
-
1. Pierwsze kroki
- 1.1 Wprowadzenie do kontroli wersji
- 1.2 Krótka historia Git
- 1.3 Podstawy Git
- 1.4 Linia poleceń
- 1.5 Instalacja Git
- 1.6 Wstępna konfiguracja Git
- 1.7 Uzyskiwanie pomocy
- 1.8 Podsumowanie
-
2. Podstawy Gita
- 2.1 Pierwsze repozytorium Gita
- 2.2 Rejestrowanie zmian w repozytorium
- 2.3 Podgląd historii rewizji
- 2.4 Cofanie zmian
- 2.5 Praca ze zdalnym repozytorium
- 2.6 Tagowanie
- 2.7 Aliasy
- 2.8 Podsumowanie
-
3. Gałęzie Gita
- 3.1 Czym jest gałąź
- 3.2 Podstawy rozgałęziania i scalania
- 3.3 Zarządzanie gałęziami
- 3.4 Sposoby pracy z gałęziami
- 3.5 Gałęzie zdalne
- 3.6 Zmiana bazy
- 3.7 Podsumowanie
-
4. Git na serwerze
- 4.1 Protokoły
- 4.2 Uruchomienie Git na serwerze
- 4.3 Generowanie Twojego publicznego klucza SSH
- 4.4 Konfigurowanie serwera
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Inne opcje hostowania przez podmioty zewnętrzne
- 4.10 Podsumowanie
-
5. Rozproszony Git
-
6. GitHub
-
7. Narzędzia Gita
- 7.1 Wskazywanie rewizji
- 7.2 Interaktywne używanie przechowali
- 7.3 Schowek i czyszczenie
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Przepisywanie historii
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugowanie z Gitem
- 7.11 Moduły zależne
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Podsumowanie
-
8. Dostosowywanie Gita
- 8.1 Konfiguracja Gita
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git i inne systemy
- 9.1 Git jako klient
- 9.2 Migracja do Gita
- 9.3 Podsumowanie
-
10. Mechanizmy wewnętrzne w Git
- 10.1 Komendy typu plumbing i porcelain
- 10.2 Obiekty Gita
- 10.3 Referencje w Git
- 10.4 Spakowane pliki (packfiles)
- 10.5 Refspec
- 10.6 Protokoły transferu
- 10.7 Konserwacja i odzyskiwanie danych
- 10.8 Environment Variables
- 10.9 Podsumowanie
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
3.1 Gałęzie Gita - Czym jest gałąź
Prawie każdy system kontroli wersji posiada wsparcie dla gałęzi. Rozgałęzienie oznacza odbicie od głównego pnia linii rozwoju i kontynuację pracy bez wprowadzania tam bałaganu. W wielu narzędziach kontroli wersji jest to proces dość kosztowny, często wymagający utworzenia nowej kopii katalogu z kodem, co w przypadku dużych projektów może zająć sporo czasu.
Niektórzy uważają model gałęzi Gita za jego „killer feature” i z całą pewnością wyróżnia go spośród innych narzędzi tego typu. Co w nim specjalnego? Sposób, w jaki Git obsługuje gałęzie, jest niesamowicie lekki, przez co tworzenie nowych gałęzi jest niemalże natychmiastowe, a przełączanie się pomiędzy nimi trwa niewiele dłużej. W odróżnieniu od wielu innych systemów, Git zachęca do częstego rozgałęziania i scalania projektu, nawet kilkukrotnie w ciągu jednego dnia. Zrozumienie i opanowanie tego wyjątkowego i potężnego mechanizmu może dosłownie zmienić sposób, w jaki pracujesz.
Czym jest gałąź
Żeby naprawdę zrozumieć sposób, w jaki Git obsługuje gałęzie, trzeba cofnąć się o krok i przyjrzeć temu, w jaki sposób Git przechowuje dane.
Jak może pamiętasz z rozdziału Pierwsze kroki, Git nie przechowuje danych jako serii zmian i różnic, ale jako zestaw migawek.
Kiedy zatwierdzasz zmiany w Gicie, ten zapisuje obiekt zmian (commit), który z kolei zawiera wskaźnik na migawkę zawartości, która w danej chwili znajduje się w poczekalni, metadane autora i opisu oraz zero lub więcej wskaźników na zmiany, które były bezpośrednimi rodzicami zmiany właśnie zatwierdzanej: brak rodziców w przypadku pierwszej, jeden w przypadku zwykłej, oraz kilka w przypadku zmiany powstałej wskutek scalenia dwóch lub więcej gałęzi.
