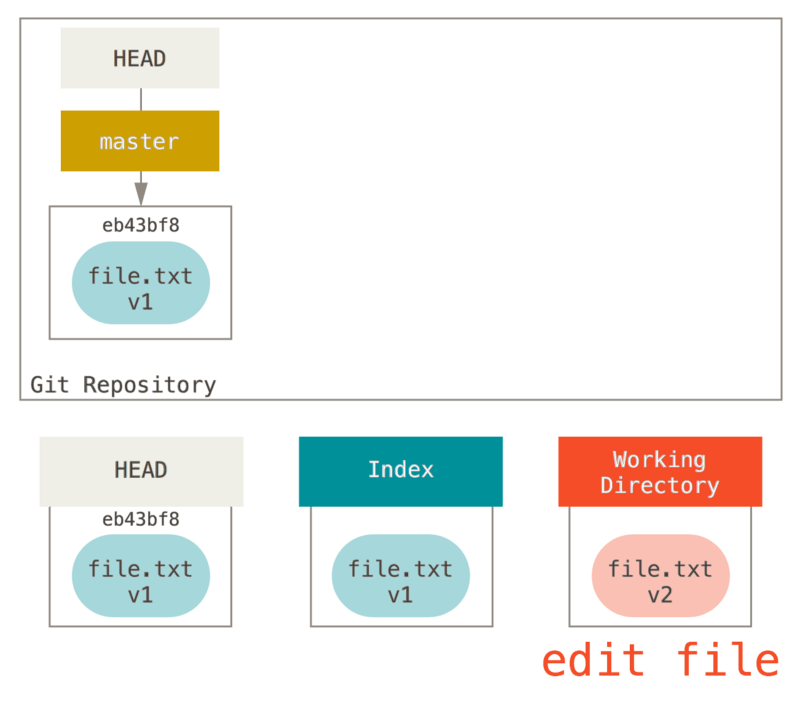
git status をここで実行すると、コマンド出力の “Changes not staged for commit” 欄に赤塗り部分のファイルが表示されます。作業ディレクトリ上のそのファイルの状態が、インデックスの内容とは異なっているからです。
では、git add を実行して変更をインデックスに追加してみましょう。
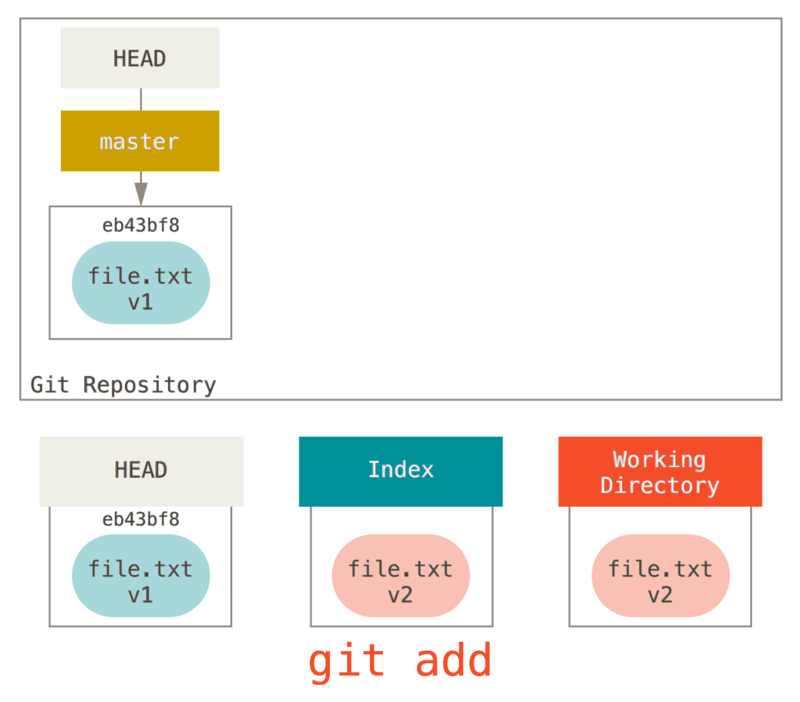
この状態で git status を実行すると、以下の図で緑色の枠内にあるファイルがコマンド出力の “Changes to be committed” 欄 に表示されます。インデックスと HEAD の内容に差分があるからです。次のコミット候補と前回のコミットの内容に差異が生じた、とも言えます。
では、git commit を実行してコミット内容を確定させましょう。
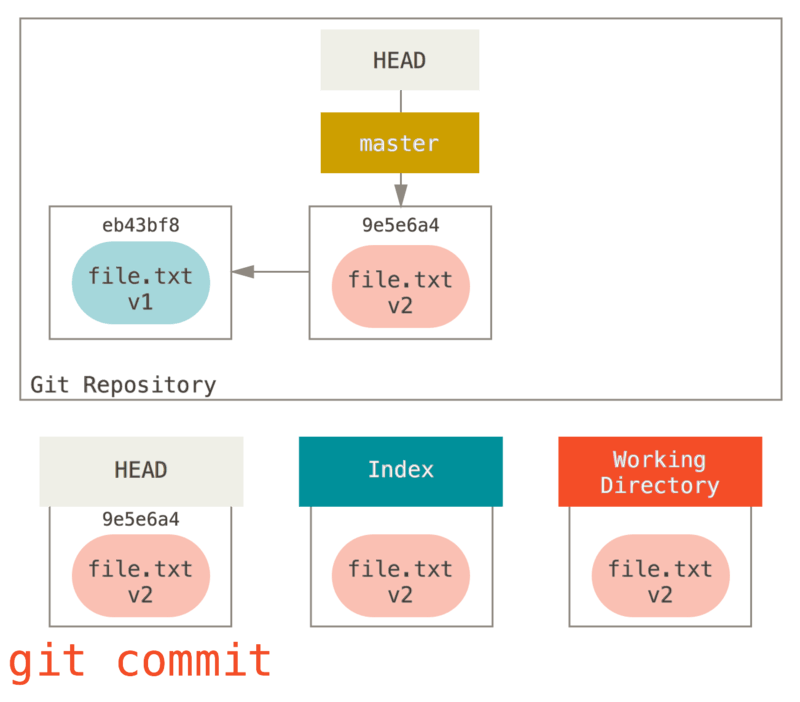
ここで git status を実行しても何も出力されません。3つのツリーが同じ状態に戻ったからです。
なお、ブランチを切り替えたりリモートブランチをクローンしても同じような処理が走ります。 ブランチをチェックアウトしたとしましょう。そうすると、HEAD はそのブランチを指すようになります。さらに、HEAD コミットのスナップショットで インデックス が上書きされ、そのデータが 作業ディレクトリ にコピーされます。
リセットの役割
これから説明する内容に沿って考えれば、reset コマンドの役割がわかりやすくなるはずです。
説明で使う例として、さきほど使った file.txt をまた編集し、コミットしたと仮定します。その場合、このリポジトリの歴史は以下のようになります。
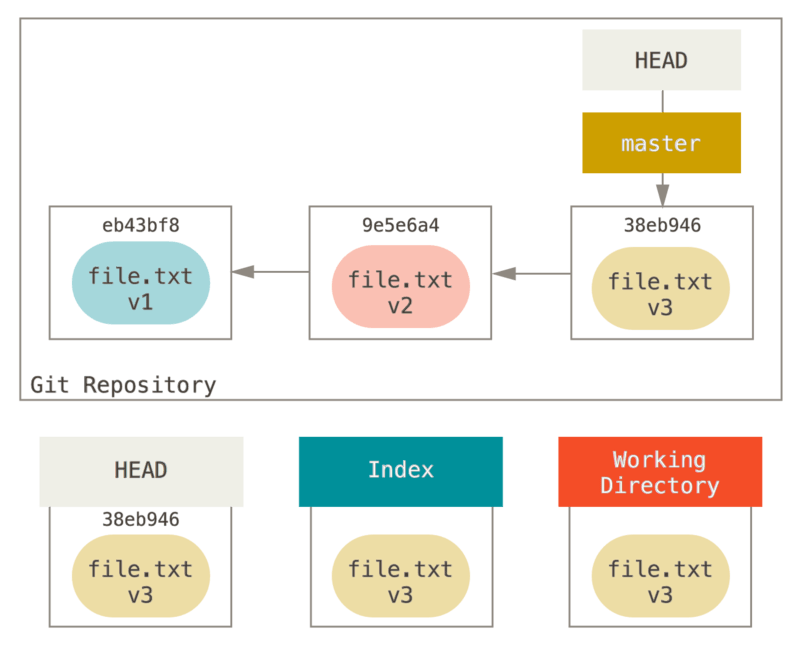
では、reset コマンドの処理の流れを順を追って見ていきましょう。単純な方法で3つのツリーが操作されていきます。
