
-
1. Erste Schritte
-
2. Git Grundlagen
-
3. Git Branching
- 3.1 Branches auf einen Blick
- 3.2 Einfaches Branching und Merging
- 3.3 Branch-Management
- 3.4 Branching-Workflows
- 3.5 Remote-Branches
- 3.6 Rebasing
- 3.7 Zusammenfassung
-
4. Git auf dem Server
- 4.1 Die Protokolle
- 4.2 Git auf einem Server einrichten
- 4.3 Erstellung eines SSH-Public-Keys
- 4.4 Einrichten des Servers
- 4.5 Git-Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Von Drittanbietern gehostete Optionen
- 4.10 Zusammenfassung
-
5. Verteiltes Git
-
6. GitHub
-
7. Git Tools
- 7.1 Revisions-Auswahl
- 7.2 Interaktives Stagen
- 7.3 Stashen und Bereinigen
- 7.4 Deine Arbeit signieren
- 7.5 Suchen
- 7.6 Den Verlauf umschreiben
- 7.7 Reset entzaubert
- 7.8 Fortgeschrittenes Merging
- 7.9 Rerere
- 7.10 Debuggen mit Git
- 7.11 Submodule
- 7.12 Bundling
- 7.13 Replace (Ersetzen)
- 7.14 Anmeldeinformationen speichern
- 7.15 Zusammenfassung
-
8. Git einrichten
- 8.1 Git Konfiguration
- 8.2 Git-Attribute
- 8.3 Git Hooks
- 8.4 Beispiel für Git-forcierte Regeln
- 8.5 Zusammenfassung
-
9. Git und andere VCS-Systeme
- 9.1 Git als Client
- 9.2 Migration zu Git
- 9.3 Zusammenfassung
-
10. Git Interna
-
A1. Anhang A: Git in anderen Umgebungen
- A1.1 Grafische Schnittstellen
- A1.2 Git in Visual Studio
- A1.3 Git in Visual Studio Code
- A1.4 Git in IntelliJ / PyCharm / WebStorm / PhpStorm / RubyMine
- A1.5 Git in Sublime Text
- A1.6 Git in Bash
- A1.7 Git in Zsh
- A1.8 Git in PowerShell
- A1.9 Zusammenfassung
-
A2. Anhang B: Git in deine Anwendungen einbetten
- A2.1 Die Git-Kommandozeile
- A2.2 Libgit2
- A2.3 JGit
- A2.4 go-git
- A2.5 Dulwich
-
A3. Anhang C: Git Kommandos
- A3.1 Setup und Konfiguration
- A3.2 Projekte importieren und erstellen
- A3.3 Einfache Snapshot-Funktionen
- A3.4 Branching und Merging
- A3.5 Projekte gemeinsam nutzen und aktualisieren
- A3.6 Kontrollieren und Vergleichen
- A3.7 Debugging
- A3.8 Patchen bzw. Fehlerkorrektur
- A3.9 E-mails
- A3.10 Externe Systeme
- A3.11 Administration
- A3.12 Basisbefehle
1.1 Erste Schritte - Was ist Versionsverwaltung?
In diesem Kapitel geht es um den Einstieg in Git. Wir erklären zunächst einige Hintergrundinformationen zu Versionskontrolltools, gehen dann dazu über, wie du Git auf deinem System zum Laufen bringst und wie du es schließlich so einrichtest, dass du damit arbeiten kannst. Am Ende dieses Kapitels solltest du verstehen, wozu Git gut ist und weshalb man es verwenden sollte. Du solltest dann in der Lage sein, mit deiner Arbeit in Git loslegen zu können.
Was ist Versionsverwaltung?
Was ist „Versionsverwaltung“, und warum solltest du dich dafür interessieren? Versionsverwaltung ist ein System, welches die Änderungen an einer oder einer Reihe von Dateien über die Zeit hinweg protokolliert, sodass man später auf eine bestimmte Version zurückgreifen kann. Die Dateien, die in den Beispielen in diesem Buch unter Versionsverwaltung gestellt werden, enthalten Quelltext von Software. Tatsächlich kann in der Praxis nahezu jede Art von Datei per Versionsverwaltung nachverfolgt werden.