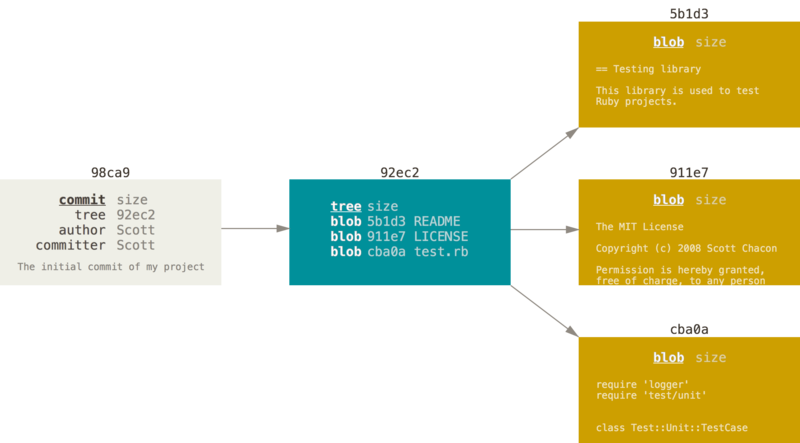
Aby lepiej to zobrazować, załóżmy, że posiadasz katalog zawierający trzy pliki, które umieszczasz w poczekalni, a następnie zatwierdzasz zmiany. Umieszczenie w poczekalni plików powoduje wyliczenie sumy kontrolnej każdego z nich (skrótu SHA-1 wspomnianego w rozdziale Pierwsze kroki), zapisanie wersji plików w repozytorium (Git nazywa je blobami) i dodanie sumy kontrolnej do poczekalni:
$ git add README test.rb LICENSE
$ git commit -m 'initial commit of my project'Kiedy zatwierdzasz zmiany przez uruchomienie polecenia git commit, Git liczy sumę kontrolną każdego podkatalogu (w tym wypadku tylko głównego katalogu projektu) i zapisuje te trzy obiekty w repozytorium. Następnie tworzy obiekt zestawu zmian (commit), zawierający metadane oraz wskaźnik na główne drzewo projektu, co w razie potrzeby umożliwi odtworzenie całej migawki.
Teraz repozytorium Gita zawiera już 5 obiektów: jeden blob dla zawartości każdego z trzech plików, jedno drzewo opisujące zawartość katalogu i określające, które pliki przechowywane są w których blobach, oraz jeden zestaw zmian ze wskaźnikiem na owo drzewo i wszystkimi metadanymi.
Jeżeli dodasz kilka zmian i zatwierdzisz je ponownie, kolejny commit będzie zawierał wskaźnik do commita poprzedniego.
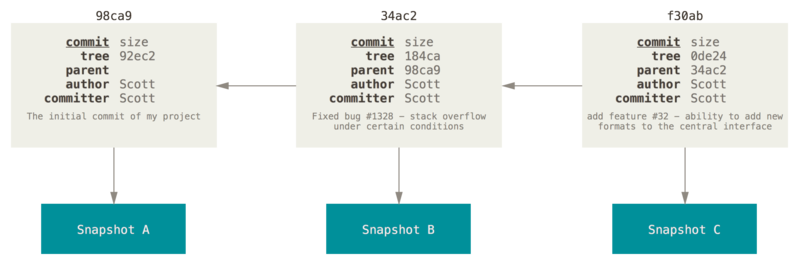
Gałąź w Gicie jest po prostu lekkim, przesuwalnym wskaźnikiem na któryś z owych zestawów zmian. Domyślna nazwa gałęzi Gita to master. Kiedy zatwierdzasz pierwsze zmiany, otrzymujesz gałąź master, która wskazuje na ostatni zatwierdzony przez Ciebie zestaw. Z każdym zatwierdzeniem automatycznie przesuwa się ona do przodu.
|
Uwaga
|
Gałąź “master” nie jest specjalną gałęzią.
Jest dokładnie taka sama jak pozostałe.