一連の処理は、最大で3つになります。
処理1 HEAD の移動
reset コマンドを実行すると、HEAD に指し示されているものがまずは移動します。
これは、checkout のときのような、HEAD そのものを書き換えてしまう処理ではありません。HEAD が指し示すブランチの方が移動する、ということです。
つまり、仮に HEAD が master ブランチを指している(master ブランチをチェックアウトした状態)場合、git reset 9e5e6a4 を実行すると master ブランチがコミット 9e5e6a4 を指すようになります。
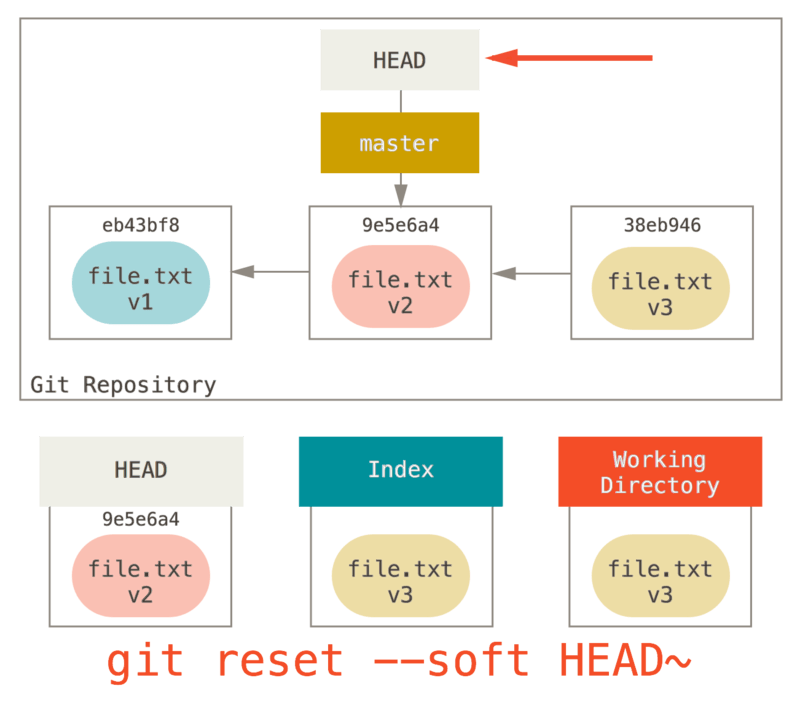
付与されたオプションがなんであれ、コミットを指定して reset コマンド実行すると、必ず上記の処理が走ります。
reset --soft オプションを使った場合は、コマンドはここで終了します。
そして、改めて図を見てみると、直近の git commit コマンドが取り消されていることがわかると思います。
通常であれば、git commit を実行すると新しいコミットが作られ、HEAD が指し示すブランチはそのコミットまで移動します。
また、reset を実行して HEAD~ (HEAD の親)までリセットすれば、ブランチは以前のコミットまで巻き戻されます。この際、インデックスや作業ディレクトリは変更されません。
なお、この状態でインデックスを更新して git commit を実行すれば、git commit --amend を行った場合と同じ結果が得られます(詳しくは 直近のコミットの変更 を参照してください)。
処理2 インデックスの更新 (--mixed)
ここで git status を実行すると、インデックスの内容と変更された HEAD の内容との差分がわかることを覚えておきましょう。
第2の処理では、reset は HEAD が指し示すスナップショットでインデックスを置き換えます。
