
-
1. Pierwsze kroki
- 1.1 Wprowadzenie do kontroli wersji
- 1.2 Krótka historia Git
- 1.3 Podstawy Git
- 1.4 Linia poleceń
- 1.5 Instalacja Git
- 1.6 Wstępna konfiguracja Git
- 1.7 Uzyskiwanie pomocy
- 1.8 Podsumowanie
-
2. Podstawy Gita
- 2.1 Pierwsze repozytorium Gita
- 2.2 Rejestrowanie zmian w repozytorium
- 2.3 Podgląd historii rewizji
- 2.4 Cofanie zmian
- 2.5 Praca ze zdalnym repozytorium
- 2.6 Tagowanie
- 2.7 Aliasy
- 2.8 Podsumowanie
-
3. Gałęzie Gita
- 3.1 Czym jest gałąź
- 3.2 Podstawy rozgałęziania i scalania
- 3.3 Zarządzanie gałęziami
- 3.4 Sposoby pracy z gałęziami
- 3.5 Gałęzie zdalne
- 3.6 Zmiana bazy
- 3.7 Podsumowanie
-
4. Git na serwerze
- 4.1 Protokoły
- 4.2 Uruchomienie Git na serwerze
- 4.3 Generowanie Twojego publicznego klucza SSH
- 4.4 Konfigurowanie serwera
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Inne opcje hostowania przez podmioty zewnętrzne
- 4.10 Podsumowanie
-
5. Rozproszony Git
-
6. GitHub
-
7. Narzędzia Gita
- 7.1 Wskazywanie rewizji
- 7.2 Interaktywne używanie przechowali
- 7.3 Schowek i czyszczenie
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Przepisywanie historii
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugowanie z Gitem
- 7.11 Moduły zależne
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Podsumowanie
-
8. Dostosowywanie Gita
- 8.1 Konfiguracja Gita
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git i inne systemy
- 9.1 Git jako klient
- 9.2 Migracja do Gita
- 9.3 Podsumowanie
-
10. Mechanizmy wewnętrzne w Git
- 10.1 Komendy typu plumbing i porcelain
- 10.2 Obiekty Gita
- 10.3 Referencje w Git
- 10.4 Spakowane pliki (packfiles)
- 10.5 Refspec
- 10.6 Protokoły transferu
- 10.7 Konserwacja i odzyskiwanie danych
- 10.8 Environment Variables
- 10.9 Podsumowanie
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
10.2 Mechanizmy wewnętrzne w Git - Obiekty Gita
Obiekty Gita
Git jest systemem plików zorientowanym na treść.
Super.
Ale co to oznacza?
Oznacza to, że Git u podstaw, to baza danych w której znajdują się dane i przypisane do nich klucze (ang. key-value datastore).
Możesz zapisać w niej każdy rodzaj danych, a w odpowiedzi otrzymasz klucz, dzięki któremu będziesz mógł dostać się do tych danych w każdej chwili.
Aby zademonstrować jak to działa, możesz użyć komendy hash-object, która pobiera jakieś dane, zapisuje je w katalogu .git i zwraca klucz pod którym te dane zostały zapisane.
Najpierw zainicjujesz nowe repozytorium Gita i sprawdzisz, że katalog objects jest pusty:
$ git init test
Initialized empty Git repository in /tmp/test/.git/
$ cd test
$ find .git/objects
.git/objects
.git/objects/info
.git/objects/pack
$ find .git/objects -type fGit zainicjował katalog objects oraz stworzył w nim dwa katalogi pack i info, jednak nie ma w nich żadnych plików.
Teraz zapisz jakieś dane w bazie danych Gita:
$ echo 'test content' | git hash-object -w --stdin
d670460b4b4aece5915caf5c68d12f560a9fe3e4Opcja -w wskazuje komendzie hash-object aby zapisała obiekt, w przeciwnym wypadku pokazała by tylko jaki klucz byłby użyty.
Opcja --stdin wskazuje, aby dane zostały odczytane ze standardowego wejścia; jeżeli nie podasz tej opcji, hash-object będzie wymagał podania ścieżki do pliku.
Wynikiem działania tej komendy jest 40 znakowa suma kontrolna.
Jest to skrót SHA-1 – suma kontrolna zawartości którą zapisujesz, oraz nagłówków, o których dowiesz się za chwilę.