Jedynym powodem dla którego każde repozytorium ją posiada jest to, że
polecenie |
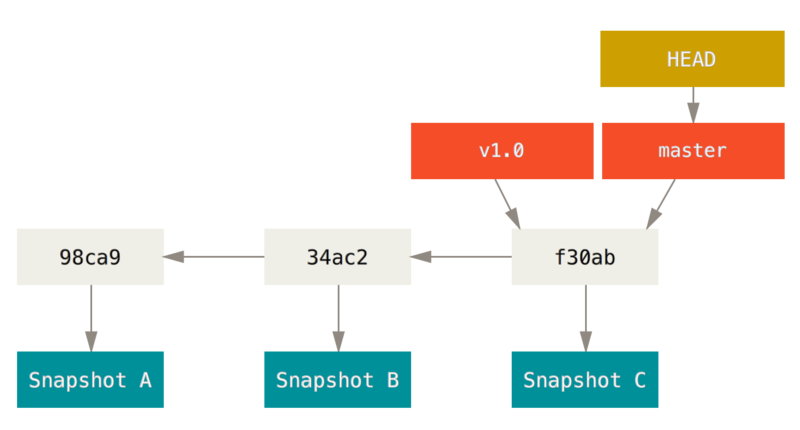
Tworzenie nowej gałęzi
Co się stanie, jeśli utworzysz nową gałąź? Cóż, utworzony zostanie nowy wskaźnik, który następnie będziesz mógł przesuwać. Powiedzmy, że tworzysz nową gałąź o nazwie testing. Zrobisz to za pomocą polecenia git branch::
$ git branch testingPolecenie to tworzy nowy wskaźnik na ten sam zestaw zmian, w którym aktualnie się znajdujesz.
Skąd Git wie, na której gałęzi się aktualnie znajdujesz? Utrzymuje on specjalny wskaźnik o nazwie HEAD. Istotnym jest, że bardzo różni się on od koncepcji HEADa znanej z innych systemów kontroli wersji, do jakich mogłeś się już przyzwyczaić, na przykład Subversion czy CVS. W Gicie jest to wskaźnik na lokalną gałąź, na której właśnie się znajdujesz. W tym wypadku, wciąż jesteś na gałęzi master. Polecenie git branch utworzyło jedynie nową gałąź, ale nie przełączyło cię na nią.
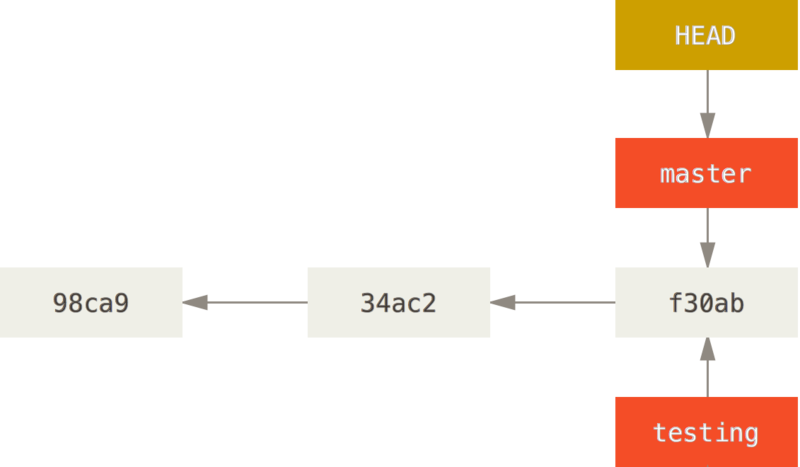
Możesz z łatwością to sprawdzić wywołując polecenie git log które pokaże Ci gdzie znajdują się wskazniki. Ta opcja to --decorate.
You can easily see this by running a simple git log command that shows you where the branch pointers are pointing. This option is called --decorate.
$ git log --oneline --decorate
f30ab (HEAD, master, testing) add feature #32 - ability to add new
34ac2 fixed bug #1328 - stack overflow under certain conditions
98ca9 initial commit of my projectWidzisz, że gałęzie “master” i “testing” znajdują się zaraz obok commitu f30ab.
Przełączanie gałęzi
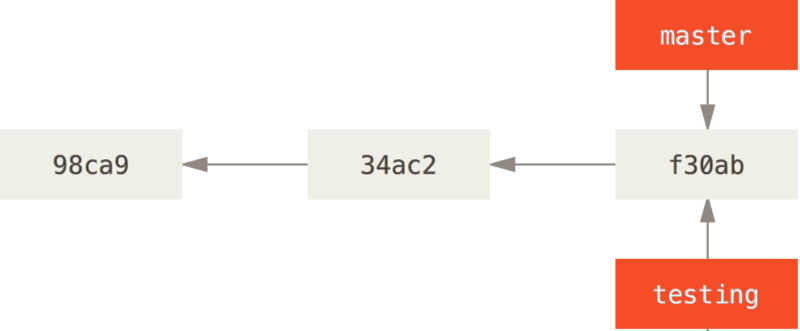
Aby przełączyć się na istniejącą gałąź, używasz polecenia git checkout.