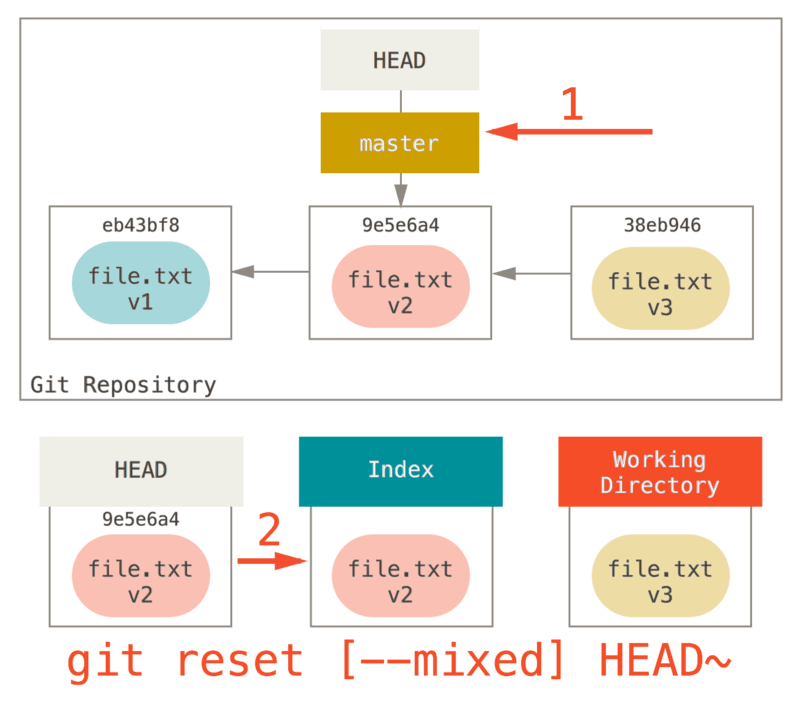
--mixed オプションを使うと、reset はここで終了します。
また、このオプションはデフォルトになっています。ここでの例の git reset HEAD~ のようにオプションなしでコマンドを実行しても、reset はここで終了します。
では、もう一度図を見てみましょう。直近の commit がさきほどと同様に取り消されており、さらにインデックスの内容も 取り消された ことがわかります。
git add でインデックスに追加し、git commit でコミットとして確定させた内容が取り消されたということです。
処理3 作業ディレクトリの更新 (--hard)
reset の第3の処理は、作業ディレクトリをインデックスと同じ状態にすることです。
--hard オプションを使うと、処理はこの段階まで進むことになります。
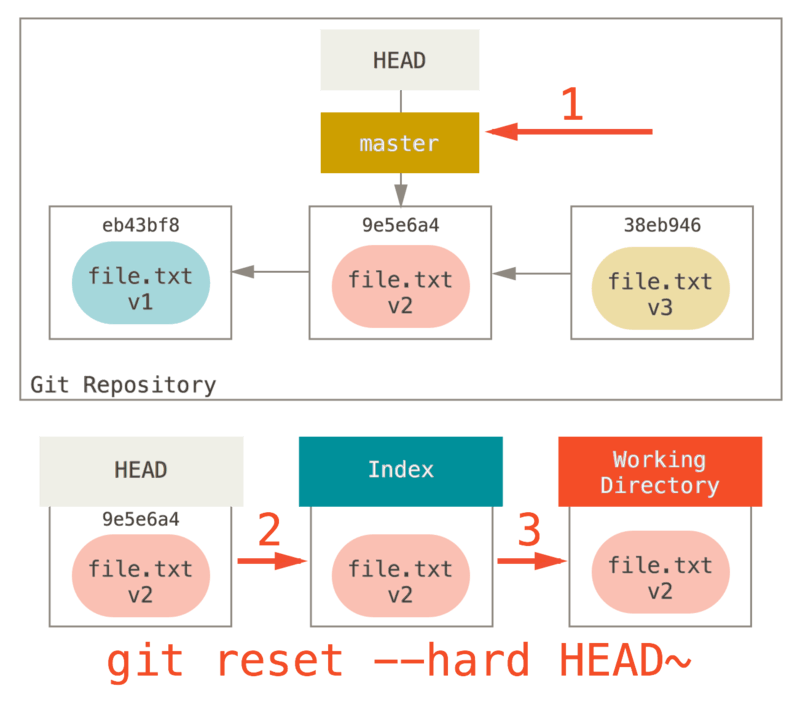
第3の処理が走ると何が起こるのでしょうか。
まず、直近のコミットが巻き戻されます。git add と git commit で確定した内容も同様です。さらに、作業ディレクトリの状態も巻き戻されてしまいます。
--hard オプションを使った場合に限り、reset コマンドは危険なコマンドになってしまうことを覚えておいてください。Git がデータを完全に削除してしまう、数少ないパターンです。
reset コマンドの実行結果は簡単に取り消せますが、--hard オプションに限ってはそうはいきません。作業ディレクトリを強制的に上書きしてしまうからです。
ここに挙げた例では、v3 バージョンのファイルは Git のデータベースにコミットとしてまだ残っていて、reflog を使えば取り戻せます。ただしコミットされていない内容については、上書きされてしまうため取り戻せません。
要約