Teraz możesz zobaczyć w jaki sposób Git zachował dane:
$ find .git/objects -type f
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Możesz zobaczyć nowy plik w katalogu objects.
W ten sposób Git początkowo zapisuje dane – jako pojedynczy plik dla każdej części danych, nazwany tak jak wyliczony skrót SHA-1 z treści danych i nagłówka.
Podkatalog jest nazwany od 2 pierwszych znaków SHA, a nazwa pliku to pozostałe 38 znaków.
Możesz pobrać dane z Gita za pomocą komendy cat-file.
Polecenie to, to coś w rodzaju szwajcarskiego scyzoryka dla inspekcji obiektów Gita.
Przekazanie opcji -p mówi cat-file, aby rozpoznała ona rodzaj przechowywanych danych i wypisała je na ekran:
$ git cat-file -p d670460b4b4aece5915caf5c68d12f560a9fe3e4
test contentTeraz, możesz dodać dane do Gita i pobrać je z powrotem. Możesz również to zrobić z danymi znajdującymi się w plikach. Dla przykładu, dodajmy plik do systemu kontroli wersji. Najpierw stwórzmy nowy plik i zapiszmy jego zawartość w bazie danych:
$ echo 'version 1' > test.txt
$ git hash-object -w test.txt
83baae61804e65cc73a7201a7252750c76066a30Następnie wprowadź nowe dane do tego pliku i zapisz ponownie:
$ echo 'version 2' > test.txt
$ git hash-object -w test.txt
1f7a7a472abf3dd9643fd615f6da379c4acb3e3aTwoja baza danych zawiera teraz dwie nowe wersje pliku, jak również początkową jego zawartość którą zapisałeś:
$ find .git/objects -type f
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4Teraz możesz cofnąć zawartość pliku do pierwszej wersji:
$ git cat-file -p 83baae61804e65cc73a7201a7252750c76066a30 > test.txt
$ cat test.txt
version 1lub drugiej wersji:
$ git cat-file -p 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a > test.txt
$ cat test.txt
version 2Ale zapamiętywanie kluczy SHA-1 dla każdej wersji nie jest praktyczne; dodatkowo nie zachowujesz nazwy pliku – tylko treść.
Ten rodzaj obiektu nazywa się "blob".
Możesz uzyskać informacje o tym jaki typ obiektu kryje się pod danym skrótem SHA-1 za pomocą cat-file -t:
$ git cat-file -t 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a
blobObiekty drzew
Następnym typem obiektów ,który poznasz, są obiekty drzew (ang. tree), które rozwiązują problem przechowywania nazw plików oraz pozwalają na przechowywanie grupy plików razem. Git przechowuje treść w sposób podobny do systemu plików UNIX, lecz z pewnymi uproszczeniami. Wszystkie dane przechowywane są jako obiekty "tree" i "blob", z obiektami "tree" odpowiadającymi strukturze katalogów w systemie UNIX, oraz obiektami "blob", które w mniejszym lub większym stopniu odpowiadają i-węzłom lub treści plików. Pojedynczy obiekt "tree" zawiera jeden lub więcej wpisów dotyczących ścieżki, z których każdy zawiera skrót SHA-1 wskazujący na obiekt "blob" lub poddrzewem (ang. subtree) z przypisanym trybem, typem i nazwą pliku. Na przykład, najnowsze drzewo w projekcie może wygląda tak:
$ git cat-file -p master^{tree}
100644 blob a906cb2a4a904a152e80877d4088654daad0c859 README
100644 blob 8f94139338f9404f26296befa88755fc2598c289 Rakefile
040000 tree 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0 libSkładnia master^{tree} wskazuje na obiekt tree na który wskazuje ostatni commit w Twojej gałęzi master.
Zauważ, że podkatalog lib nie jest blobem, ale wskaźnikiem na inny obiekt tree.