Przełączmy się zatem do nowo utworzonej gałęzi testing:
$ git checkout testingHEAD zostaje zmieniony tak, by wskazywać na gałąź testing.
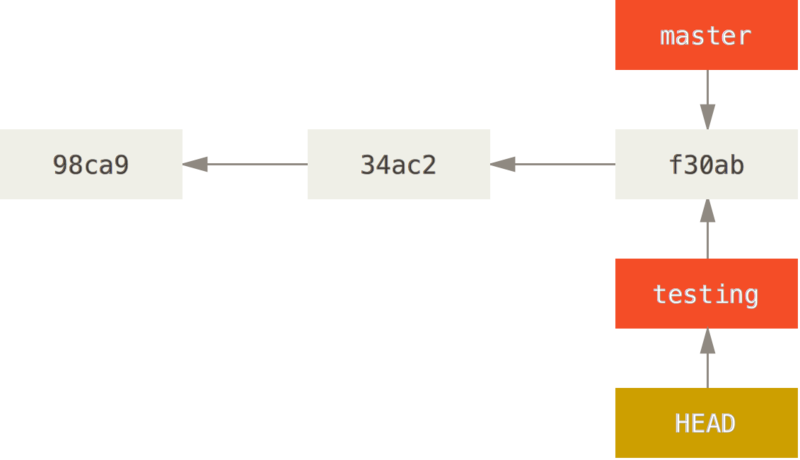
Jakie ma to znaczenie? Zatwierdźmy nowe zmiany:
$ vim test.rb
$ git commit -a -m 'made a change'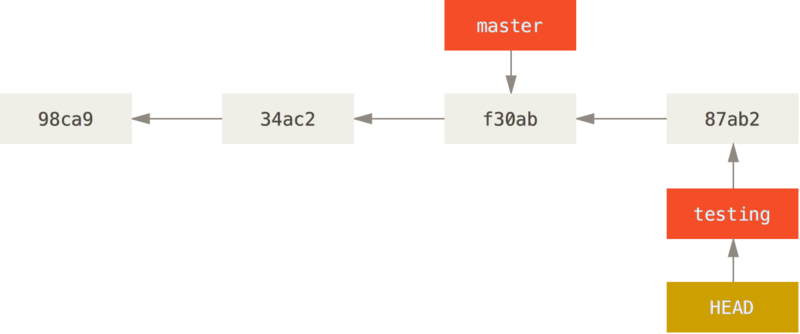
To interesujące, bo teraz Twoja gałąź testing przesunęła się do przodu, jednak gałąź master ciągle wskazuje ten sam zestaw zmian, co w momencie użycia git checkout do zmiany aktywnej gałęzi.
Przełączmy się zatem z powrotem na gałąź master:
$ git checkout master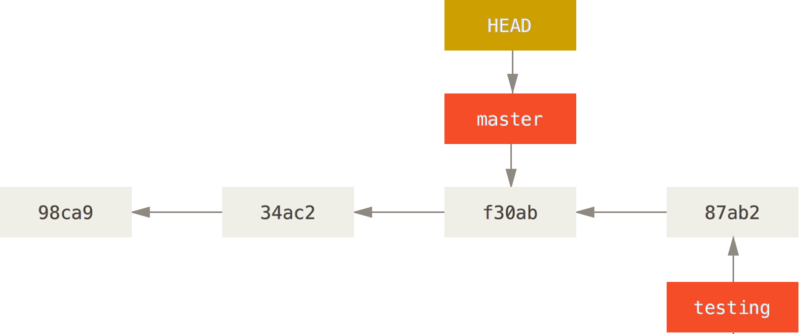
Polecenie dokonało dwóch rzeczy. Przesunęło wskaźnik HEAD z powrotem na gałąź master i przywróciło pliki w katalogu roboczym do stanu z migawki, na którą wskazuje master. Oznacza to również, że zmiany, które od tej pory wprowadzisz, będą rozwidlały się od starszej wersji projektu. W gruncie rzeczy cofa to tymczasowo pracę, jaką wykonałeś na gałęzi testing, byś mógł z dalszymi zmianami pójść w innym kierunku.