Wenn du Grafik- oder Webdesigner bist und jede Version eines Bildes oder Layouts behalten möchtest (was Du mit Sicherheit möchtest), ist die Verwendung eines Versionskontrollsystems (VCS) eine sehr kluge Sache. Damit kannst du ausgewählte Dateien auf einen früheren Zustand zurücksetzen, das gesamte Projekt auf einen früheren Zustand zurücksetzen, zurückliegende Änderungen vergleichen, sehen wer zuletzt etwas geändert hat, das möglicherweise ein Problem verursacht, wer wann ein Problem verursacht hat und vieles mehr. Die Verwendung eines VCS bedeutet im Allgemeinen auch, dass du problemlos eine Wiederherstellung durchführen könntest, wenn etwas kaputt geht oder Dateien verloren gehen. All diese Vorteile erhält man mit einen nur sehr geringen zusätzlichen Aufwand.
Lokale Versionsverwaltung
Viele Menschen betreiben Versionsverwaltung, indem sie einfach all ihre Dateien in ein separates Verzeichnis kopieren (die Schlaueren darunter verwenden ein Verzeichnis mit Zeitstempel im Namen). Dieser Ansatz ist sehr verbreitet, weil er so einfach ist, aber auch unglaublich fehleranfällig. Man arbeitet sehr leicht im falschen Verzeichnis, bearbeitet damit die falschen Dateien oder überschreibt Dateien, die man eigentlich nicht überschreiben wollte.
Aus diesem Grund, haben Programmierer bereits vor langer Zeit lokale Versionsverwaltungssysteme entwickelt, die alle Änderungen an allen relevanten Dateien in einer Datenbank verwalten.
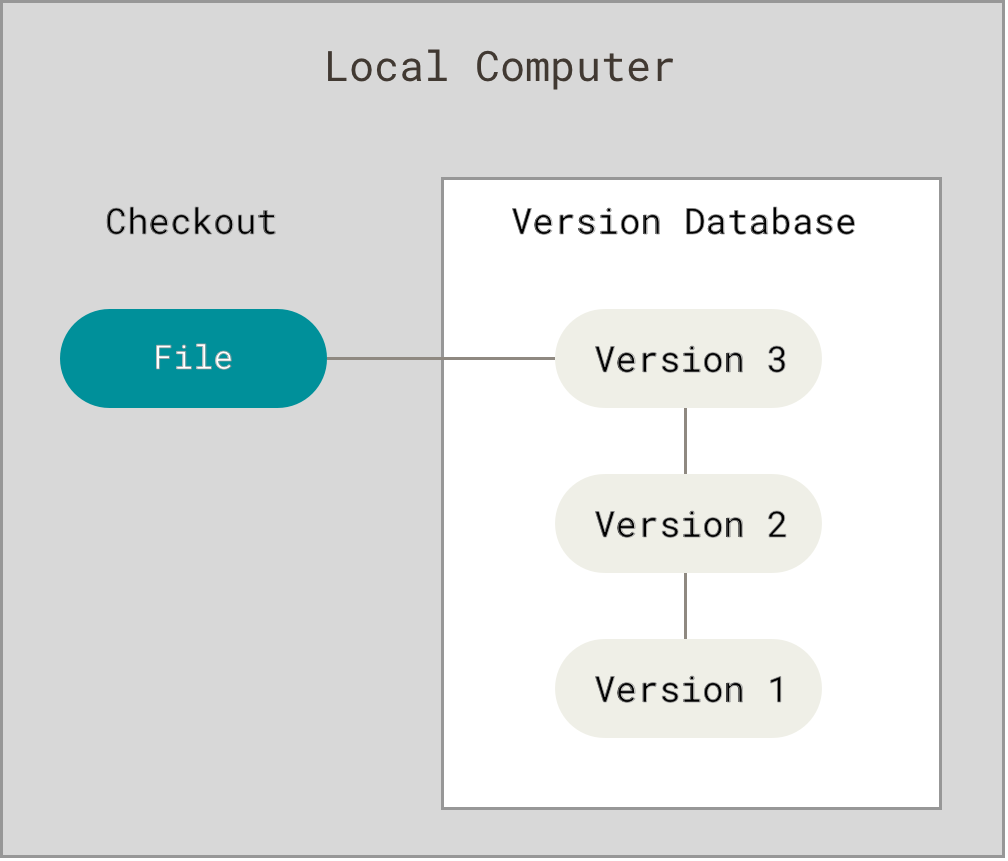
Eines der populäreren Versionsverwaltungssysteme war RCS, welches auch heute noch mit vielen Computern ausgeliefert wird. RCS arbeitet nach dem Prinzip, dass für jede Änderung ein Patch (ein Patch umfasst alle Änderungen an einer oder mehreren Dateien) in einem speziellen Format auf der Festplatte gespeichert wird. Um eine bestimmte Version einer Datei wiederherzustellen, wendet es alle Patches bis zur gewünschten Version an und rekonstruiert damit die Datei in der gewünschten Version.