reset コマンドを使うと、3つのツリーを以下の順で上書きしていきます。どこまで上書きするかはオプション次第です。
-
HEAD が指し示すブランチを移動する (
--softオプションを使うと処理はここまで) -
インデックスの内容を HEAD と同じにする (
--hardオプションを使わなければ処理はここまで) -
作業ディレクトリの内容をインデックスと同じにする
パスを指定したリセット
ここまでで、reset の基礎と言える部分を説明してきました。次に、パスを指定して実行した場合の挙動について説明します。
パスを指定して reset を実行すると、処理1は省略されます。また、処理2と3については、パスで指定された範囲(ファイル郡)に限って実行されます。
このように動作するのはもっともな話です。処理1で操作される HEAD はポインタにすぎず、指し示せるコミットは一つだけだからです(こちらのコミットのこの部分と、あちらのコミットのあの部分、というようには指し示せません)。
一方、インデックスと作業ディレクトリを一部分だけ更新することは 可能 です。よって、リセットの処理2と3は実行されます。
実際の例として、 git reset file.txt を実行したらどうなるか見ていきましょう。
このコマンドは git reset --mixed HEAD file.txt のショートカット版(ブランチやコミットの SHA-1 の指定がなく、 --soft or --hard の指定もないため)です。実行すると、
-
HEAD が指し示すブランチを移動する (この処理は省略)
-
HEAD の内容でインデックスを上書きする (処理はここまで)
が行われます。要は、HEAD からインデックスに file.txt がコピーされるということです。
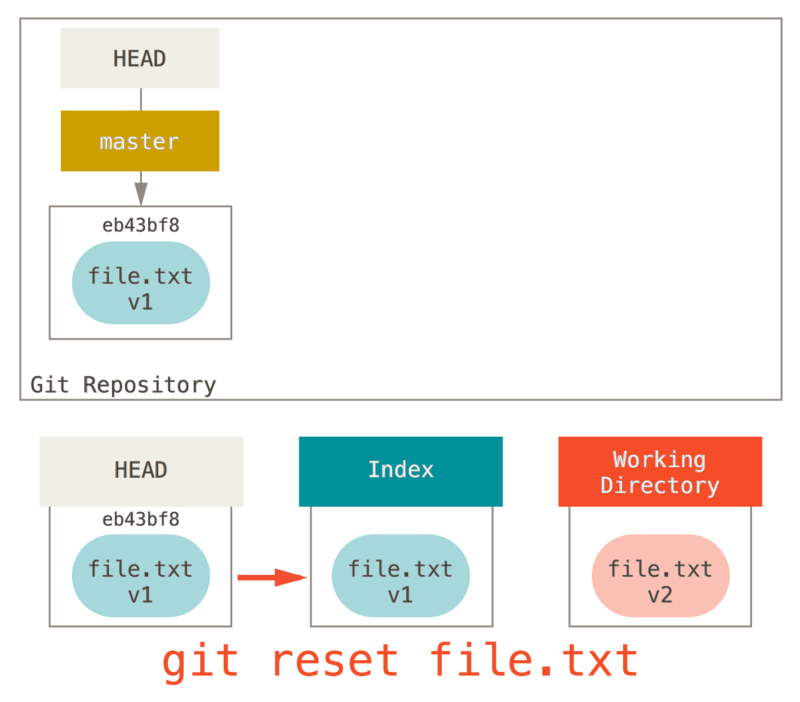
同時に、このコマンドは指定したファイルをステージされていない状態に戻す( unstage )、ということでもあります。