$ git cat-file -p 99f1a6d12cb4b6f19c8655fca46c3ecf317074e0
100644 blob 47c6340d6459e05787f644c2447d2595f5d3a54b simplegit.rbW ogólnym zarysie, dane, które przechowuje Git , wyglądają podobnie do tych pokazanych poniżej:
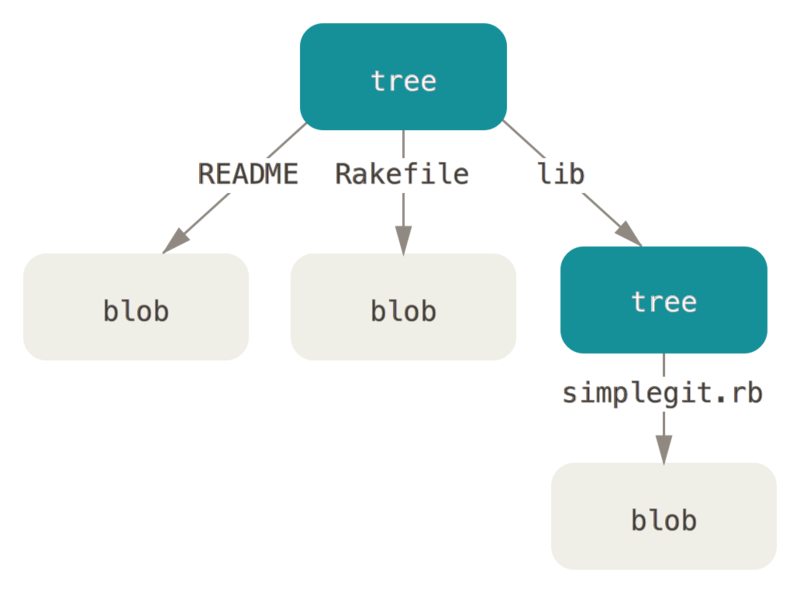
Możesz stworzyć swój własny obiekt tree.
Git zazwyczaj tworzy taki obiekt poprzez pobranie stanu przechowalni lub indeksu i zapisanie obiektu tree z tych danych.
A więc, aby stworzyć obiekt tree, na początek musisz ustawić indeks poprzez dodanie do przechowalni plików.
Indeks z jednym elementem – z pierwszą wersją Twojego pliku test.txt – możesz stworzyć używając komendy update-index.
Możesz jej również do sztucznego dodania poprzedniej wersji pliku test.txt do przechowalni.
Musisz podać jej opcje --add ponieważ plik nie istnieje jeszcze w przechowalni (nie masz jeszcze nawet ustawionej przechowalni) oraz --cacheinfo ponieważ plik który dodajesz nie istnieje w katalogu, a tylko w bazie danych.
Następnie wskazujesz tryb, sumę SHA-1 oraz nazwę pliku:
$ git update-index --add --cacheinfo 100644 \
83baae61804e65cc73a7201a7252750c76066a30 test.txtW tym przykładzie, podałeś tryb 100644, który wskazuje na normalny plik.
Inne dostępne tryby to 100755, który wskazuje na plik wykonywalny; oraz 120000, który wskazuje na dowiązanie symboliczne.
Tryby bazują na normalnych uprawnieniach w systemie UNIX, ale mają znacznie mniej opcji – te trzy tryby są jedynymi, które mogą być stosowane do plików (blob-ów) w Gitcie (chociaż inne tryby mogą być użyte dla katalogów i podmodułów).
Teraz, możesz użyć komendy write-tree, w celu zapisania zawartości przechowani do obiektu tree.
Opcja -w nie jest potrzebna – wywołanie write-tree automatycznie tworzy obiekt tree ze stanu indeksu, jeżeli ten obiekt jeszcze nie istnieje.
$ git write-tree
d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git cat-file -p d8329fc1cc938780ffdd9f94e0d364e0ea74f579
100644 blob 83baae61804e65cc73a7201a7252750c76066a30 test.txtMożesz również zweryfikować, że to jest obiekt tree:
$ git cat-file -t d8329fc1cc938780ffdd9f94e0d364e0ea74f579
treeStworzysz teraz nowy obiekt tree, zawierający drugą wersję pliku test.txt oraz nowy plik:
$ echo 'new file' > new.txt
$ git update-index test.txt
$ git update-index --add new.txtW Twojej przechowalni znajduje się teraz nowa wersja pliku test.txt oraz nowy plik new.txt. Zapisz ten stan (pobierając stan z przechowalni lub indeksu do obiektu tree) i sprawdź jak on teraz wygląda:
$ git write-tree
0155eb4229851634a0f03eb265b69f5a2d56f341
$ git cat-file -p 0155eb4229851634a0f03eb265b69f5a2d56f341
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtZauważ, że to drzewo posiada oba wpisy dotyczące plików, oraz że suma SHA w pliku test.txt jest sumą przypisaną do "wersji 2" (1f7a7a).