Zentrale Versionsverwaltung
Ein weiteres großes Problem, mit dem sich viele Leute konfrontiert sahen, bestand in der Zusammenarbeit mit anderen Entwicklern auf anderen Systemen. Um dieses Problem zu lösen, wurden zentralisierte Versionsverwaltungssysteme entwickelt (engl. Centralized Version Control System, CVCS). Diese Systeme, wozu beispielsweise CVS, Subversion und Perforce gehören, basieren auf einem zentralen Server, der alle versionierte Dateien verwaltet. Die Clients können die Dateien von diesem zentralen Ort abholen und auf ihren PC übertragen. Den Vorgang des Abholens nennt man Auschecken (engl. to check out). Diese Art von System war über viele Jahre hinweg der Standard für Versionsverwaltungssysteme.
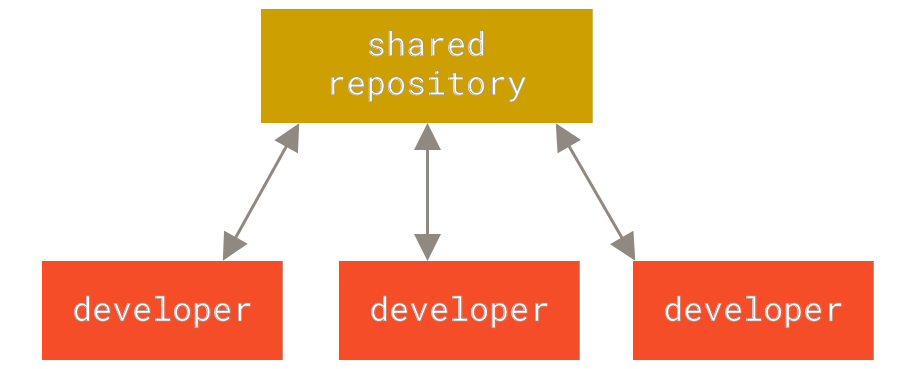
Dieser Ansatz hat viele Vorteile, besonders gegenüber lokalen Versionsverwaltungssystemen. Zum Beispiel weiß jeder mehr oder weniger genau darüber Bescheid, was andere an einem Projekt Beteiligte gerade tun. Administratoren haben die Möglichkeit, detailliert festzulegen, wer was tun kann. Und es ist sehr viel einfacher, ein CVCS zu administrieren als lokale Datenbanken auf jedem einzelnen Anwenderrechner zu verwalten.
Allerdings hat dieser Aufbau auch einige erhebliche Nachteile. Der offensichtlichste Nachteil ist das Risiko eines Systemausfalls bei Ausfall einer einzelnen Komponente, d.h. wenn der zentrale Server ausfällt. Wenn dieser Server nur für eine Stunde nicht verfügbar ist, dann kann in dieser einen Stunde niemand in irgendeiner Form mit anderen zusammenarbeiten oder Dateien, an denen gerade gearbeitet wird, versioniert abspeichern. Wenn die auf dem zentralen Server eingesetzte Festplatte beschädigt wird und keine Sicherheitskopien erstellt wurden, dann sind all diese Daten unwiederbringlich verloren – die komplette Historie des Projektes, abgesehen natürlich von dem jeweiligen Zustand, den Mitstreiter gerade zufällig auf ihrem Rechner noch vorliegen haben. Lokale Versionskontrollsysteme haben natürlich dasselbe Problem: Wenn man die Historie eines Projektes an einer einzigen, zentralen Stelle verwaltet, riskiert man, sie vollständig zu verlieren, wenn irgendetwas an dieser zentralen Stelle schief läuft.
Verteilte Versionsverwaltung
Und an dieser Stelle kommen verteilte Versionsverwaltungssysteme (engl. Distributed Version Control System, DVCS) ins Spiel. In einem DVCS (wie z.B. Git, Mercurial, Bazaar oder Darcs) erhalten Anwender nicht einfach nur den jeweils letzten Zustand des Projektes von einem Server: Sie erhalten stattdessen eine vollständige Kopie des Repositories. Auf diese Weise kann, wenn ein Server beschädigt wird, jedes beliebige Repository von jedem beliebigen Anwenderrechner zurückkopiert werden und der Server so wiederhergestellt werden. Jede Kopie, ein sogenannter Klon (engl. clone), ist ein vollständiges Backup der gesamten Projektdaten.
