
-
1. Pierwsze kroki
- 1.1 Wprowadzenie do kontroli wersji
- 1.2 Krótka historia Git
- 1.3 Podstawy Git
- 1.4 Linia poleceń
- 1.5 Instalacja Git
- 1.6 Wstępna konfiguracja Git
- 1.7 Uzyskiwanie pomocy
- 1.8 Podsumowanie
-
2. Podstawy Gita
- 2.1 Pierwsze repozytorium Gita
- 2.2 Rejestrowanie zmian w repozytorium
- 2.3 Podgląd historii rewizji
- 2.4 Cofanie zmian
- 2.5 Praca ze zdalnym repozytorium
- 2.6 Tagowanie
- 2.7 Aliasy
- 2.8 Podsumowanie
-
3. Gałęzie Gita
- 3.1 Czym jest gałąź
- 3.2 Podstawy rozgałęziania i scalania
- 3.3 Zarządzanie gałęziami
- 3.4 Sposoby pracy z gałęziami
- 3.5 Gałęzie zdalne
- 3.6 Zmiana bazy
- 3.7 Podsumowanie
-
4. Git na serwerze
- 4.1 Protokoły
- 4.2 Uruchomienie Git na serwerze
- 4.3 Generowanie Twojego publicznego klucza SSH
- 4.4 Konfigurowanie serwera
- 4.5 Git Daemon
- 4.6 Smart HTTP
- 4.7 GitWeb
- 4.8 GitLab
- 4.9 Inne opcje hostowania przez podmioty zewnętrzne
- 4.10 Podsumowanie
-
5. Rozproszony Git
-
6. GitHub
-
7. Narzędzia Gita
- 7.1 Wskazywanie rewizji
- 7.2 Interaktywne używanie przechowali
- 7.3 Schowek i czyszczenie
- 7.4 Signing Your Work
- 7.5 Searching
- 7.6 Przepisywanie historii
- 7.7 Reset Demystified
- 7.8 Advanced Merging
- 7.9 Rerere
- 7.10 Debugowanie z Gitem
- 7.11 Moduły zależne
- 7.12 Bundling
- 7.13 Replace
- 7.14 Credential Storage
- 7.15 Podsumowanie
-
8. Dostosowywanie Gita
- 8.1 Konfiguracja Gita
- 8.2 Git Attributes
- 8.3 Git Hooks
- 8.4 An Example Git-Enforced Policy
- 8.5 Summary
-
9. Git i inne systemy
- 9.1 Git jako klient
- 9.2 Migracja do Gita
- 9.3 Podsumowanie
-
10. Mechanizmy wewnętrzne w Git
- 10.1 Komendy typu plumbing i porcelain
- 10.2 Obiekty Gita
- 10.3 Referencje w Git
- 10.4 Spakowane pliki (packfiles)
- 10.5 Refspec
- 10.6 Protokoły transferu
- 10.7 Konserwacja i odzyskiwanie danych
- 10.8 Environment Variables
- 10.9 Podsumowanie
-
A1. Appendix A: Git in Other Environments
- A1.1 Graphical Interfaces
- A1.2 Git in Visual Studio
- A1.3 Git in Eclipse
- A1.4 Git in Bash
- A1.5 Git in Zsh
- A1.6 Git in Powershell
- A1.7 Summary
-
A2. Appendix B: Embedding Git in your Applications
- A2.1 Command-line Git
- A2.2 Libgit2
- A2.3 JGit
-
A3. Appendix C: Git Commands
- A3.1 Setup and Config
- A3.2 Getting and Creating Projects
- A3.3 Basic Snapshotting
- A3.4 Branching and Merging
- A3.5 Sharing and Updating Projects
- A3.6 Inspection and Comparison
- A3.7 Debugging
- A3.8 Patching
- A3.9 Email
- A3.10 External Systems
- A3.11 Administration
- A3.12 Plumbing Commands
3.6 Gałęzie Gita - Zmiana bazy
Zmiana bazy
W Git istnieją dwa podstawowe sposoby integrowania zmian z jednej gałęzi do drugiej: scalanie (polecenie merge) oraz zmiana bazy (polecenie rebase).