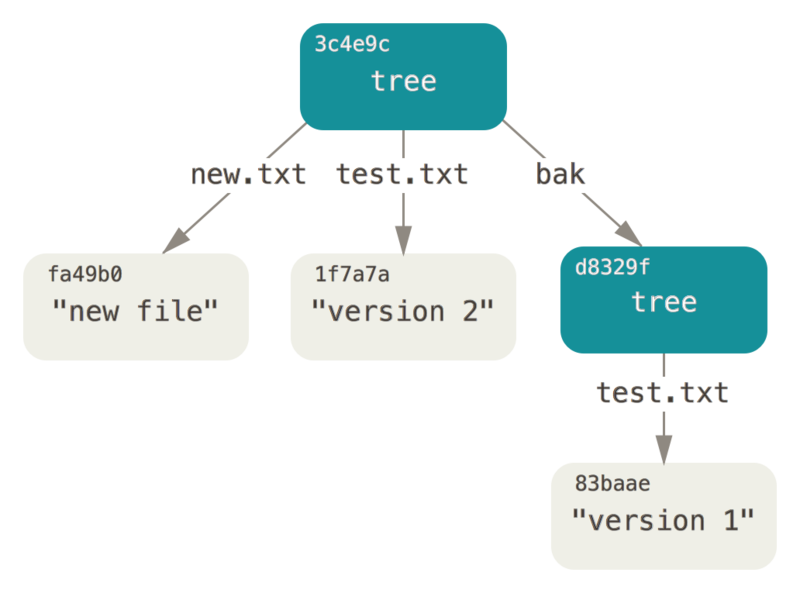
Dla zabawy, dodasz pierwszy obiekt tree jako podkatalog w obecnym.
Możesz wczytać obiekt tree do swojej przechowalni poprzez wywołanie read-tree.
W takim wypadku, możesz wczytać obecne drzewo do swojej przechowalni i umieścić je w podkatalogu za pomocą opcji --prefix dodanej do read-tree:
$ git read-tree --prefix=bak d8329fc1cc938780ffdd9f94e0d364e0ea74f579
$ git write-tree
3c4e9cd789d88d8d89c1073707c3585e41b0e614
$ git cat-file -p 3c4e9cd789d88d8d89c1073707c3585e41b0e614
040000 tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579 bak
100644 blob fa49b077972391ad58037050f2a75f74e3671e92 new.txt
100644 blob 1f7a7a472abf3dd9643fd615f6da379c4acb3e3a test.txtJeżeli odtworzyłeś katalog roboczy z drzewa które właśnie zapisałeś, otrzymałeś dwa pliki na najwyższym poziomie w tym katalogu, oraz podkatalog bak, który zawiera pierwszą wersję pliku test.txt.
Możesz myśleć o danych przechowywanych w Gitcie z tymi strukturami, tak jak przedstawiono to poniżej:
Obiekty commit
Masz teraz trzy obiekty tree, które wskazują na różne migawki śledzonego projektu, ale poprzedni problem pozostał: musisz pamiętasz wszystkie trzy wartości SHA-1 aby przywrócić migawkę. Nie masz również żadnych informacji o tym kto zapisał migawkę, kiedy była zapisana, ani dlaczego. To są podstawowe informacje, które przechowywane są w obiektach typu commit.
Aby stworzyć obiekt commit, wywołaj commit-tree i podaj jedną sumę SHA-1 wskazującą na obiekt tree oraz obiekty commit, o ile były jakieś, które bezpośrednio go poprzedziły.
Zacznij od pierwszego obiektu tree, który napisałeś:
$ echo 'first commit' | git commit-tree d8329f
fdf4fc3344e67ab068f836878b6c4951e3b15f3dMożesz teraz zobaczyć jak wygląda nowy obiekt commit za pomocą cat-file:
$ git cat-file -p fdf4fc3
tree d8329fc1cc938780ffdd9f94e0d364e0ea74f579
author Scott Chacon <schacon@gmail.com> 1243040974 -0700
committer Scott Chacon <schacon@gmail.com> 1243040974 -0700
first commitFormat obiektu commit jest prosty: wskazuje on najnowszy obiekt tree dla migawki projektu w momencie tworzenia; informacje o autorze/integratorze zmiany pobrane z są ustawień konfiguracyjnych user.name i user.email wraz z obecnym znacznikiem czasu; pustą linię i potem treść komentarza do zmiany.