上の図(リセットコマンドを図示したもの)を念頭におきつつ、git add の挙動を考えてみてください。真逆であることがわかるはずです。
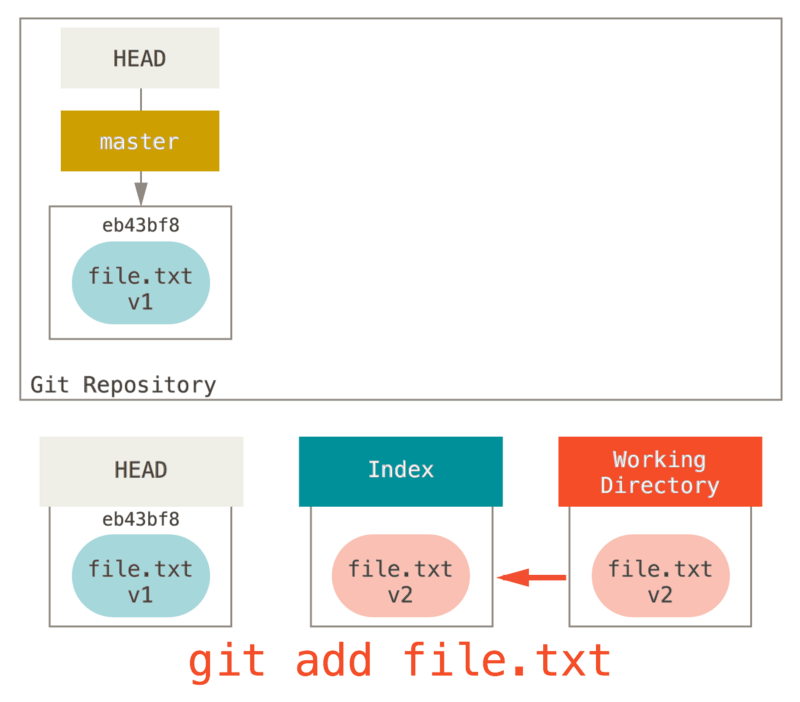
なお、ファイルをステージされていない状態に戻したいときはこのリセットコマンドを実行するよう、 git status コマンドの出力には書かれています。その理由は、リセットコマンドが上述のような挙動をするからなのです。
(詳細は ステージしたファイルの取り消し を確認してください)。
「HEAD のデータが欲しい」という前提で処理が行われるのを回避することもできます。とても簡単で、必要なデータを含むコミットを指定するだけです。
git reset eb43bf file.txt のようなコマンドになります。
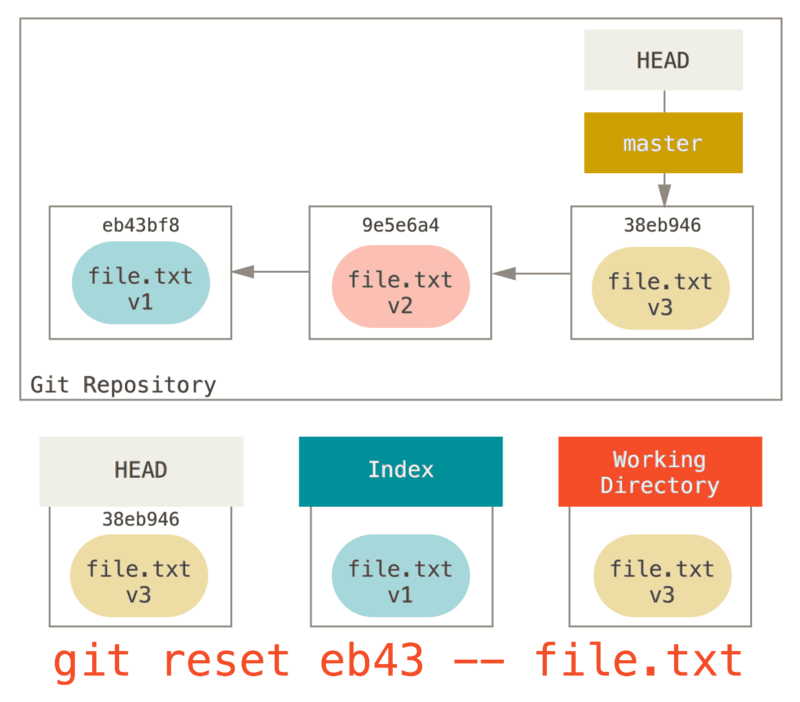
これを実行すると、作業ディレクトリ上の file.txt が v1 の状態に戻り、git add が実行されたあと、作業ディレクトリの状態が v3 に戻る、のと同じことが起こります(実際にそういった手順で処理されるわけではありませんが)。
さらに git commit を実行してみましょう。すると、作業ディレクトリ上の状態をまた v1 に戻したわけではないのに、該当のファイルを v1 に戻す変更がコミットされます。
もうひとつ、覚えておくべきことを紹介します。 git add などと同じように、reset コマンドにも --patch オプションがあります。これを使うと、ステージした内容を塊ごとに作業ディレクトリに戻せます。
つまり、一部分だけを作業ディレクトリに戻したり以前の状態に巻き戻したりできるわけです。
reset を使ったコミットのまとめ
本節で学んだ方法を使う、気になる機能を紹介します。コミットのまとめ機能です。
「凡ミス」「WIP」「ファイル追加忘れ」のようなメッセージのコミットがいくつも続いたとします。
そんなときは reset を使いましょう。すっきりと一つにまとめられます