W tym rozdziale dowiesz się, czym jest zmiana bazy, jak ją przeprowadzić, dlaczego jest to świetne narzędzie i w jakich przypadkach lepiej się powstrzymać od jego wykorzystania.
Typowa zmiana bazy
Jeśli cofniesz się do poprzedniego przykładu z sekcji Podstawy scalania, zobaczysz, że rozszczepiłeś swoją pracę i wykonywałeś zmiany w dwóch różnych gałęziach.
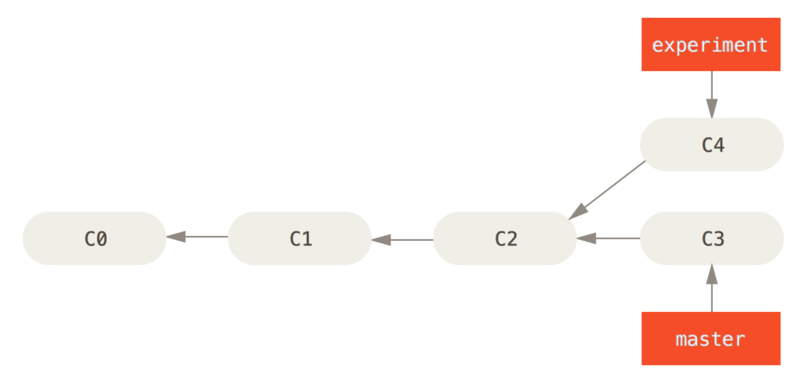
Najprostszym sposobem, aby zintegrować gałęzie - jak już napisaliśmy - jest polecenie merge. Przeprowadza ono trójstronne scalanie pomiędzy dwoma ostatnimi migawkami gałęzi (C3 i C4) oraz ich ostatnim wspólnym przodkiem (C2), tworząc nową migawkę (oraz rewizję).
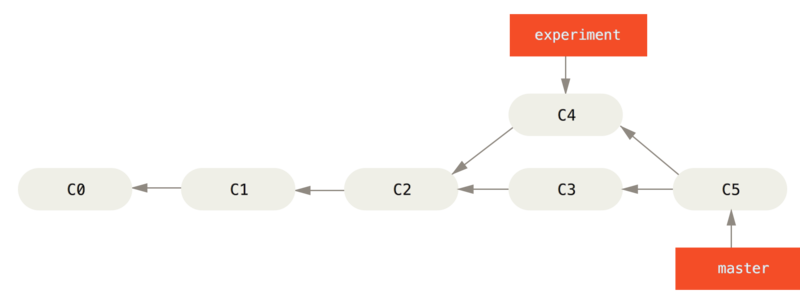
Jednakże istnieje inny sposób: możesz stworzyć łatkę ze zmianami wprowadzonymi w C4 i zaaplikować ją na rewizję C3. W Gicie nazywa się to zmianą bazy (ang. rebase). Dzięki poleceniu rebase możesz wziąć wszystkie zmiany, które zostały zatwierdzone w jednej gałęzi i zaaplikować je w innej.
W tym wypadku, mógłbyś uruchomić następujące polecenie:
$ git checkout experiment
$ git rebase master
First, rewinding head to replay your work on top of it...
Applying: added staged commandPolecenie to działa przesuwając się do ostatniego wspólnego przodka obu gałęzi (tej w której się znajdujesz oraz tej do której robisz zmianę bazy), pobierając różnice opisujące kolejne zmiany (ang. diffs) wprowadzane przez kolejne rewizje w gałęzi w której się znajdujesz, zapisując je w tymczasowych plikach, następnie resetuje bieżącą gałąź do tej samej rewizji do której wykonujesz operację zmiany bazy, po czym aplikuje po kolei zapisane zmiany.