Następnie, zapiszesz dwa inne obiekty commit, z których każdy odwołuje się do commit-a który był bezpośrednio przed nim:
$ echo 'second commit' | git commit-tree 0155eb -p fdf4fc3
cac0cab538b970a37ea1e769cbbde608743bc96d
$ echo 'third commit' | git commit-tree 3c4e9c -p cac0cab
1a410efbd13591db07496601ebc7a059dd55cfe9Każdy z trzech obiektów commit wskazuje na jedną z trzech migawek które stworzyłeś.
Co ciekawe, masz teraz prawdziwą historię w Git, którą możesz obejrzeć za pomocą komendy git log, jeżeli uruchomisz ją na ostatniej sumą SHA-1 obiektu commit:
$ git log --stat 1a410e
commit 1a410efbd13591db07496601ebc7a059dd55cfe9
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:15:24 2009 -0700
third commit
bak/test.txt | 1 +
1 file changed, 1 insertion(+)
commit cac0cab538b970a37ea1e769cbbde608743bc96d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:14:29 2009 -0700
second commit
new.txt | 1 +
test.txt | 2 +-
2 files changed, 2 insertions(+), 1 deletion(-)
commit fdf4fc3344e67ab068f836878b6c4951e3b15f3d
Author: Scott Chacon <schacon@gmail.com>
Date: Fri May 22 18:09:34 2009 -0700
first commit
test.txt | 1 +
1 file changed, 1 insertion(+)Niesamowite.
Wykonałeś właśnie niskopoziomowe operacje i stworzyłeś historię w Git bez używania żadnej z komend użytkownika.
Jest to w zasadzie to, co Git robi kiedy uruchomisz komendy git add oraz git commit – zapisuje obiekty blob dla plików które zmieniłeś, aktualizuje indeks, zapisuje obiekt tree, oraz tworzy obiekt commit odnoszący się do obiektu tree oraz obiektów commit które wystąpiły bezpośrednio przed nim.
Te trzy główne obiekty Gita – blob, tree oraz commit – są na początku zapisywane jako pojedyncze pliki w katalogu .git/objects.
Poniżej widać wszystkie obiekty z naszego przykładu, z komentarzami wskazującymi na to co było w nich zapisane:
$ find .git/objects -type f
.git/objects/01/55eb4229851634a0f03eb265b69f5a2d56f341 # tree 2
.git/objects/1a/410efbd13591db07496601ebc7a059dd55cfe9 # commit 3
.git/objects/1f/7a7a472abf3dd9643fd615f6da379c4acb3e3a # test.txt v2
.git/objects/3c/4e9cd789d88d8d89c1073707c3585e41b0e614 # tree 3
.git/objects/83/baae61804e65cc73a7201a7252750c76066a30 # test.txt v1
.git/objects/ca/c0cab538b970a37ea1e769cbbde608743bc96d # commit 2
.git/objects/d6/70460b4b4aece5915caf5c68d12f560a9fe3e4 # 'test content'
.git/objects/d8/329fc1cc938780ffdd9f94e0d364e0ea74f579 # tree 1
.git/objects/fa/49b077972391ad58037050f2a75f74e3671e92 # new.txt
.git/objects/fd/f4fc3344e67ab068f836878b6c4951e3b15f3d # commit 1Jeżeli prześledzisz wszystkie wskaźniki, dostaniesz widok obiektów podobny do poniższego:
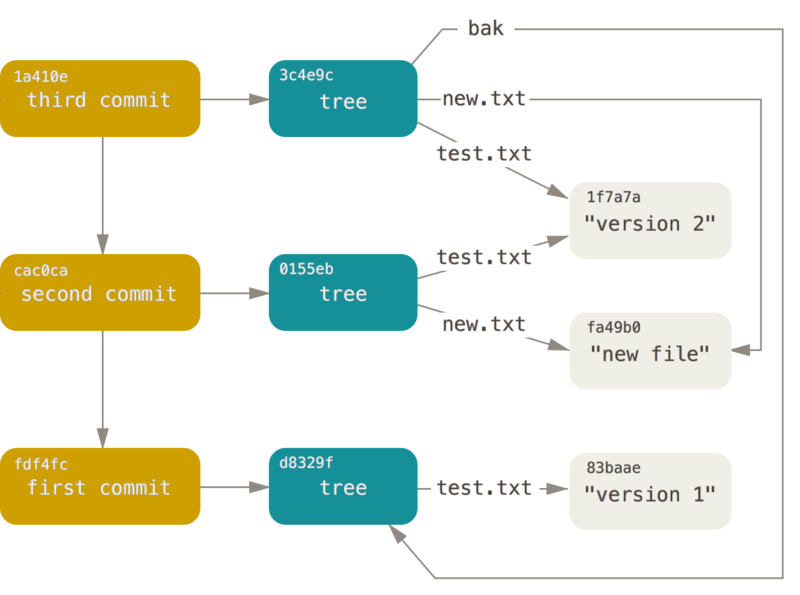
Przechowywanie obiektów
Wspomnieliśmy wcześniej, że nagłówek jest zapisywany wraz z treścią. Spójrzmy przez chwilę w jaki sposób Git zapisuje swoje obiekty. Zobaczysz jak zapisać obiekt blob – na przykładzie treści "what is up, doc?" – interaktywnie w języku skryptowym Ruby.
Możesz uruchomić tryb interaktywny w Rubym, za pomocą komendy irb:
$ irb
>> content = "what is up, doc?"
=> "what is up, doc?"Git tworząc nagłówek na początku wskazuje jakiego typu jest obiekt, w tym wypadku blob. Następnie, dodaje spację i wielkość treści, oraz na końcu pusty znak (null):
>> header = "blob #{content.length}\0"
=> "blob 16\u0000"Git łączy nagłówek z treścią, a potem oblicza sumę SHA-1 całości.
Możesz obliczyć sumę SHA-1 dla treści w Ruby, po włączeniu biblioteki "SHA1 digest" za pomocą komendy require, oraz po wywołaniu Digest::SHA1.hexdigest() na nim:
>> store = header + content
=> "blob 16\u0000what is up, doc?"
>> require 'digest/sha1'
=> true
>> sha1 = Digest::SHA1.hexdigest(store)
=> "bd9dbf5aae1a3862dd1526723246b20206e5fc37"Git kompresuje nową treść za pomocą zlib, co możesz wykonać w Ruby przy użyciu biblioteki zlib.
Najpierw, musisz dodać wpis require, a potem uruchomić na treści Zlib::Deflate.deflate():
>> require 'zlib'
=> true
>> zlib_content = Zlib::Deflate.deflate(store)
=> "x\x9CK\xCA\xC9OR04c(\xCFH,Q\xC8,V(-\xD0QH\xC9O\xB6\a\x00_\x1C\a\x9D"Na koniec, zapiszesz spakowaną treść jako obiektu na dysku.
Ustalisz ścieżkę dla obiektu który zapisujesz (pierwsze dwa znaki z sumy SHA-1 są nazwą podkatalogu, a pozostałe 38 znaków są nazwą pliku w tym katalogu).
W Ruby możesz użyć funkcji FileUtils.mkdir_p(), aby stworzyć podkatalog w przypadku gdy on nie istnieje.
Następnie otwórz plik za pomocą File.open() i zapisz otrzymaną skompresowaną zawartość do pliku za pomocą funkcji write() wywołanej na otrzymanym uchwycie pliku:
>> path = '.git/objects/' + sha1[0,2] + '/' + sha1[2,38]
=> ".git/objects/bd/9dbf5aae1a3862dd1526723246b20206e5fc37"
>> require 'fileutils'
=> true
>> FileUtils.mkdir_p(File.dirname(path))
=> ".git/objects/bd"
>> File.open(path, 'w') { |f| f.write zlib_content }
=> 32To tyle – stworzyłeś poprawny obiekt blog w Gitcie. Wszystkie obiekty w Git przechowywane są w taki sam sposób, tylko z innymi typami – zamiast ciągu znaków blob, nagłówek będzie rozpoczynał się od commit lub tree. Choć obiekt blob może zawierać praktycznie dowolne dane, to jednak obiekty commit i tree są bardzo specyficznie sformatowane.