(別の手段を コミットのまとめ で紹介していますが、今回の例では reset の方がわかりやすいと思います)。
ここで、最初のコミットはファイル数が1、次のコミットでは最初からあったファイルの変更と新たなファイルの追加、その次のコミットで最初からあったファイルをまた変更、というコミット履歴を経てきたプロジェクトがあったとします。 二つめのコミットは作業途中のもの(WIP)だったので、どこかにまとめてしまいましょう。
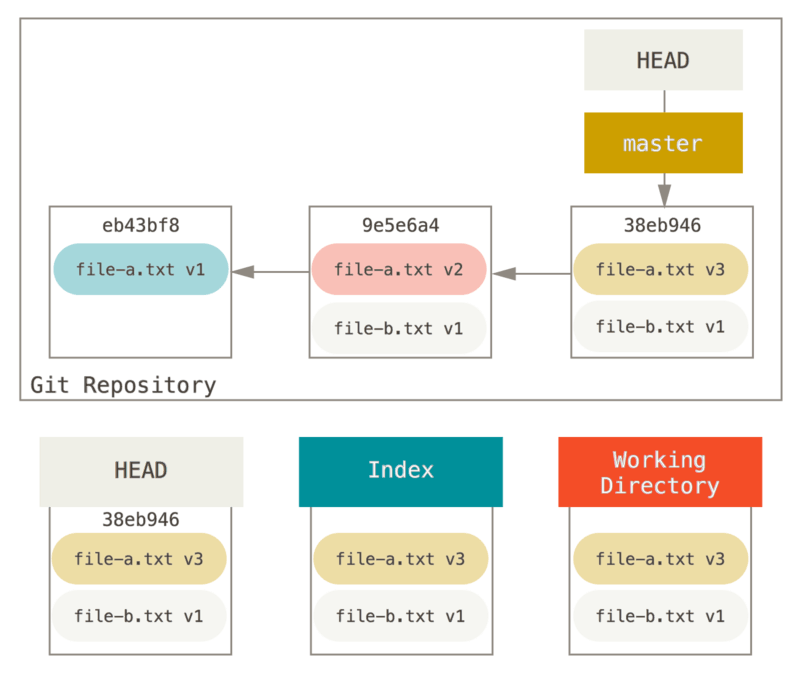
まず、git reset --soft HEAD~2 を実行して HEAD を過去のコミット(消したくはないコミットのうち古い方)へと移動させます。
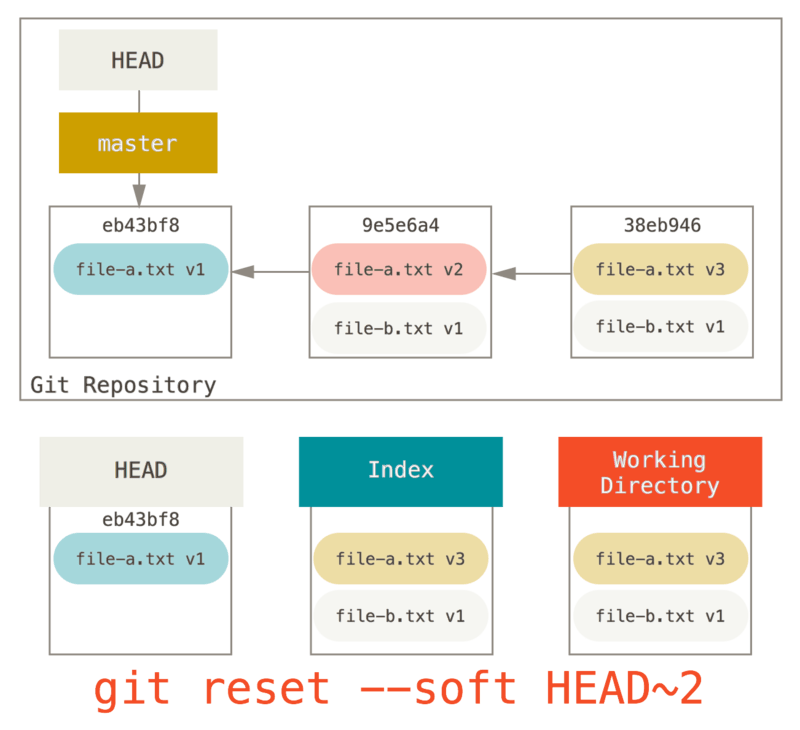
そうしたら、あとは git commit を実行するだけです。
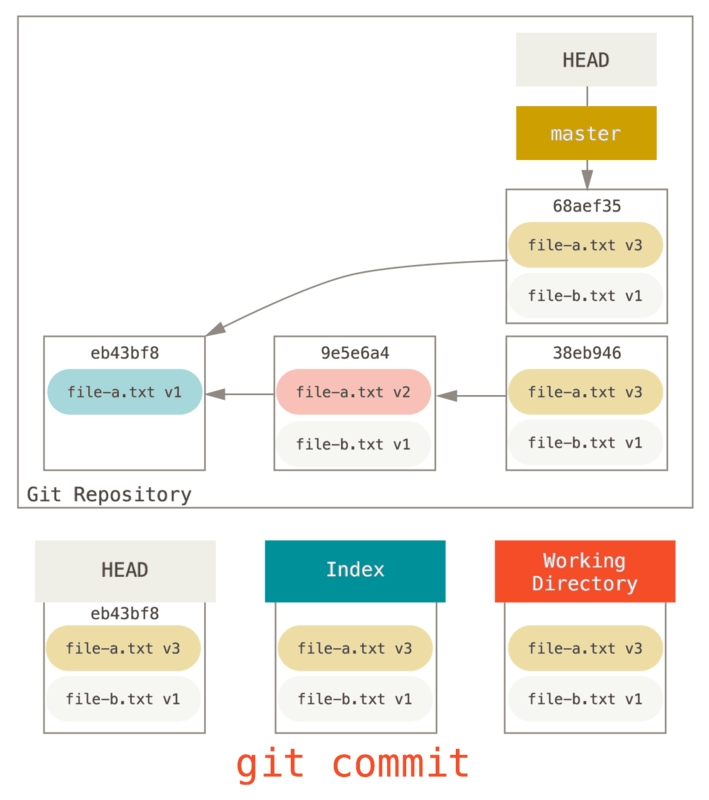
こうしてしまえば、1つめのコミットで file-a.txt v1 が追加され、2つめのコミットで file-a.txt が v3 に変更され file-b.txt が追加された、というコミット履歴が到達可能な歴史(プッシュすることになる歴史)になります。file-a.txt を v2 に変更したコミットを歴史から取り除くことができました。
チェックアウトとの違い
最後に、checkout と reset の違いについて触れておきます。
3つのツリーを操作する、という意味では checkout は reset と同様です。けれど、コマンド実行時にファイルパスを指定するかどうかによって、少し違いがでてきます。
パス指定なしの場合
git checkout [branch] と git reset --hard [branch] の挙動は似ています。どちらのコマンドも、3つのツリーを [branch] の状態に変更するからです。ただし、大きな違いが2点あります。