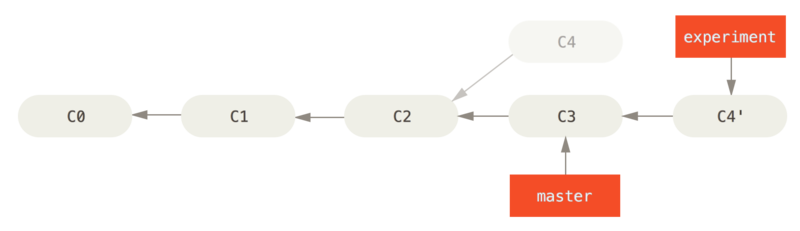
C4 do C3.W tym momencie możesz wrócić do gałęzi master i scalić zmiany wykonując proste przesunięcie wskaźnika (co przesunie wskaźnik master na koniec).
$ git checkout master
$ git merge experiment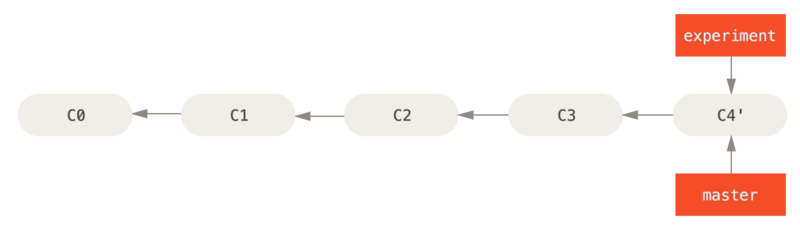
Teraz migawka wskazywana przez C4' jest dokładnie taka sama jak ta, na którą wskazuje C5 w przykładzie ze scalaniem.
Nie ma różnicy w produkcie końcowym integracji. Zmiana bazy tworzy jednak czystszą historię.
Jeśli przejrzysz historię gałęzi po operacji rebase, wygląda ona na liniową: wygląda jakby cała praca była wykonywana stopniowo, nawet jeśli oryginalnie odbywała się równolegle.
Warto korzystać z tej funkcji, by mieć pewność, że rewizje zaaplikują się w bezproblemowy sposób do zdalnej gałęzi – być może w projekcie w którym próbujesz się udzielać, a którym nie zarządzasz.
W takim wypadku będziesz wykonywał swoją pracę we własnej gałęzi, a następnie zmieniał jej bazę na origin/master, jak tylko będziesz gotowy do przesłania własnych poprawek do głównego projektu.
W ten sposób osoba utrzymująca projekt nie będzie musiała dodatkowo wykonywać integracji – jedynie prostolinijne scalenie lub czyste zastosowanie zmian.
Zauważ, że migawka wskazywana przez wynikową rewizję bez względu na to, czy jest to ostatnia rewizja po zmianie bazy lub ostatnia rewizja scalająca po operacji scalania, to taka sama migawka – różnica istnieje jedynie w historii. Zmiana bazy nanosi zmiany z jednej linii pracy do innej w kolejności, w jakiej były one wprowadzane, w odróżnieniu od scalania, które bierze dwie końcówki i integruje je ze sobą.
Ciekawsze operacje zmiany bazy
Poleceniem rebase możesz także zastosować zmiany na innej gałęzi niż ta, której zmieniasz bazę
Dla przykładu – weź historię taką jak w przykładzie Historia z gałęzią tematyczną utworzoną na podstawie innej gałęzi tematycznej..
Utworzyłeś gałąź tematyczną (server), żeby dodać nowe funkcje do kodu serwerowego, po czym utworzyłeś rewizję.
Następnie utworzyłeś gałąź, żeby wykonać zmiany w kliencie (client) i kilkukrotnie zatwierdziłeś zmiany.
Ostatecznie wróciłeś do gałęzi server i wykonałeś kilka kolejnych rewizji.