|
Uwaga
|
Przełączanie gałęzi zmienia pliki w katalogu roboczym
Ważne jest to, że kiedy przełączasz gałąź w Git, pliki zmieniają się w twoim katalogu roboczym. Jeśli przełączysz się na starszą gałąź twój katalog roboczy zostanie cofnięty tak aby wyglądał jak w chwili zatwierdzenia ostatniej zmiany na tej gałęzi. Jeśli git nie może zrobić tego gładko, to nie pozwoli ci na przełączenie. |
Wykonajmy teraz kilka zmian i zatwierdźmy je:
$ vim test.rb
$ git commit -a -m 'made other changes'Teraz historia Twojego projektu została rozszczepiona (zobacz Rozwidlona historia gałęzi).
Stworzyłeś i przełączyłeś się na gałąź, wykonałeś na niej pracę, a następnie powróciłeś na gałąź główną i wykonałeś inną pracę. Oba zestawy zmian są od siebie odizolowane w odrębnych gałęziach: możesz przełączać się pomiędzy nimi oraz scalić je razem, kiedy będziesz na to gotowy. A wszystko to wykonałeś za pomocą prostych poleceń branch i checkout i commit.
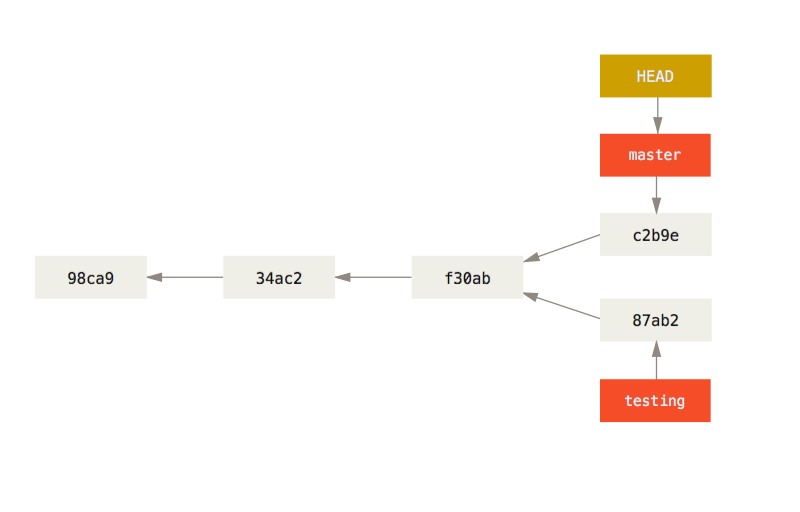
Możesz również zobaczyć to w prosty sposób z poleceniem git log.
Wywołując git log --oneline --decorate --graph --all uzyskasz historię twoich zmian, pokazując gdzie znajdują się wskaźniki gałęzi i jak twoja historia została rozwidlona.
$ git log --oneline --decorate --graph --all
* c2b9e (HEAD, master) made other changes
| * 87ab2 (testing) made a change
|/
* f30ab add feature #32 - ability to add new formats to the
* 34ac2 fixed bug #1328 - stack overflow under certain conditions
* 98ca9 initial commit of my projectPonieważ gałęzie w Gicie są tak naprawdę prostymi plikami, zawierającymi 40 znaków sumy kontrolnej SHA-1 zestawu zmian, na który wskazują, są one bardzo tanie w tworzeniu i usuwaniu. Stworzenie nowej gałęzi zajmuje dokładnie tyle czasu, co zapisanie 41 bajtów w pliku (40 znaków + znak nowej linii).
Wyraźnie kontrastuje to ze sposobem, w jaki gałęzie obsługuje większość narzędzi do kontroli wersji, gdzie z reguły w grę wchodzi kopiowanie wszystkich plików projektu do osobnego katalogu. Może to trwać kilkanaście sekund czy nawet minut, w zależności od rozmiarów projektu, podczas gdy w Gicie jest zawsze natychmiastowe. Co więcej, ponieważ wraz z każdym zestawem zmian zapamiętujemy jego rodziców, odnalezienie wspólnej bazy przed scaleniem jest automatycznie wykonywane za nas i samo w sobie jest niezwykle proste. Możliwości te pomagają zachęcić deweloperów do częstego tworzenia i wykorzystywania gałęzi.
Zobaczmy, dlaczego ty też powinieneś.