まず、reset --hard とは違い、checkout は作業ディレクトリを守ろうとします。作業ディレクトリの内容を上書きしてしまう前に、未保存の変更がないかをチェックしてくれるのです。
さらに詳しく見てみると、このコマンドはもっと親切なことがわかります。作業ディレクトリのファイルに対し、“trivial” なマージを試してくれるのです。うまくいけば、未変更 のファイルはすべて更新されます。
一方、reset --hard の場合、このようなチェックは行わずにすべてが上書きされます。
もうひとつの違いは、HEAD の更新方法です。
reset の場合はブランチの方が移動するのに対し、checkout の場合は HEAD のそのものが別ブランチに移動します。
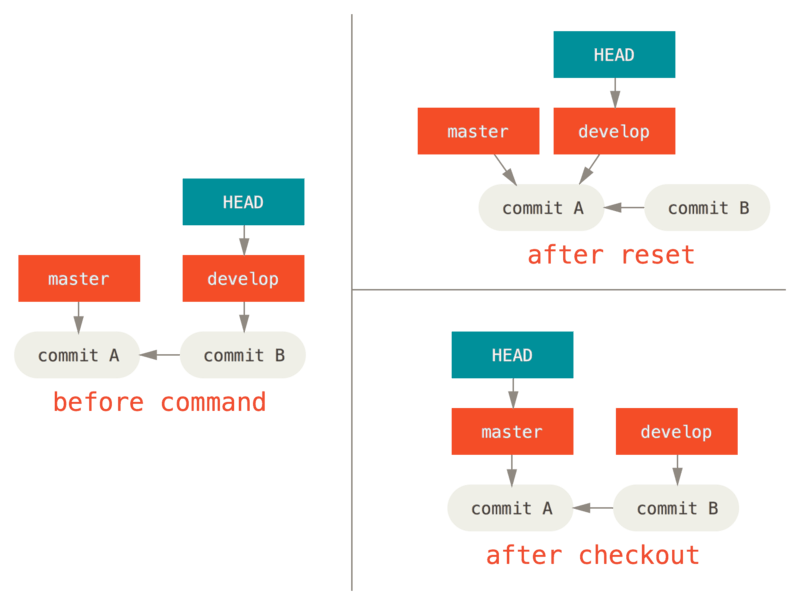
具体例を挙げて説明しましょう。master と develop の2つのブランチが異なるコミットを指し示していて、develop の方をチェックアウトしているとします(HEAD は後者の方を向いた状態です)。
ここで git reset master を実行すると、master ブランチの最新のコミットを develop ブランチも指し示すようになります。
ですが、代わりに git checkout master を実行しても、develop ブランチは移動しません。HEAD が移動するのです。
その結果、HEAD は master の方を指し示すようになります。
どちらの場合でも HEAD がコミット A を指すようになるという意味では同じですが、どのように それが行われるかはずいぶん違います。
reset の場合は HEAD が指し示すブランチの方が移動するのに対し、checkout の場合は HEAD そのものが移動するのです。
パス指定ありの場合
checkout はパスを指定して実行することも出来ます。その場合、reset と同様、HEAD が動くことはありません。