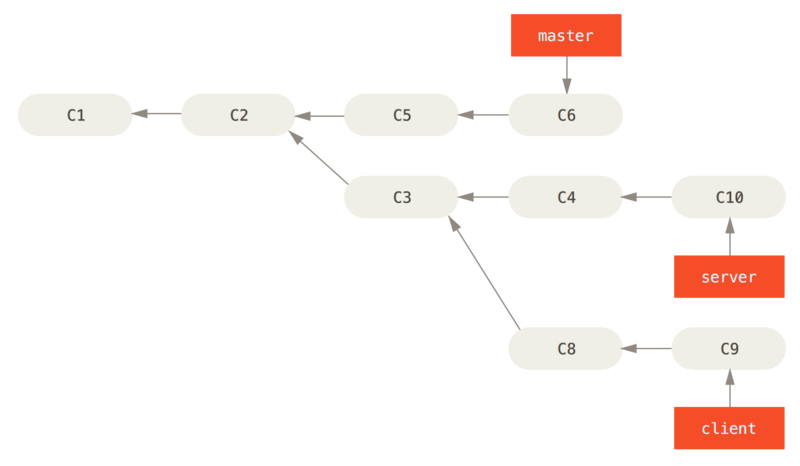
Załóżmy, że zdecydowałeś się scalić zmiany w kliencie do kodu głównego, ale chcesz się jeszcze wstrzymać ze zmianami po stronie serwera, dopóki nie zostaną one dokładniej przetestowane.
Możesz wziąć zmiany w kodzie klienta, których nie ma w kodzie serwera (C8 i C9) i zastosować je na gałęzi głównej używając opcji --onto polecenia git rebase:
$ git rebase --onto master server clientOznacza to mniej więcej "Przełącz się do gałęzi klienta, określ zmiany wprowadzone od wspólnego przodka gałęzi client i server, a następnie nanieś te zmiany na gałąź główną master".
Jest to nieco skomplikowane, ale wynik jest całkiem niezły.
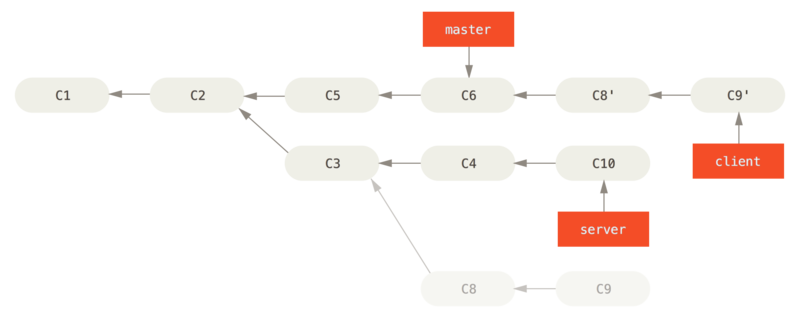
Teraz możesz zwyczajnie przesunąć wskaźnik gałęzi głównej do przodu (por. Przesunięcie do przodu gałęzi master w celu uwzględnienia zmian z gałęzi client):
$ git checkout master
$ git merge client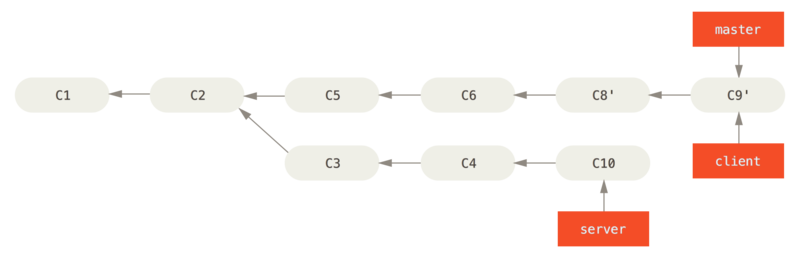
Powiedzmy, że zdecydujesz się pobrać i scalić zmiany z gałęzi server.
Możesz zmienić bazę gałęzi server na wskazywaną przez master bez konieczności przełączania się do gałęzi server używając git rebase [gałąź bazowa] [gałąź tematyczna] – w ten sposób zmiany z gałęzi server zostaną zaaplikowane do gałęzi bazowej master:
$ git rebase master serverPolecenie odtwarza zmiany z gałęzi server na gałęzi master tak, jak pokazuje to Zmiana bazy gałęzi server na koniec gałęzi master.

server na koniec gałęzi master
Następnie możesz przesunąć gałąź bazową (master):
$ git checkout master
$ git merge serverMożesz teraz usunąć gałęzie client i server, ponieważ cała praca jest już zintegrowana i więcej ich nie potrzebujesz, pozostawiając historię w stanie takim, jaki obrazuje Ostateczna historia rewizji:
$ git branch -d client
$ git branch -d server
Zagrożenia operacji zmiany bazy
Błogosławieństwo, jakie daje możliwość zmiany bazy, ma swoją mroczną stronę. Można ją podsumować jednym zdaniem:
Nie zmieniaj bazy rewizji, które wypchnąłeś już do publicznego repozytorium.