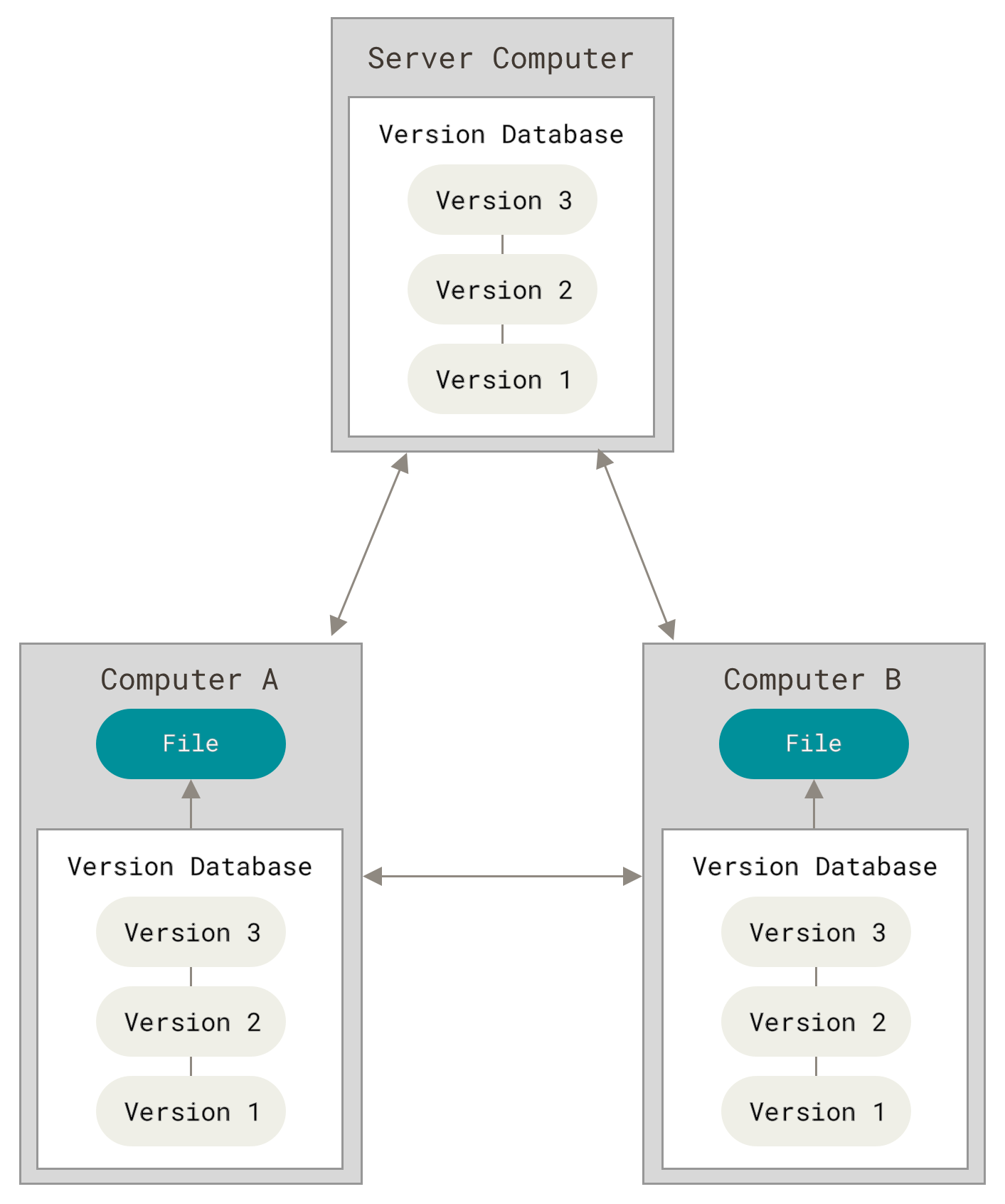
Darüber hinaus können derartige Systeme hervorragend mit verschiedenen externen Repositories, sogenannten Remote-Repositories, umgehen, sodass man mit verschiedenen Gruppen von Leuten simultan auf verschiedene Art und Weise an einem Projekt zusammenarbeiten kann. Damit ist es möglich, verschiedene Arten von Arbeitsabläufen zu erstellen und anzuwenden, welche mit zentralisierten Systemen nicht möglich wären. Dazu gehören zum Beispiel hierarchische Arbeitsabläufe.