実行されると指定したコミットの指定したファイルでインデックスの内容を置き換えます。git reset [branch] file と同じ動きです。しかし、checkout の場合は、さらに作業ディレクトリのファイルも置き換えます。
git reset --hard [branch] file を実行しても、まったく同じ結果になるでしょう(実際には reset ではこういうオプションの指定はできません)。作業ディレクトリを保護してはくれませんし、HEAD が動くこともありません。
また、checkout にも git reset や git add のように --patch オプションがあります。これを使えば、変更点を部分ごとに巻き戻していけます。
まとめ
これまでの説明で reset コマンドについての不安は解消されたでしょうか。checkout との違いがまだまだ曖昧かもしれません。実行の仕方が多すぎて、違いを覚えるのは無理と言っても言い過ぎではないはずです。
どのコマンドがどのツリーを操作するか、以下の表にまとめておきました。 “HEAD” の列は、該当のコマンドが HEAD が指し示すブランチの位置を動かす場合は “REF”、動くのが HEAD そのものの場合は “HEAD” としてあります。 「作業ディレクトリ保護の有無」の列はよく見ておいてください。その列が いいえ の場合は、実行結果をよくよく踏まえてからコマンドを実行するようにしてください。
| HEAD | インデックス | 作業ディレクトリ | 作業ディレクトリ保護の有無 | |
|---|---|---|---|---|
Commit Level |
||||
|
REF |
いいえ |
いいえ |
はい |
|
REF |
はい |
いいえ |
はい |
|
REF |
はい |
はい |
いいえ |
|
HEAD |
はい |
はい |
はい |
File Level |
||||
|
いいえ |
はい |
いいえ |
はい |
|
いいえ |
はい |
はい |
いいえ |