Jeśli będziesz się stosował do tej reguły, wszystko będzie dobrze. W przeciwnym razie ludzie cię znienawidzą, a rodzina i przyjaciele zaczną omijać szerokim łukiem.
Stosując operację zmiany bazy porzucasz istniejące rewizje i tworzysz nowe, które są podobne, ale inne.
Wypychasz gdzieś swoje zmiany, inni je pobierają, scalają i pracują na nich, a następnie nadpisujesz te zmiany poleceniem git rebase i wypychasz ponownie na serwer. Twoi współpracownicy będą musieli scalić swoją pracę raz jeszcze i zrobi się bałagan, kiedy spróbujesz pobrać i scalić ich zmiany z powrotem z twoimi.
Spójrzmy na przykład obrazujący, jak operacja zmiany bazy może spowodować problemy. Załóżmy, że sklonujesz repozytorium z centralnego serwera, a następnie wykonasz bazując na tym nowe zmiany. Twoja historia rewizji wygląda następująco:
Teraz ktoś inny wykonuje inną pracę, która obejmuje scalenie, i wypycha ją na centralny serwer. Pobierasz zmiany, scalasz nową, zdalną gałąź z własną pracą, w wyniku czego historia wygląda mniej więcej tak:
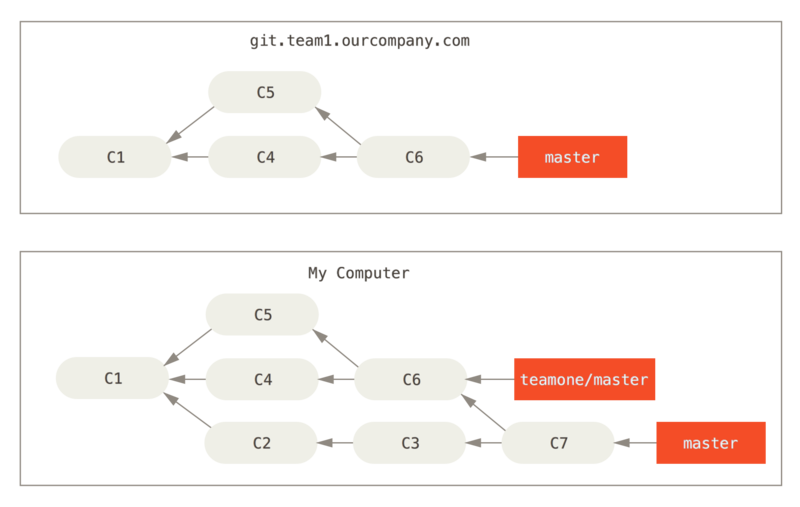
Następnie osoba, która wypchnęła scalone zmiany, rozmyśliła się i zdecydowała zamiast scalenia zmienić bazę swoich zmian; wykonuje git push --force, żeby zastąpić historię na serwerze.
Następnie ty pobierasz dane z serwera ściągając nowe rewizje.
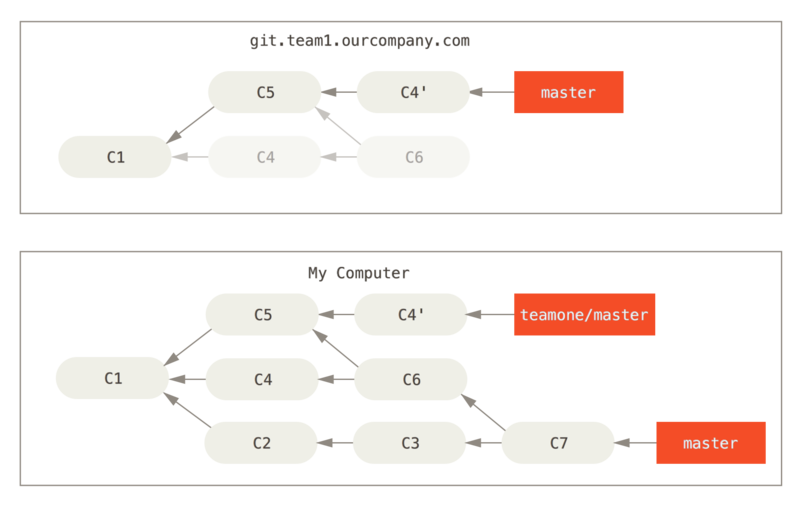
Teraz obaj znaleźliście się w trudnej sytuacji.
Jeśli wykonasz git pull, utworzysz rewizję scalającą, która będzie zawierała obie linie historii, a twoje repozytorium będzie wyglądało tak:
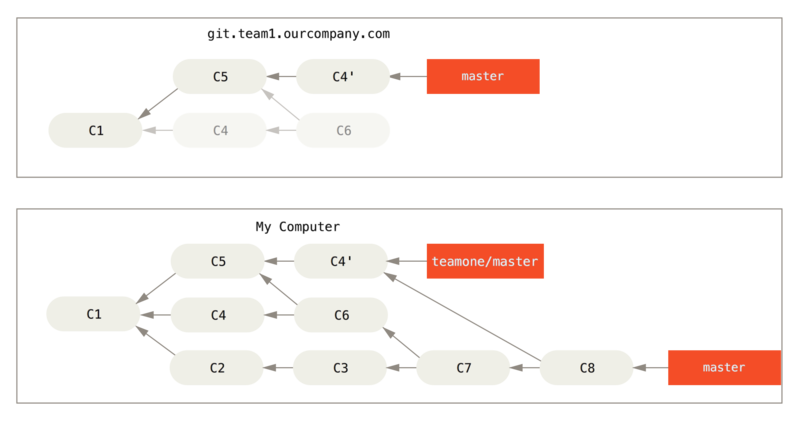
Jeśli uruchomisz git log dla takiej historii, zobaczysz dwie rewizje mające tego samego autora, datę oraz komentarz, co będzie mylące.
Co więcej, jeśli wypchniesz tę historię z powrotem na serwer, raz jeszcze wprowadzisz wszystkie rewizje powstałe w wyniku operacji zmiany bazy na serwer centralny, co może dalej mylić i denerwować ludzi.
Można bezpiecznie przyjąć, że drugi deweloper nie chce, aby C4 i C6 były w historii; z tego właśnie powodu w pierwszej kolejności dokonał zmiany bazy.
Rebase When You Rebase
If you do find yourself in a situation like this, Git has some further magic that might help you out. If someone on your team force pushes changes that overwrite work that you’ve based work on, your challenge is to figure out what is yours and what they’ve rewritten.
It turns out that in addition to the commit SHA-1 checksum, Git also calculates a checksum that is based just on the patch introduced with the commit. This is called a “patch-id”.
If you pull down work that was rewritten and rebase it on top of the new commits from your partner, Git can often successfully figure out what is uniquely yours and apply them back on top of the new branch.
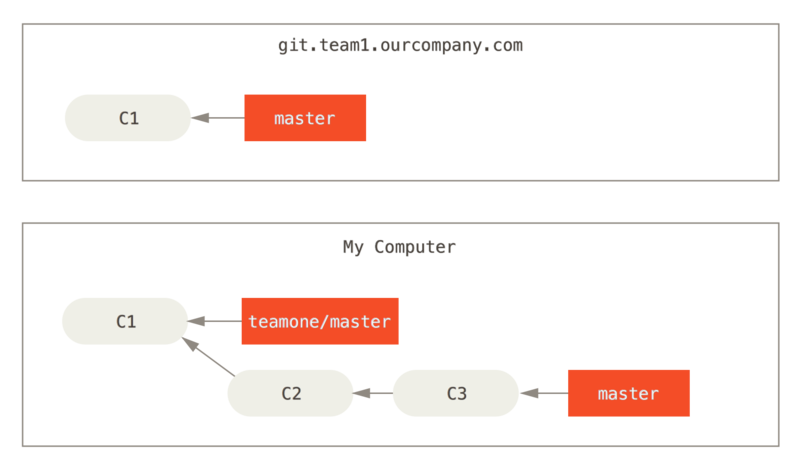
For instance, in the previous scenario, if instead of doing a merge when we’re at Ktoś wypycha rewizje po operacji zmiany bazy, porzucając rewizje, na których ty oparłeś swoje zmiany we run git rebase teamone/master, Git will:
-
Determine what work is unique to our branch (C2, C3, C4, C6, C7)
-
Determine which are not merge commits (C2, C3, C4)
-
Determine which have not been rewritten into the target branch (just C2 and C3, since C4 is the same patch as C4')
-
Apply those commits to the top of
teamone/master
So instead of the result we see in Scalasz tą samą pracę raz jeszcze tworząc nową rewizję scalającą, we would end up with something more like Rebase on top of force-pushed rebase work..
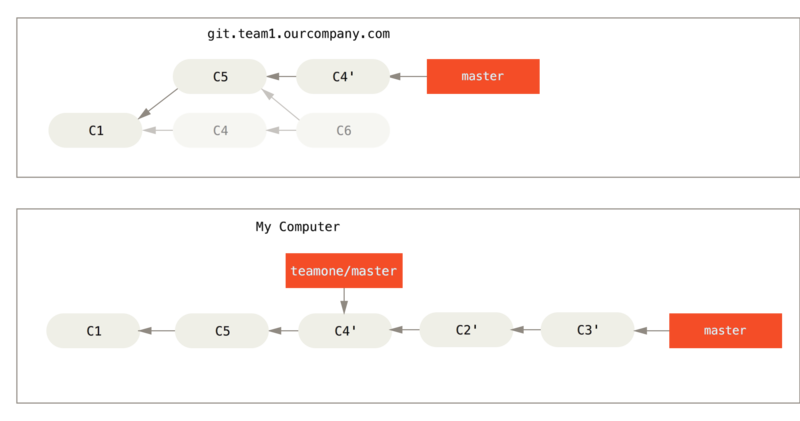
This only works if C4 and C4' that your partner made are almost exactly the same patch. Otherwise the rebase won’t be able to tell that it’s a duplicate and will add another C4-like patch (which will probably fail to apply cleanly, since the changes would already be at least somewhat there).
You can also simplify this by running a git pull --rebase instead of a normal git pull. Or you could do it manually with a git fetch followed by a git rebase teamone/master in this case.
If you are using git pull and want to make --rebase the default, you can set the pull.rebase config value with something like git config --global pull.rebase true.
If you treat rebasing as a way to clean up and work with commits before you push them, and if you only rebase commits that have never been available publicly, then you’ll be fine. If you rebase commits that have already been pushed publicly, and people may have based work on those commits, then you may be in for some frustrating trouble, and the scorn of your teammates.
If you or a partner does find it necessary at some point, make sure everyone knows to run git pull --rebase to try to make the pain after it happens a little bit simpler.
Rebase vs. Merge
Now that you’ve seen rebasing and merging in action, you may be wondering which one is better. Before we can answer this, let’s step back a bit and talk about what history means.
One point of view on this is that your repository’s commit history is a record of what actually happened. It’s a historical document, valuable in its own right, and shouldn’t be tampered with. From this angle, changing the commit history is almost blasphemous; you’re lying about what actually transpired. So what if there was a messy series of merge commits? That’s how it happened, and the repository should preserve that for posterity.
The opposing point of view is that the commit history is the story of how your project was made. You wouldn’t publish the first draft of a book, and the manual for how to maintain your software deserves careful editing. This is the camp that uses tools like rebase and filter-branch to tell the story in the way that’s best for future readers.
Now, to the question of whether merging or rebasing is better: hopefully you’ll see that it’s not that simple. Git is a powerful tool, and allows you to do many things to and with your history, but every team and every project is different. Now that you know how both of these things work, it’s up to you to decide which one is best for your particular situation.
In general the way to get the best of both worlds is to rebase local changes you’ve made but haven’t shared yet before you push them in order to clean up your story, but never rebase anything you’ve pushed somewhere.